










一、文章概况
文章题目:《Dynamic Fusion with Intra- and Inter-modality Attention Flow for Visual Question Answering》
这篇文章是CVPR2019的文章,作者主要来自港中文。
文章引用格式:P. Gao, Z. Jiang, H. You, P. Lu, S. Hoi, X. Wang, H. Li. "Dynamic Fusion with Intra- and Inter-modality Attention Flow for Visual Question Answering." In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2019
项目地址:暂时没有
二、文章导读
先看下文章的摘要部分:
Learning effective fusion of multi-modality features is at the heart of visual question answering. We propose a novel method of dynamically fusing multi-modal features with intra- and inter-modality information flow, which alternatively pass dynamic information between and across the visual and language modalities. It can robustly capture the high-level interactions between language and vision domains, thus significantly improves the performance of visual question answering. We also show that the proposed dynamic intra-modality attention flow conditioned on the other modality can dynamically modulate the intramodality attention of the target modality, which is vital for multimodality feature fusion. Experimental evaluations on the VQA 2.0 dataset show that the proposed method achieves state-of-the-art VQA performance. Extensive ablation studies are carried out for the comprehensive analysis of the proposed method.
多模态特征的有效融合是VQA问题的一个热点。作者提出了一种利用外部和内部模态信息流(在视觉和语言模态中动态传递信息)的多模态特征融合方法。它能够捕捉视觉域和语言域之间的高层次信息,因此能够有效提高VQA的结果。另外该模型也能够适用于有一定条件约束的其他模态融合,实验评价是基于VQA2.0数据集,结果表明该模型达到了state-of-the-art最好的效果。
三、文章精读
近些年来VQA的性能在不断提高,得益于三方面的发展:一,更好的语言特征表示和视觉特征表示,视觉特征比如从VGG到ResNet再到bottom-up & top-down;二、attention机制的变种能够自适应的选择特征;三、更好的多模态融合方法,比如双线性融合Bilinear Fusion,MCB和MUTAN。
目前的VQA发展主要是两个方面。一是关注模态间的关系,比如双线性特征融合(Bilinear feature fusion),协同注意力(co-attention);二是关注模态内部的关系,比如BERT处理NLP。然而,模态内和模态间的研究,并没有一个框架在VQA问题中结合起来,作者指出,模态内的关系是模态间关系的进一步补充,但这是被大部分VQA模型忽略的。因此作者提出了一个流程DFAF(Dynamic Fusion with Intra- and Inter-modality Attention Flow)来充分利用模态特征融合以提高VQA精度。模型结构如下图所示:

