







Recently I am trying to rewrite a spider of a website to download the resources on it, which supports to crawl the website daily more than 1 million pages and thousands of download, each connection cost about 10 second, and while I hold 10 processors, I could deal with 0.8 million pages per day. I wanna do all the things in python, but also MySQL is used. I always think a lot before I code, but every time when I am coding, I come out a better idea to finish the job. So I don't think too much this time, I just need to satisfy the need, and do less.
The last version cost too much CPU time in MySQL, so here comes the new structure to low down the MySQL load, and I use a master to hold a Queue, and maintain the faults, multi-processor to get job from master, when they finish the job, they reply to the MySQL rather than reply to the master.
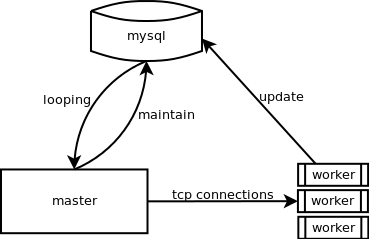
G.01 polling structure
Besides, the polling pool need more new items, another part of the system is the crawl more pages which needs to be monitor. Another spider goes from some root pages, and go down the tree nodes by getting inside the links, also MySQL is used to persist data.















 7144
7144

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









