






点击上方“视学算法”,选择加"星标"或“置顶”
重磅干货,第一时间送达

论文链接:
https://arxiv.org/abs/2302.02318
代码链接:
https://github.com/qizekun/ReCon
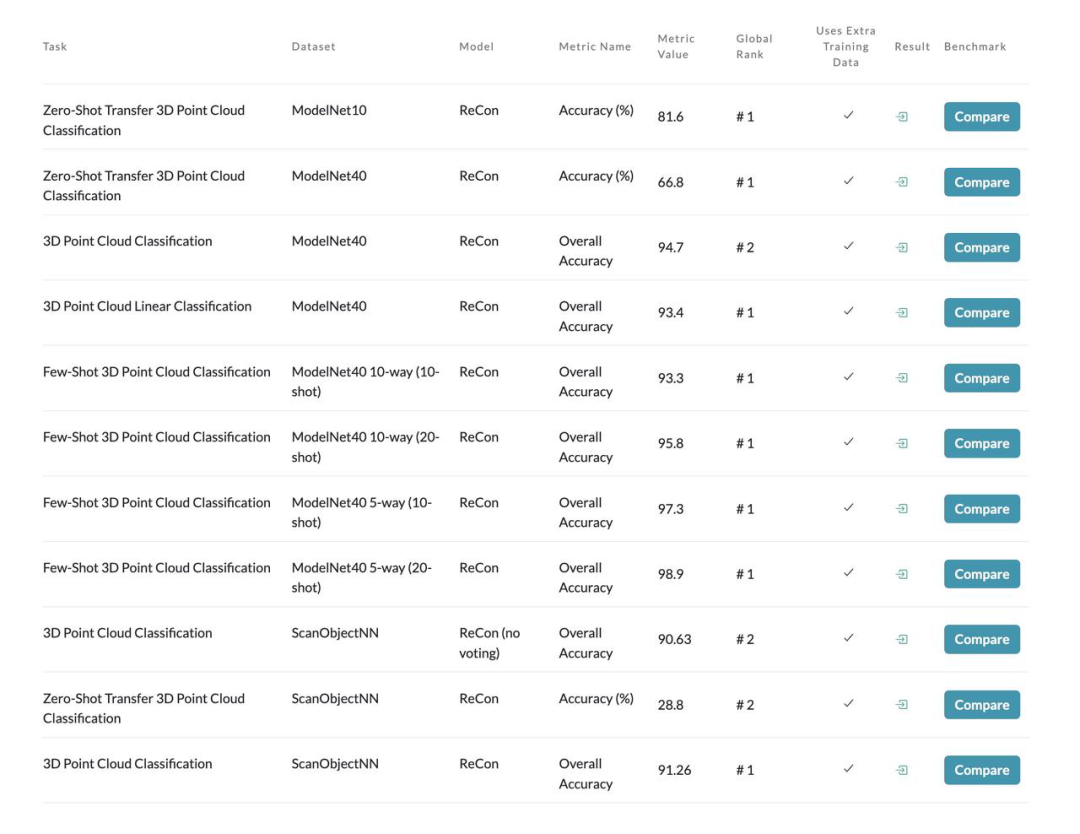
介绍一下我们在 3D 表征学习上的新工作,ReCon: Contrast with Reconstruct,通过生成式学习指导对比学习实现高效的 3D 表征,在ScanObjectNN 上实现 91.26% 的 OA,在 ModelNet40 实现 66.8% 的 Zero-Shot 精度,以及多项 SOTA,代码已开源。

