







目录
MIPS64流水线处理器原理与优化技术
1. 流水线基本原理
流水线技术是为了提高处理器指令吞吐量(throughput)而萌生的技术。简单来说就是尽量让每个时间段中处理器中所有的部件都同时工作,而不要留有空闲。拿做菜来举个例:
做菜可以分为很多个步骤:洗菜,切菜,炒菜,装盘,传菜。这些步骤在流水线中叫做stage
每一个stage 都会有不一样的工作。在没有作流水化的情况下就如图一所示,在这个情况下,切菜的时候洗菜的池子炒菜的锅装菜的盘子以及传菜的人都不工作,这就会造成很大的资源浪费,5个clock cycle才能做好一道菜,然而在流水化之后,就变成了图二所示的情况,第一道菜做出来需要5个clock cycle ,但是在第一道菜切菜的时候,第二道菜就开始洗菜了,第一道菜开始炒的时候第二道菜开始切第三道菜开始洗,这样经过5个clock cycle整个流水线就被填满,每一个周期每一个部件都在做事,在第五个clock cycle开始,每一个clock cycle就会出来一个指令。这样相当于处理指令的速度提升了5倍。
图一
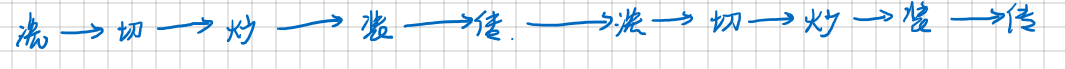
图二

但是流水线并不是那么十全十美,将一个过程流水化是需要代价的。
- 流水化后每一个stage所需要的时间都要均衡才能顺利运行起来。所以流水线这种东西,为了均衡每一个stage,快的stage要等慢的stage执行完,所以说流水线中stage 所用的时间是取决于最慢的那个stage的。这样考虑一下其实每一个单独的stage其实所用的时间是增加的。
- 流水化调度每一个stage需要有额外的运行开支
基于这两个原因,流水线其实在每一个指令的角度上来看是不如非流水线的。而且这种开支是在每一个stage层面上的开支,所以很容易理解流水线分得越细,这种开支对整体运行的影响就越大,所以这也就是为什么不过大提升流水线深度的原因,目前市面上的PC用的芯片大多用的是13级或者是14级左右的流水线,像我们常用的ARM芯片很多也就是4级5级的样子。
MIPS64指令集架构就是专为流水线设计的架构,其设计出了标准的5级流水线,这也是当时MIPS64指令集处理性能比当时Intel的支持X86指令集芯片处理性能要好得多原因之一,就连目前MIPS64架构一直为流水线处理学习最好的范本,国产的龙芯就是以MIPS64指令集为基本架构设计的。
MIPS流水线基本工作原理
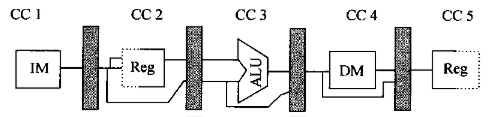
最基本的MIPS流水线分为5个stage:
- IF(取指):注意这个instruction memory和data memory其实是同一个
- ID(译码)
- EX(执行):在ID部分确定是不是分支语句,分支语句的执行是在这里
- MEM(存储器访问)
- WB(回写)
结构如下图所示:

