







一些废话:
之前读完了MAE,对自监督学习有了新的认知。
当初在看半监督学习时,发现MeanTeacher、semiGan也好,蒸馏学习也好,其实多多少少采用了相似的思想。
而恺明大佬在MAE中对NLP任务和CV任务的分析与探讨也让人感受很深,首先有些方法不一定非常新颖,但如何得出这个方法,这个思考过程,是非常重要的。
概述
2017年,FAIR提出的Moco不仅逼近、甚至超越了部分有监督视觉任务的预训练模型。
自监督学习可以粗略分为:基于上下文、基于对比的、基于时序这三种。
入门可以阅读这篇博客:自监督学习
首先我们将Moco和MAE进行对比,同样是自监督学习:MAE属于生成式任务(可以理解成基于上下文的),Moco属于对比式学习。
对比学习
什么是对比式学习呢:
我们可以通过设置代理任务的方式来生成所谓的类似标签,这样可以在无需标注的情况下得到所谓的类似样本。
例如:有一张狗的图像,和一些猫的图像。我们对这张狗的图像做随机裁剪,得到的图像都可以认为是类似的样本,而其余的图像则认为是不相似的样本。
我们将所有的样本输入一个神经网络模型,每个样本得到一些特征,而相似样本的特征值需要靠近,不相似的样本特征值在特征空间中需要彼此远离,通过这样的思路来训练整个神经网络,这就是一个自监督学习的方案。而随机裁剪这种做法又被称为instance discrimination。
若当前的实例为x,与x相似我们称之为正样本x+,与x不相似的称之为负样本x-,而x与x+的距离要拉近,与x-的距离需要拉远。这个距离可以通过点积来计算:
score(f(x),f(x+) >> score(f(x),f(x-))
损失函数 InfoNCE的计算:
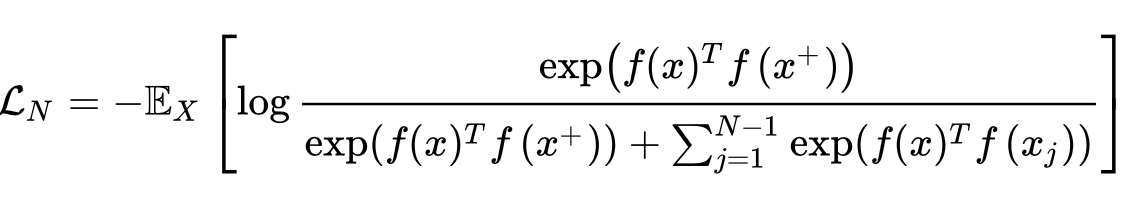
当然,正样本和负样本的定义方式可以更加灵活,例如视频的相邻帧,例如机器人在连续的环境中运行时获取的IMU数据(具有时空连续性)、同一个物体的不同角度图像,在这些思路上都可以找到新的定义方式。
MoCo
MoCo的名称来源于文章的:Momentum Contrust,也就是动量对比。
此处的动量并不是物理量,而是:yt = m * yt-1 + (1-m) xt
其中m为动量,x为t时刻输入,y为t时刻输出。利用前一时刻也就是t-1时刻的输出来做加权平均。所以动量更新也可以理解成为一种移动加权平均.
这个公式跟MeanTeacher中参数的指数移动平均(EMA)公式也很类似:θ t =αθ′ t−1+(1−α)*θ t
原文总结说,基于对比的自监督学习其实就是训练一个编码器然后在一个大的字典里确保和对应的键是相似的,和其它的是不相似的。所以字典的大小就成了关键,传统的方法是字典的大小就是等于mini_batch的大小,但是这种方法由于显卡和算力的问题导致其不能太大。因此MoCo的创新点就在于通过动态字典维护的方式
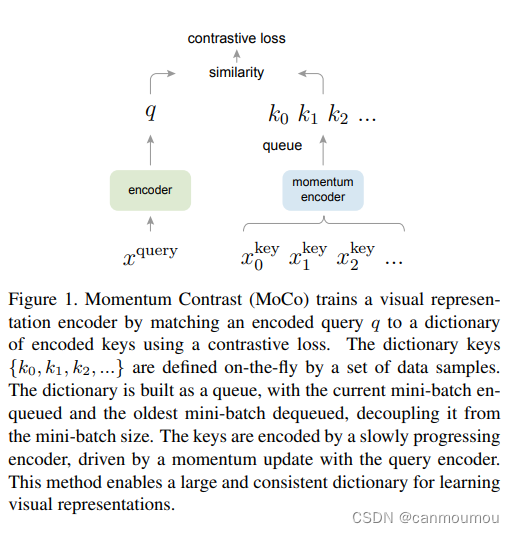
MoCo的做法如下:制作了一个动态字典,动态字典由(1)一个队列 (2)一个动量编码器组成
如图所示。负样本因为不需要太多更新,所以每次做完编码后,就被丢进队列里面,而最老的编码出列(队列是先进先出的),这样可以保证字典的轻量化,使得字典大小小于batch size。
左边的xquery为当前锚定数据,而右边是需要和铆钉数据做相似度对比的数据。
考虑一个编码后的特征q和一组编码后的数据样本{k0, k1, k2, …},把k作为字典的key。假设字典中存在一个与q相似的正样本(表示为k+),则计算q和k+的对比性损失(这个由lecun在2006年提出)
当q与k+相似而与所有负样本不相似时,其对比性损失越小,并用点积来衡量相似度,也就是前文提到过的InfoNCE。
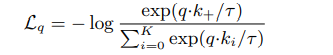
1)字典中包含尽可能多的负样本,数据更丰富;
2)用于提取keys的encoder网络我们应该尽量保持其演化中不变,因为随着训练肯定是有变化的。



















 459
459

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