引言
我们知道,3D 点云长期遭受着严重的数据缺乏问题,常用的 ModelNet40、ShapeNet 数据集仅包含 ~14k 与 ~51k 的数据,这与 2D 或图文多模态上动辄14M、300M 甚至 5B 的超大规模数据形成巨大对比。因此,如何在有限的数据上高效的提取 3D 表征成为我们的研究动机,我们从 Generative 和 Contrastive 两大主流的自监督框架入手进行分析。
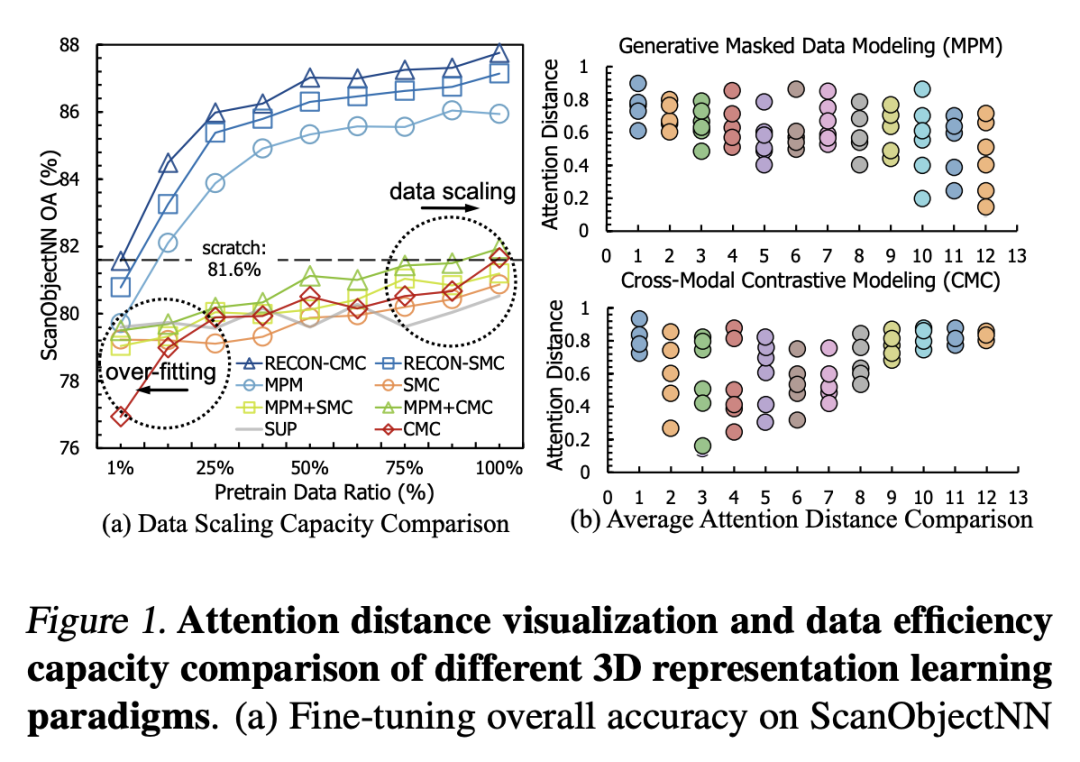
我们首先研究了 MPM(Masked Point Modeling)、CMC(Cross-modal Contrastive)和 SMC(Single-modal Contrastive)等预训练方法对 Pretrain 数据的依赖性,我们在 ShapeNet 上进行预训练,并在 ScanObjectNN 上测试迁移性能,结果在图(a)中展示。我们发现:
Contrastive 方法具有 Over-fitting 问题
当缺乏预训练数据(<90%)时,Contrastive 模型无法带来泛化性能,而 Generative 模型仅需大约 25% 的数据就可以给下游任务带来显著的性能提升。这表明,对比学习很容易找到表征捷径来过度拟合有限的数据[1],而生成式模型对数据的依赖程度较低,可以用很少的数据学习到良好的初始化。
Generative 方法具有 Data filling 问题
当预训练数据扩大时,对比学习呈现出更好的潜在能力,而生成模型在提供更多数据时只带来较小的性能提升(从 75% 提升到 100% 的数据对下游任务的改善并不明显)。这表明,当预训练数据足够时,对比学习可以为生成模型带来更强的数据扩展能力。在 2D 中,对比学习模型[2]在下游任务的效果超越了扩展能力较弱的生成模型[3]。
我们还研究了MPM(Masked Point Modeling)、CMC(Cross-modal Contrastive)在感受野和注意力区域上的区别,类比 2D 中 ViT 的 Average Attention Distance[4],我们根据 3D patch 中心之间的欧式距离和 attention map 权重来生成 3D Average Attention Distance,结果在图(b)中展示。
我们观察到一个模式差异问题,即对比模型的注意力主要集中在全局领域,其注意力距离逐步上升并趋于一个较高值,而生成模型对集中的局部注意力有兴趣,这与 Xie 等人在 2D 的观察结果一致[5]。
如何有效地结合 Contrastive 和 Generative 方法,并且规避其在注意力模式上的区别成为我们工作的 motivation。