考虑到相邻指令在相同流水级的时候可能会发生数据的干扰,所以需要几个缓冲寄存器,把流水级刚处理好的数据存起来。所以流水线就变成了下图这样,灰色的长方形就是寄存器,有些资料上自动省略了这一部分。
到这里,我们结构上的准备已经做好了,也就是说这个流水线基本功能已经齐全了,但是还有一些小的工作需要修修补补。一个很大的问题就是在指令重叠执行的时候遇见某些特殊情况会造成冲突,举个很简单的例子:上个菜我要炒点肉,下到菜也要用这些熟肉,如果上道菜的肉没有出锅的话,下一道菜的炒菜的步骤也进行不下去,因为下一道炒菜的步骤是和上一步装盘是同时做的,你得等装了盘再倒进第二个菜的锅里。当然这只是其中的一种情况。用专业术语来描述这种问题叫做hazard。
在流水线中hazard种类共有3大类:
- structure hazard:由于硬件资源不足的原因导致的冲突
- data hazard:由于指令需要的数据无法在需要的stage产生而导致的冲突
- control hazard:由于不知道下一步PC应该填哪个所以得等前面的指令执行完
而解决这三大类hazard的最直接暴力的方法就是拖,就硬拖到有数据来的时候再运行就好了,这样工程师是省事了。但是处理器的性能上就得牺牲一大截。为了解决这些问题,我们还需要在硬件上进行一些魔改。
对于structure hazard而言出现的问题主要是在IF阶段的时候需要用到memory,在MEM阶段也需要用到memory,而在哈佛结构中指令存储器和数据存储器是同一个,而这个memory又只有一个访问接口每次只能访问一次,读或者写。所以在下图所示的情况中就出现了structure hazard。解决方案要么就花钱在memory上多装几个访问接口支持多次访问,或者说就硬等。

对于data hazard,我们可以在产生数据结果的stage中把数据通路给改造一下,使其尽量一出结果就传到需要的地方,而不是经过MEM和WB stage之后再传回去,这一技术我们称之为forwarding。如何具体实现这一功能呢?首先我们得清楚什么时候会产生数据什么时候需要数据。数据的产生是在MEM阶段才会有的以及在EX阶段的末尾也会有,因此我们从这两个阶段末尾的寄存器中能产出两个结果放到ALU的输入端,具体做法是将MEM/WB寄存器的输出值转发到ALU输入,而EX/MEM寄存器的输出值直接转发到ALU输入上。如下图所示

control hazard是由分支指令引起的,按照原来的结构考虑的话,得到PC结果是在MEM阶段的末尾,所以分支指令要等到前一个指令的MEM执行完才能知道分支到底往哪里跳转。就变成了下图的结果

所以为了早点知道转跳的结果就把计算分支结果的部分从EX阶段搬到了ID阶段,新的结构如下图,在这个结构中,ID阶段就可以知道分支转跳的结果了。所以新的结果在EX阶段就可以给分支语句使用了所以流水线的执行就变成下图的状况。

其中分支语句中会出现两个IF阶段,这是因为第一个IF阶段是分支下一条语句,但是当CPU知道了下一条指令的时候就会再重新取一次目标指令的地址,而当前这条指令就被遗弃掉。这一个重复的IF周期其实也可以利用,我们可以在分支语句判断之前就预测下一条要执行的语句是否为分支语句中的语句,在这个方法下,如果成功预测那么执行过程就不会由任何暂停周期,而不正确的话就会跟前面没有预测一样会有一个额外的周期。另一个方法是利用这一个branch delay slot来执行一个一定会执行且和branch判断无关的语句。这样就能稳定地利用这一个额外地周期,这个方法考验的是编译器的能力,看其如何能找到符合要求的语句就很重要,不过现在的处理器由于流水线太深,导致这个slot变得很长,但是要找那么多语句填满这个空白就会很难,所以趋势就是干脆不用这个技术了,大多数用动态预测来处理。
在出现异常的时候我们得写点程序来处理这些异常(跟中断的思想是一样的)。在这里主要有两种处理异常的方式:precise exception 和 imprecise exception。这两者的区别就是前者需要对断点进行保护,前面正确的语句处理完,等等操作来保证处理完异常之后可以重新回到错误的地方执行。而imprecise exception直接就把在流水线中没有处理完的语句全都给放弃掉,直接处理异常,这样的操作虽然不能重启但是在非常需要实时性的场合很实用,尤其是应急系统中。在处理异常的时候就像在单片机里处理中断一样,只要有异常,立马就把相应的寄存器位置位,所以异常处理的顺序是根据异常发生的顺序来执行的,跟指令的顺序倒是关系不大
除了integer数据以外我们在使用汇编语言的时候还需要使用浮点数据。处理浮点数据的操作是需要和integer数据分开处理的,因为处理浮点数据比integer要复杂所以会需要更多的迭代周期来处理,浮点操作。又由于这个处理数据的EX阶段的操作是不同的硬件unit来处理,所以不同的操作可以在同一时间在EX阶段处理数据。如下图所示的结构。