DFAF整合了交叉模态自注意力(cross-modal self-attention)和交叉模态协同注意力(cross-modal co-attention)。首先是用深度网络编码视觉特征和问题特征,生成模态间的注意力流(intermodality attention flow (InterMAF)),在模块InterMAF中,视觉特征和语言特征生成联合模态的协同注意力矩阵(joint-modality co-attention matrix),根据这个矩阵,每个视觉区域都可以选择一个问题特征,之后对视觉区域和单词特征进行更新和融合。在模块InterMAF后,计算动态模态内注意力流(dynamic intra-modality attention flow,DyIntraMAF),在同一种模态中,视觉区域和单词生成自注意力权重,并且合并权重信息。尽管这些信息只在同一模态中传递,其他模态的信息则能够调整模态内的权重和流。DyIntraMAF模块的实验表明,它比仅仅使用模态内的信息和流的表现更好,也是流程中的关键,DFAF流程主要由InterMAF和DyIntraMAF模块组成,多重堆叠的DFAF能够提高VQA的表现。
作者的主要贡献有以下三个:
·A novel Dynamic Fusion with Intra- and Inter-modality Attention Flow (DFAF) framework is proposed for multimodality fusion by interleaving intra- and inter-modality feature fusion. Such a framework for the first time integrates inter-modality and dynamic intra-modality information flow in a unified framework for tackling the VQA task. (提出了DFAF框架用于多模态融合)
·Dynamic Intra-modality Attention Flow (DyIntraMAF) module is proposed for generating effective attention flows within each modality, which are dynamically conditioned on the information of the other modality. It is one of the core novelties of our proposed framework.(提出DyIntraMAF模块,在每一个模态内生成有效的注意力流)
·Extensive experiments and ablation studies are performed to examine the effectiveness of the proposed DFAF framework, in which state-of-the-art VQA performance is achieved by our proposed DFAF framework. (对比试验和简化实验验证DFAF的有效性)
1. 相关工作
VQA的表示学习(Representation learning for VQA):早期的VQA常用VGG,后来用ResNet,最近的bottom-up and top-down网络则采用的faster RCNN来提取图像特征。特征学习是VQA发展的一个重要成分。
VQA的双线性融合(Bilinear Fusion for VQA):VQA需要学习语言和视觉之间的关系。早期的VQA模型,只是通过连接或者点乘的方法来获取交叉模态的特征。为了捕捉两种模态之间更高级的交互,提出了双线性融合的方法(利用双线性池化来融合不同模态的特征)。为了减少双线性融合方法的计算量,后续又提出了MCB,MLB,MUTAN等方法,这些方法的参数则更少。
自注意力方法(Self-attention-based methods):自注意力能够将特征转换为疑问特征,关键特征,值特征(query, key and value features)。不同特征之间的注意力矩阵可以通过query and key features的内积计算。获得注意力矩阵之后,特征可以被聚合为原始特征的注意力加权之和。基于自注意力机制提出的模型比如Non-local neural network,Relation Network,
协同注意力方法(Co-attention-based methods):协同注意力能够在两个模态交互建模,对于每一个单词,图像区域特征都会根据协同注意力与其对应。常见的模型包括Dense Symmetric Co-attention(DCN)。
其他相关工作(Other works for language and vision tasks):除了上面提到的方法,还有很多用于模态融合的方法。比如用于特征融合的Dynamic Parameter Prediction和Question-guided Hybrid Convolution。以及Structured attention和Adaptive attention。
2. 模型方法
(1)视觉和语言特征提取
作者提取图像特征用的是bottom-up & top-down attention mode,视觉区域特征用的Faster RCNN,每张图提取100个区域候选框,并与区域特征关联,每个区域特征的长度为2048。问题特征编码则采用GRU(输入为GLoVe词嵌入),每个问题Q都可以表示为14个单词,每个单词对应1280个特征。因此视觉区域特征和问题特征可以表示为:
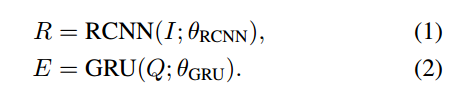
(2)InterMAF(Inter-modality Attention Flow)
InterMAF模块首先捕捉视觉特征和单词特征的重要性,然后根据学习到的重要权重,在两个模态之间传递信息流和合并特征。给定一个视觉区域和单词特征,首先计算他们之间的联合权重,每个视觉区域和单词特征都可以转换成query, key和value features,用R表示区域(region)特征,用E便是单词特征(embedding),则有:
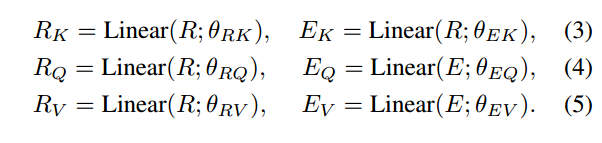
上式中的linear表示全连接层。
通过计算Rq和Ek的内积,我们可以得到未经处理的注意力权重(关于视觉特征和单词特征的合并信息);再对注意力权重进行均方根归一化和softmax非线性变换,可以得到两个注意力权重集合,如果用R<—E表示从单词到图像区域的信息流,用R—>E表示从图像区域到单词的信息流,则有:

内积与隐特征空间维度成正比,因此只需要对维度做正则化。
两个双向的InterMAF矩阵可以捕捉图像区域和单词之间的重要性,如果用InterMAF_R<—E为例,每一行都表示了视觉区域和所有词嵌入之间的注意力权重。所有词嵌入到一个图像区域特征的信息可以记为所有单词特征的加权和,InterMAF中,这种信息流可以更新视觉区域特征和单词特征,记为:
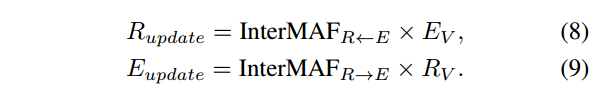
其中用于更新视觉区域特征和单词特征的E_V和R_V是两个没有加权的信息流。
更新后的视觉特征和单词特征,分别将它们与初始的视觉特征和单词特征进行连接,这里采用了一层全连接层:
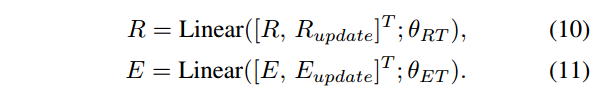
InterMAF模块的输出结果会传到DyIntraMAF模块中。
(3)DyIntraMAF(Dynamic Intra-modality Attention Flow)
DyIntraMAF的输入已经对两个交叉模态进行了编码,前面也介绍过了,模态内的关系则是进一步的补充。DyIntraMAF则用一种动态注意力机制对模态内的关系进行建模。流程图如下所示:

朴素模态内矩阵可以捕捉视觉区域之间的和单词之间的重要性:
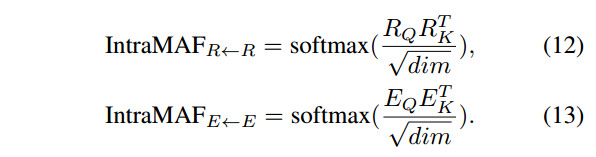
模态内部重要性的估算这里用的是矩阵的点乘。这些权重矩阵(也就是前面计算的重要性)之后在模态内对信息流进行加权转换。模态内部的关系建模已经在目标检测,看图说话,BERT词嵌入中表现出了有效性。
然而,朴素(naive)IntraMAF模块只使用了模态内的信息,而一些关系只能通过其他模态的条件信息来获得。因此需要对朴素IntraMAF进行修改。
为了从其他模态中获得条件性的信息,沿着目标索引的维度对视觉区域特征和沿着单词索引的维度对单词特征进行平均池化,池化后的两个模态特征在转换成维度特征向量,之后再对这两个向量进行sigmoid处理,用表示,以生成通道条件门(channel-wise conditioning gates):
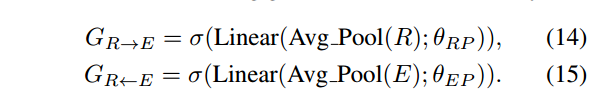
query和key特征可以通过上面两个条件通道门得到:

其中表示点乘,这两个门的设计灵感其实来自于Squeeze and Excitation Network和Gated Convolution,关键不同之处在于这两个门是基于交叉模态的。
之后动态模态内注意力流矩阵(dynamic intra-modality attention flow matrices)的获得是通过:
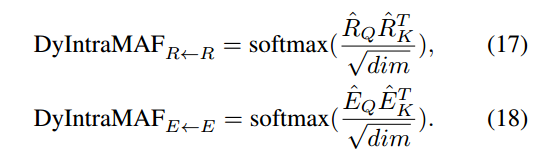
视觉区域和单词特征的更新则是对加权的值特征通过残差得到:
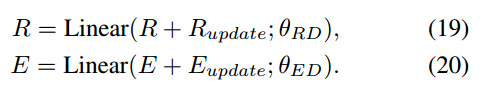
其中:
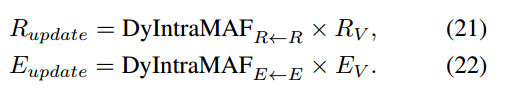
注意这里我们只用到query和key特征。
(4)流程
这里主要是介绍如何将两个流模块结合起来。整个模型结构就是前面fig 1所展示的那样,首先用Faster RCNN提取视觉特征和用GRU提取单词特征,然后两组特征通过全连接层转换成相同长度的向量,InterMAF模块在每一组视觉特征和单词特征之间传递信息流并且在每一个区域或者单词之间进行更新,该模块的输出则是DyIntraMAF的输入,DyIntraMAF模块在每个模态内中动态的传递信息流,在同一个模态内会通过残差连接对视觉特征和单词特征进行再次更新。一个InterMAF模块后接一个DyIntraMAF模块构成了提出方法DFAF的一个基本块,在特征更新的过程中可以通过特征连接或者残差连接堆叠多个块。深度模态内或模态间信息流的训练可以采用随机梯度下降,另外作者使用了multi-head注意力,原始特征则会沿着通道维度分为不同的组,不同的组生成平行注意力在每个组内独立的更新视觉特征和单词特征。
(5)答案输出层和损失函数(Answer Prediction Layer and Loss Function)
通过以上InterMAF模块和DyIntraMAF模块对特征的更新,可以得到用于VQA的最终视觉区域和单词特征。
通过对两种特征的平均池化,可以得到图像和问题的不同表达,之后可以通过特征连接,特征点乘,特征相加获得融合特征,实验中作者做了3种方法,但是点乘的效果是最好的。
与其他的VQA问题一样,作者也将VQA视为一个分类问题。最后是采用了两层的MLP(multi-layer perceptron),之间有一层Relu激活函数,最后再连接一个softmax,ground-truth则是从标注中选择出现次数大于5次的答案,loss选用的交叉熵。
3. 实验
(1)数据集
用的VQAv2,这里不多做介绍了。
(2)实验参数设置(这里也不多介绍)
(3)DFAF的简化实验
下面是一个ablation study的结果:

(4)注意力流权重的可视化
下图是一个模态内信息流权重的可视化结果:

(5)模型比较
最后作者与一些经典模型进行了比较,比较结果如下:

















 829
829











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