知识蒸馏——对比式和生成式的统一理论
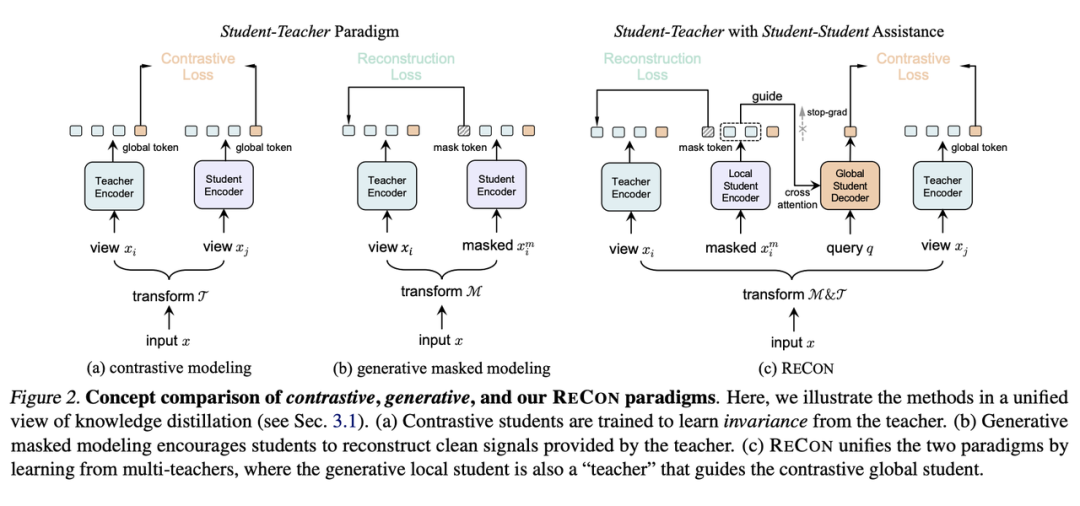
对比学习通过对统一样本数据的不同 view 进行拉进、不同样本的view进行推远来促使模型学习深层次的知识,这里的 view 可以是单模态[6],也可以是多模态的[7], 其本质上相当于在 feature map 或 logits 上相互提供监督信号来寻找全局语义上的联系,即不同 view 下特征的蒸馏。
生成式模型通过 denoising autoencoder 的方式,对数据样本施加扰动(例如mask),并设置数据样本的某一种 view(例如 pixel[3]、VQ code[8]、HOG 特征[9] 等等)作为 teacher 提供监督信号。其本质在于迫使模型学习局部特征的相互关系来实现对教师特征的对齐。
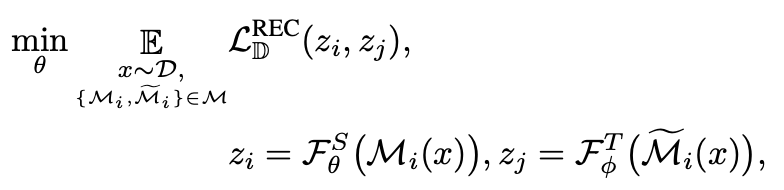
在知识蒸馏的视角下,我们统一了 Contrastive 和 Generative 两种自监督范式,由此引申出 ReCon 模型,通过多教师蒸馏与学生协同学习下的自监督模型(student-teacher knowledge distillation with student-student assistance)。Local teacher 通过局部语义的复原来使 Local student 学到丰富的局部知识,Local student 向 Global student 提供局部知识以帮助其全局知识的学习。
在细节上,二者使用不同的 Transformer Attention 架构来规避注意力模式的差异。关于生成式学习的形式,可以类似于 BEiT[8]、ACT[10]通过 Tokenizer 生成语义 token 用于重建,即使用 Tokenizer 作为 Teacher 监督,也可以类似于 MAE[3]、PointMAE[11]直接重建源数据,即使用 Identity 作为 Teacher 监督。而关于对比学习的形式,可以类似于 CLIP[7]进行跨模态之间的对比学习,也可以类似于 SimCLR[6]、PointContrast[12]进行单模态的对比学习。