另外有些多周期迭代的EX单元也是有流水化的,这意味着一个EX单元有许多个小部分,同类的操作进入EX阶段也可以流水化执行,但是也有些操作没有流水化,一般是DIV操作,这就是说这个单元一次只能进行一个DIV的操作。讲其再放大看就是像下图一样的结构了。其中DIV是没有流水化的部分,所以除法只能一个一个做。

如果说运用了这样的结构就会产生很多的问题,因为从上图可知整型加减法只需要一个clock cycle,浮点操作通常需要很多个周期的操作。就有可能造成数据上的错位等等问题,例如下面的例子中在第10和11个周期中有三个指令同时用到了MEM和WB阶段。一般而言,解决这种问题有两种方法,一种是增加硬件的访问通道(这个会很花钱),另一种是干脆等一等加入stall周期就好了。除了这种问题可能还会出现WAW data hazard或者是RAW data hazard的问题,所以在ID阶段会设有hazard检测,来检测structure hazard 和上两种data hazard。

在流水线的实现过程中会遇到一些比较难处理的问题。第一个问题就是流水化过程中异常的处理问题,当某一条指令发生异常时会由一个restart machine来对异常指令和其前后的指令进行一系列操作,使得其在异常时程序停止运行,处理完异常后重新回到原处继续执行程序,具体分为两个步骤:
- 停止程序的运行,在异常指令的下一个指令的IF阶段设立一个trap instruction来引导程序进入异常处理,并且关闭异常指令和其后执行的指令的读写通道,并且保存异常指令的PC值
- 返回PC处,并且重新运行异常后一条指令,得到异常处理完之后的正确结果。
在处理的时候还会遇到一个异常发生顺序的问题,因为在运行过程中,各个指令在流水线中是一个阶段一个阶段地执行,那么就有可能发生后一条执行某个阶段出现异常,然而恰好其前一个指令的某个阶段也出现异常,而后一条指令这个阶段发生在前一个阶段之前。如果说这种情况直接处理异常的话就会导致异常处理的顺序和正常非流水化程序处理顺序不一样,这样显然不可接受。为了保证异常处理顺序不乱,这里为每一个正在执行的指令引入了一个指令状态寄存器来检测指令的异常状态,当出现异常时,不会立马就处理,而是状态寄存器顺着流水线向下一阶段一阶段走,直到MEM的末尾或者是进入WB阶段,会对这个寄存器进行检测,如果有异常那么就会处理。由于MEM和WB是根据程序运行的顺序固定好的,所以异常发生的阶段与程序运行的顺序不一致就不会导致异常处理的不一致了。
上述处理异常的过程是一个精确异常的过程,保证这个的原因是为了保证程序要能够重启。相对的会有非精确异常,其常用于在动态调度乱序执行的情况下处理异常。
精确异常需要保证:
1> 异常指令前的程序要执行完
2> 必须能够从scratch寄存器中重启,且重新运行异常指令的后一条指令
对于使用了动态调度算法的处理器中要实现精确异常是很困难的,主要是因为动态调度的指令状态和非流水线运行时的指令状态不完全一致,导致在返回原点执行的时候没办法还原状态。其特点如下:
1> 异常指令之前的指令可能没有完成
2> 异常指令之后的指令可能已经完成了
但是虽然如此,精确异常会花费相对于非精确异常10倍的时间来处理异常,所以一般而言精确异常应用于调试程序过程,非精确异常可用于处理一些应急事件。
2. 流水线的指令级优化技术
流水线主要的参考指标是流水线处理的速度,而影响速度的一方面是处理器的硬件的处理速度,另一方面是我们在硬件功能规划上尽量让处理器不要停下来等待,而是一直保持最佳状态运行下去。这一类的改进目前主要有两类,一类是在指令调度上下功夫,尽量去错开可能会产生暂停的语句,而另一类是在分支上下功夫,前面也说了分支方面即使是说做了那么一些改动,但是还是会有暂停的现象,所以要么就好好利用这个等待时间,要么就预测分支,反正对了我能剩下一部分时间,错了就大不了和原来一样呗,等就是了,总比啥都不做好。
要进行这样些优化首先要明白等待是因为什么,在程序的层面来看是因为上面章节中所说的一些hazard,而hazard产生的原因是dependence,但是dependence 不一定会产生hazard,hazard也不一定会引起程序的暂停。其主要的功能是
主要的dependence 有三类:
1. data dependence:
这类dependence是因为前后语句使用的寄存器读取和使用的顺序因为流水化和重叠执行的原因有些结果前一个指令还没做完后面的语句就得用而造成的,这类dependence 一定是两条指令之间有数据流动的。
其引起data hazard的类是RAW dependence,如下图例:

2. name dependence
这一类是发生在两个没有数据流动的指令之间的,但是依旧是会导致寄存器里的数据混乱,因为写同一个寄存器没有按照指令逻辑顺序写而发生的,可能会引起data hazard的是有两种:WAW(输出相关)和WAR(反相关)。


要解除这两种dependence通常用的方法是寄存器重命名,说白了就是把上面涉及的重复的寄存器其中一个换一个另外的寄存器即可。
3. control dependence
这个就是为了保证分支和其他语句的逻辑而使得分支语句和其他语句的顺序不能随便乱排。所以其实这个dependence是没有引起stall的。
分支优化
分支优化技术主要有两种,一种是动态分支预测,另一种是静态预测。静态预测是实现设计好之后就不变了,这个需要编译器在编译的时候就做好工作,而动态分支预测则需要改变硬件电路。
1. 静态预测
这个和之前说的delay branch slot 技术和rescheduling技术可以混起来用,这样会比较好一点。主要的静态预测原理就是在编译的时候就已经基于人工经验预测taken或者untaken,后期就不再改了。这个方法就很佛系就是了。
2. 动态预测
动态预测的方法有很多主要有一下几种:
- BHT(branch history table)
每一个branch指令都对应了BHT中的一个单元,这个单元可以有好几个bit用于记录这个branch是的历史这几个bit叫做predictor,这个predictor其实是一个sturating counter, 这个计数器计数到顶或者底的时候再加或者再减都会保持一个状态不再变化。预测的标准很简单就是以一半为界,不管是几位的都是一样。taken计数超过一半就会预测为taken,untaken计数超过一半就会预测为untaken。拿两位的来说,这个可以看作一个下图所示的FSM

另外还有一个问题就是如何找BHT的entry。这个要看entry的大小比如说有一个1k大小的BHT那么entry就可以用10bit地址线进行编码,那么也就是说用指令地址的最低10bit来判断分支指令在BHT中是在什么位置。
- 相关预测(correlating predictiors)
这个预测的主要思路是用当前分支之前的几条分支结果来作为预测依据。拿(m,n)预测来举个例子,这里m表示使用前面的m个分支进行预测,共有2^m个predictor,每一个用来预测的predictor的大小为n bit。拿(2,2)预测来举个例子,那么目前的分支预测结果就是由前两个分支决定,前两个分支是否被taken就有2^2种组合方式(这是个移位寄存器,检测到一次结果就往后推一个),每一个组合方式下有一个n bit的计数器来记每一种组合出现的次数。然后可以根据次数来判断当前我们需要的指令是taken还是untaken。结构如下图所示,假设这个表是3bit寻址。

