








Introduction
这是ICML2018的一篇论文,其由来自英伟达、阿尔托大学和 MIT 的研究者联合发表。该文章提出了一个很有意思的观点:在某些常见情况下,网络可以学习恢复信号而不用“看”到“干净”的信号,且得到的结果接近或相当于使用“干净”样本进行训练。而这项结论来自于一个简单的统计学上的观察:我们在网络训练中使用的损失函数,其仅仅要求目标信号(ground truth)在某些统计值上是“干净”的,而不需要每个目标信号都是“干净”的。
Theoretical background
先看一种简单的情况,假设我们对某个物理量(如房间的温度)多次测量,得到一系列不可靠的测量值(
y
1
,
y
2
,
.
.
.
y_1,y_2,...
y1,y2,...)。一种估计真实值的通用方法是找到一个数
z
z
z,使其与这些测量值有最小的平均偏差,即优化下面损失函数:
arg
min
z
E
y
{
L
(
z
,
y
)
}
\arg\min_z \mathbb{E}_y\{L(z,y)\}
argzminEy{L(z,y)}
对于
L
2
L_2
L2损失
L
(
z
,
y
)
=
(
z
−
y
)
2
L(z,y)=(z-y)^2
L(z,y)=(z−y)2,该损失函数的最优解在测量值的算数平均值(期望)处取到:
z
=
E
y
{
y
}
z=\mathbb{E}_y\{y\}
z=Ey{y}
对于
L
1
L_1
L1损失
L
(
z
,
y
)
=
∣
z
−
y
∣
L(z,y)=|z-y|
L(z,y)=∣z−y∣,该损失函数的最优解在测量值的中值处取到:
z
=
m
e
d
i
a
n
{
y
}
z=median\{y\}
z=median{y}
对于
L
0
L_0
L0损失
L
(
z
,
y
)
=
∣
z
−
y
∣
0
L(z,y)=|z-y|_0
L(z,y)=∣z−y∣0,该损失函数的最优解近似在测量值的众数处取到:
z
=
m
o
d
e
{
y
}
z=mode\{y\}
z=mode{y}
从统计学角度,这些通用的损失函数都可以解释为似然函数的负对数,而对这些损失函数的优化过程可以看做为最大似然估计。
训练神经网络回归器是这种点估计过程的推广。已知一系列输入-目标对
(
x
i
,
y
i
)
(x_i,y_i)
(xi,yi),典型的网络训练形式是优化下列目标函数:
arg
min
θ
E
(
x
,
y
)
{
L
(
f
θ
(
x
)
,
y
)
}
\arg\min_\theta\mathbb{E}_{(x,y)}\{L(f_\theta(x),y)\}
argθminE(x,y){L(fθ(x),y)}
其中,网络函数为
f
θ
(
x
)
f_\theta(x)
fθ(x),
θ
\theta
θ为网络参数。
如果将整个训练任务分解为几个训练步骤,根据贝叶斯定理可将上述目标函数变为:
arg
min
θ
E
x
{
E
y
∣
x
{
L
(
f
θ
(
x
)
,
y
)
}
}
\arg\min_\theta\mathbb{E}_x\{\mathbb{E}_{y|x}\{L(f_\theta(x),y)\}\}
argθminEx{Ey∣x{L(fθ(x),y)}}
则网络训练的目标函数与前面所说的标量损失函数有相同的形式,也具有相同的特性。
实际上,通过上述目标函数,在有限数量的输入-目标对上训练回归器的过程隐含了一点:输入与目标的关系并不是一一对应的,而是一个多值映射问题。比如对于一个超分辨问题来说,对于每一个输入的低分辨图像,其可能对应于多张高分辨图像,或者说多张高分辨图像的下采样可能对应同一张图像。而在高低分辨率的图像对上,使用 L 2 L_2 L2损失函数训练网络,网络会学习到输出所有可能结果的平均值。
综上所述,
L
2
L_2
L2最小化的一个看起来似乎微不足道的属性是,如果我们用一个期望与目标相匹配的随机数替换目标,那么估计值将保持不变。因此,如果输入条件目标分布
p
(
y
∣
x
)
p(y|x)
p(y∣x)被具有相同条件期望值的任意分布替换,则最佳网络参数
θ
\theta
θ也保持不变。这意味着,可以在不改变网络训练结果的情况下,将神经网络的训练目标添加上均值为0的噪声。则网络目标函数可以变为
arg
min
θ
∑
i
L
(
f
θ
(
x
^
i
)
,
y
^
i
)
\arg\min_\theta\sum_i{L(f_\theta(\hat{x}_i),\hat{y}_i)}
argθmini∑L(fθ(x^i),y^i)
其中,输出和目标都是来自于有噪声的分布,且满足 E { y ^ i ∣ x ^ i } = y i \mathbb{E}\{\hat{y}_i|\hat{x}_i\}=y_i E{y^i∣x^i}=yi
当给定的训练数据无限多时,该目标函数的解与原目标函数的相同。当训练数据有限多时,估计的均方误差等于目标中的噪声的平均方差除以训练样例的数目,即:
E
y
^
[
1
N
∑
i
y
i
−
1
N
∑
i
y
^
i
]
2
=
1
N
[
1
N
∑
i
V
a
r
(
y
i
)
]
\mathbb{E}_{\hat{y}} \left[\frac{1}{N}\sum_i{y_i}-\frac{1}{N}\sum_i{\hat{y}_i}\right]^2=\frac{1}{N}\left[\frac{1}{N}\sum_i{Var(y_i)}\right]
Ey^[N1i∑yi−N1i∑y^i]2=N1[N1i∑Var(yi)]
因此,随着样本数量的增加,误差接近于零。即使数据量有限,估计也是无偏的,因为它在期望上是正确的。
在许多图像复原任务中,输入的被污染数据的期望就是我们要恢复的“干净”的目标,因此只要对每张被污染的图像观察两次,即输入数据集也是目标数据集,就可以实现对网络的训练,而不需要获得“干净”的目标。
L
1
L_1
L1损失可以得到目标的中值,这意味着网络可以被训练用来修复有显著异常内容的图像(最高可达50%),而且也仅仅需要成对的被污染图像。
Practical experiments
加性高斯白噪声
一般加性高斯白噪声是零均值的,所以文章采用
L
2
L_2
L2损失训练网络。
文章使用开源图像库的图像,对每张图像随机添加方差为
σ
∈
[
0
,
50
]
\sigma\in[0,50]
σ∈[0,50]的噪声,网络在去噪过程中需要估计噪声幅度,整个过程是盲去噪过程。
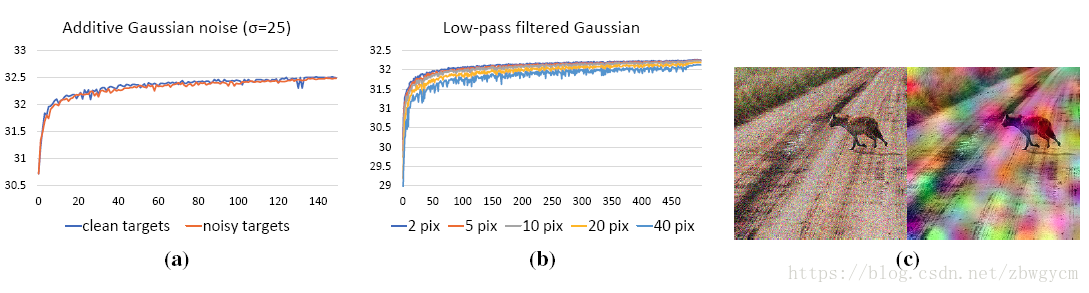
从去噪结果可以看出,使用“干净”的目标和使用有噪声的目标有相似的收敛速度和去噪质量。如果进一步使用不同大小的高斯滤波器模糊有噪声的目标图像,可以观察到低频噪声会更顽固,需要更多的迭代次数,但是对于所有情况来说,网络都收敛于相似的去噪质量。
其他合成噪声
泊松噪声
泊松噪声和高斯噪声一样是零均值的,但是更难去除,因为其是信号相关的。文章使用
L
2
L_2
L2损失,且在训练过程中变化噪声幅度
λ
∈
[
0
,
50
]
\lambda\in[0,50]
λ∈[0,50]。
需要说明的是,图像饱和截止区域是不满足零均值假设,因为在这些区域部分噪声分布被丢掉了,而剩余部分的期望不再是零了,所以在这些区域不能得到好的效果。
乘性伯努利噪声
即相当于对图像进行随机采样,未采样到的点像素值为0。被污染像素的可能性记为
p
p
p,在文章训练过程中,变化
p
∈
[
0.0
,
0.95
]
p\in[0.0,0.95]
p∈[0.0,0.95],而在测试中
p
=
0.5
p=0.5
p=0.5。而得到的结果是使用被污染的目标比“干净”目标得到PSNR值还要高一点,这可能是由于被污染的目标在网络输出中有效地应用了dropout技术的结果。