方法
我们在主图展示了 ReCon 的 encoder-decoder 框架,其中 Point Identity 作为Local 3D Point Cloud Encoder 教师,跨模态预训练模型作为 Global 3D Point Cloud Decoder 教师,这种配置在后续的消融实验被验证有最优的效果。
我们使用 timm[13]或 CLIP[7]的视觉编码器作为 ReCon 的 2D Teacher,CLIP 的文本编码器作为 ReCon 的 Text Teacher,并在后续的消融实验发现 freeze parameter 有利于知识的迁移。对于 Local 3D Point Cloud Encoder,我们完全采用 MAE 式的非对称结构,来防止位置编码在点云重建中可能附有的知识泄露。
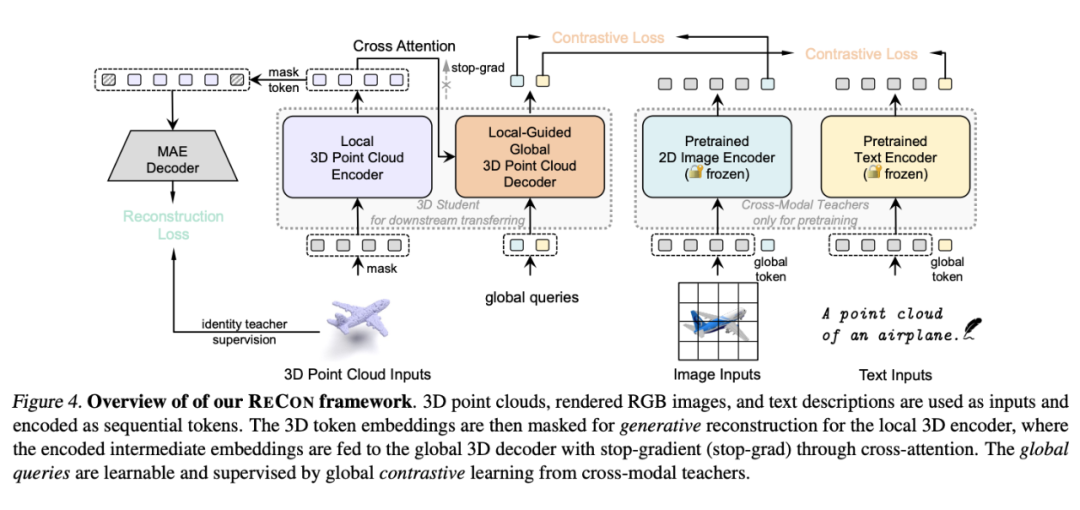
在模型结构上,我们使用了类似 BART[14]的 encoder-decoder 结构,每个 Stream 在一个 layer 中均包含一个 Attention 层与 FFN 层,其中 encoder 的 inputs embeding 产生 Cross Attention 的 K 与 V,并使用 stop-grad 来防止梯度干扰。由于 global queries 一般仅包含少量的几个 token,在运算效率上并不会比单流网络增加很多。

实验
我们的 ReCon 在点云分类最常用的两个数据集 ScanObjectNN 和 ModelNet40 均取得了 SOTA 的性能,尤其是在 ScanObjectNN 的迁移效果,达到了惊人的 91.26% Overall Accuracy。

此外,我们将 ReCon 分为三种设置,ReCon-T、ReCon-S 和 ReCon,他们的模型结构完全一样,仅有模型维度上的区别。即使使用了更小维度的 ReCon 依然产生了优异的性能,拥有 19M 甚至 11M 参数的 ReCon 依然大幅度优于 PointMAE 等 3D 自监督方法。

如果进一步利用 Pretrain Text Teacher,可以实现 Zero-Shot 分类,下表展示了 ReCon 在 ModelNet40 上的 Zero-Shot 性能,同样远超其他方法。


讨论
1. ReCon优良性能的来源?
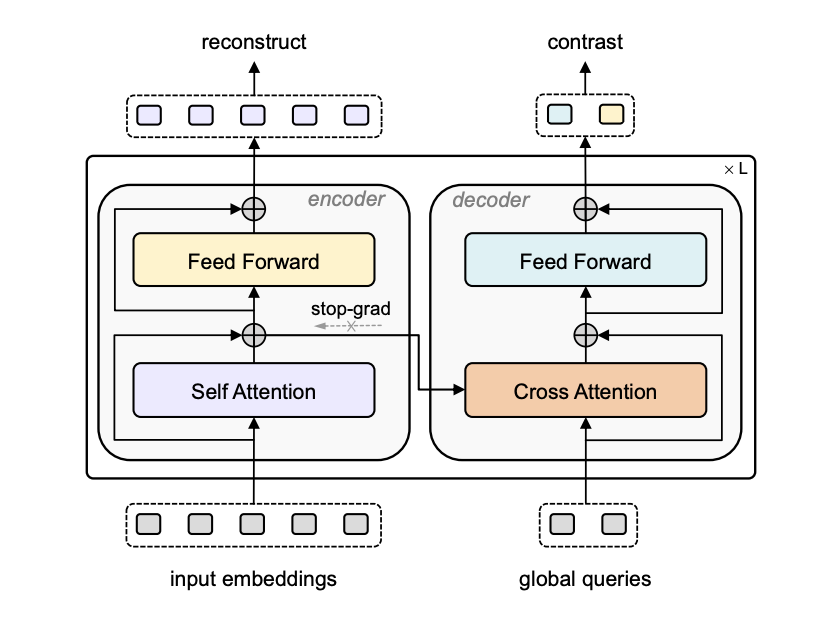
我们首先从 loss 的角度进行分析,我们记录了 vanilla CMC(Cross-Modal Contrastive)与我们的经过重建指导的 ReCon-CMC 在 ShapeNet 测试集(未用于预训练)的 loss 曲线,并记录了在 ScanObjectNN 上的相应微调精度。可以看出,我们的 ReCon-CMC 的测试对比损失始终低于普通的 CMC,并且更加稳定地收敛到较低的值,表明我们的 ReCon 带来了更好的预训练对比任务的泛化性能,而不会陷入简单解决方案的捷径,预训练过程中的过拟合问题得到缓解。
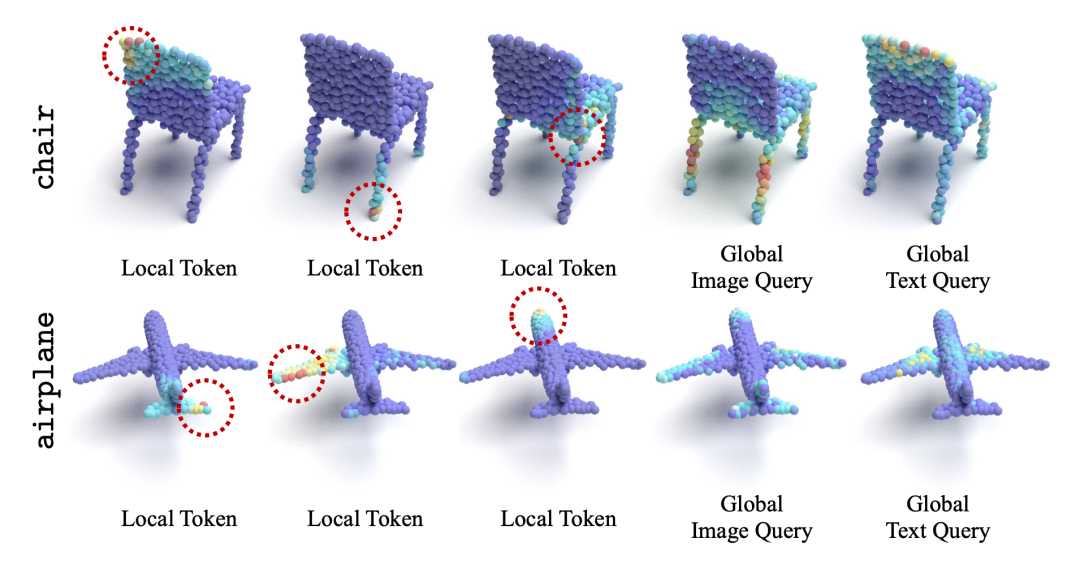
此外,我们也对不同 token 的 attention map 进行了可视化分析,包括 Local Student Encoder 的局部 token 与Global Student Decoder 的全局 Query,我们用红色的圆圈将查询 Token 圈出,红色和黄色区域代表注意力的重点区域,青色和紫色区域为注意力的忽视区域。
可以看出,3D 点云中的 Local Token 更多地关注 Token 本身周围的几何结构,而 Global Query 则关注对象的整个部分。甚至,局部表征可能已经学会了对称性的一些几何理解或世界知识。例如,飞机左翼上的 Token 也注意到了右翼。此外,Global Image 和 Text Query 可能学到了一些互补的知识。
2. 是否Pretrained Cross-Modal Teacher is all your need?
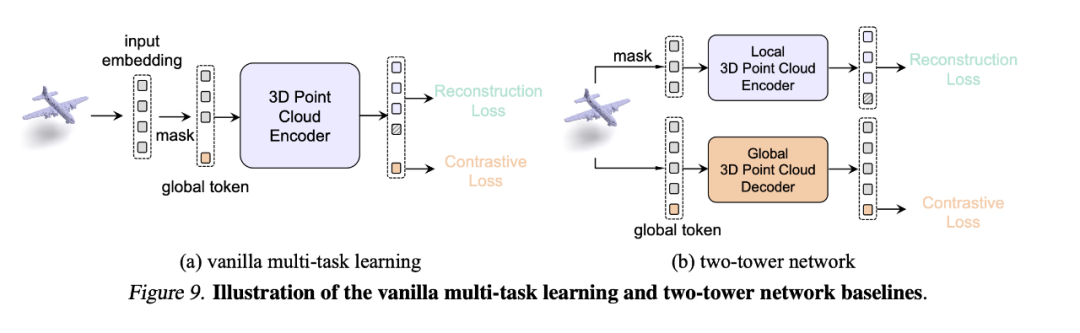
为验证模型的收益并不来自教师,而是因为 ReCon 结构是一种优良的 Generative learning 和 Contrastive learning 结合方法,我们在论文的附录 C 中探究了另外两种掩码数据建模和对比学习结合的方法,包括 Vanilla Multi-task Learning Fusion 和 Two-Tower Network,他们都用了包含预训练权重的跨模态教师来做指导。
vanilla multi-task 通过添加多个类似于 [cls] Token 的 nn.Parameters() token 用于进行对比学习
two-tower network 通过两个单独的 Transformer 训练各自的代理任务
经过实验,简单的将包含预训练权重的跨模态知识进行传递并不会产生效果,我们猜测这是引言所表现出的模式差异所导致的,即 Local-Global 的注意力模式差异与数据缺乏导致的过拟合问题。而这种模式差异正是我们设计 ReCon block 的动机。