文字去除
网络使用独立的被污染输入和目标对进行训练,被污染像素的可能性
p
p
p在训练过程中为
[
0.0
,
0.5
]
[0.0,0.5]
[0.0,0.5],而在测试中
p
=
0.25
p=0.25
p=0.25。且在训练中使用
L
1
L_1
L1损失作为损失函数,从而去除异常值。

随机值脉冲噪声
即对于每一个位置的像素都有可能性
p
p
p被
[
0
,
1
]
[0,1]
[0,1]的值随机替代。在这种情况下,平均值和中值都能产生好的结果,其理想的输出应该是像素值分布的众数。为了近似寻找众数,文章使用退火版本的“
L
0
L_0
L0损失”函数,其定义为
(
∣
f
θ
(
x
^
)
−
y
^
∣
+
ϵ
)
γ
(|f_\theta(\hat{x})-\hat{y}|+\epsilon)^\gamma
(∣fθ(x^)−y^∣+ϵ)γ,其中
ϵ
=
1
0
−
8
\epsilon=10^{-8}
ϵ=10−8,在训练时
γ
\gamma
γ从2到0线性下降。训练时输入和目标图像被污染像素的可能性为
[
0
,
0.95
]
[0,0.95]
[0,0.95]。

除此之外,文章还在Monte Carlo渲染和MRI方面做了测试,均得到了不错的效果。
该文章的意义在于,在现实世界中想要获得清晰的训练数据往往是很困难的,而这篇文章提供了一种新的思路解决这个问题。文章也提到了,天下没有免费的午餐,该方法也无法学习获取输入数据中不存在的特性,但这同样适用于清晰目标的训练。
英伟达新闻地址:新闻地址
An unofficial and partial Keras implementation:github
更新:
英伟达官方tensorflow实现:github

















 880
880

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