展望
ReCon 大幅提升了 3D 表征学习的效果,在点云分类与 Zero-Shot 中均取得了 SOTA 的性能。但我们认为 ReCon 发现并解决的问题并不是在 3D 中特有的,在其他缺乏数据,或相对缺乏数据的模态中依然有可能有效,我们希望有更多 ReCon-Style 的架构在更多领域出现。

相关工作
相关工作包括:
ACT (https://arxiv.org/abs/2212.08320,ICLR’23)
CLIP-FO3D (https://arxiv.org/abs/2303.04748)

参考文献
[1] Shortcut learning in deep neural networks
[2] CLIP Itself is a Strong Fine-tuner: Achieving 85.7% and 88.0% Top-1 Accuracy with ViT-B and ViT-L on ImageNet
[3] Masked autoencoders are scalable vision learners
[4] An image is worth 16x16 words: Transformers for image recognition at scale
[5] Revealing the dark secrets of masked image modeling
[6] A simple framework for contrastive learning of visual representations
[7] Learning transferable visual models from natural language supervision
[8] Beit: Bert pre-training of image transformers
[9] Masked feature prediction for self-supervised visual pre-training
[10] Autoencoders as Cross-Modal Teachers: Can Pretrained 2D Image Transformers Help 3D Representation Learning?
[11] Masked autoencoders for point cloud self-supervised learning
[12] Pointcontrast: Unsupervised pre-training for 3d point cloud understanding
[13] PyTorch Image Models
[14] Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension

点个在看 paper不断!

















 589
589

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