- 分支目标缓存器(Branch-target buffer)
这个很简单,在硬件中加一个表格,表中记录了所有的分支指令的地址和其预测的吓一跳指令的地址,每执行一个指令就会将指令的地址和表中的地址一一对比,如果在表中,则说明是分支指令,接下来就会对应找到预测出的要存在PC中的地址,并转跳过去。(这个地方我的理解是之前的两种方法用于预测,预测出来的结果会在这个表中更新,而不是作为一种新的预测方法来归类)
调度优化
与前面的同理,调度优化也分为静态优化和动态优化两种,静态调度基于编译器,而动态调度基于硬件。
1. 静态调度
静态调度原理是在编译的时候改变指令的顺序,使指令之间的不再有dependence。第一种方法实现去相关就是将程序看成一个一个basic block组成的,这一个block中一般有4到7条指令(因为这是最可能发生相关的情况),但是这个basic block也有条件,就是出口和入口不能有分支转跳指令。第二种方法是针对循环语句来的,即loop unrolling这个方法首先可以避免过多的分支判断语句出现在程序中(分支语句可能会存在一个多余的IF阶段,所以太多的话可能会浪费时间),另一方面可以在循环体中进行重新调度指令顺序,使得它们不再相关。第三种方法也是针对这个循环的,这种方法称为SIMD(single instruction stream, multiple data stream),能用这一套方法的处理器有两种一种是向量处理器另一种是GPU,其思想是将多个数据排列成一个向量输入处理器中,经过向量运算并行处理后,输出也是一个向量。
2. 动态调度
我们换一个角度来想优化这个事情。在运行的过程中,我们会发现有些指令确实是由于数据没出来而被暂停了,但是有另一些指令是因为前一个指令的工作没做完导致占用资源不放手导致后面的指令即使没有冒险和dependence要跟着一起暂停,就如下面图中所示的几个指令

所以为了解决这个问题我们需要允许程序乱序执行同时不影响执行的结果和逻辑。要实现这一功能我们的硬件电路要将 ID阶段需要分开成两个阶段
issue(发射):解码指令,检查是否由structure hazard
read operand(读操作数):如果检测出没有数据冒险,就开始读取操作数
处理数据冒险的过程如下:
- issue阶段从寄存器或者队列中读取指令,在这个阶段先来的指令就先issue
- 随后这些issue的指令会等待操作数,即进入read operand阶段,在这个阶段数据会通过旁路技术或者stall解决data hazard
- 当这些操作数全都可以用了就进入到EX中
- Tomasulo 算法
要理解这个算法首先有几个硬件概念需要知道。
第一个是保留站(reservation station),这个东西相当于一个buffer,用于存储正在等待操作数的指令,在运行过程中指令存在一个FIFO栈中按顺序issue,随后就堆放到保留站中,如果后面有指令的操作数足够且能够执行那么,后面的指令会越过这条指令先执行。另一个概念是CDB(common data bus),在指令计算出结果后,指令会将自己计算出的结果在CDB上广播给正在等待数据的保留站和寄存器,相当于一个数据旁路的作用使数据在计算出来的第一时间可以被指令当成操作数利用起来。
算法的硬件结构图如下所示:

对于一般的运算语句,在这里需要经过4个phase(这里的一个phase并不是一定是一个周期,可能会有多个周期):
- IF(取指):将指令从内存中取出放入一个FIFO的堆栈中
- Issue(发射):看保留站是不是有位置,如果有位置那么从FIFO栈中顺序取出指令放入保留站中
- Execute(执行):等待操作数,如果操作数能用了就会放到操作单元中进行运算
- Write result(写结果):运算完成后,将结果广播在CDB上,随后传给需要的register和保留站
另外保留站是这个算法的核心部件,其解决了后面指令等待的问题。当前一个指令被操作数原因堵住的时候,有一个指令只要一能执行立马就会运作起来。保留站主要有7个部件:
OP:记录操作类型种类
RS1和RS2:记录需要读取的操作数来自于哪一个保留站
Val1和Val2:如果保留站的值能够读取就会在这两个地方进行记录并将相应的RS置零
Imm/Addr:立即数和地址记录在这里
Busy:记录保留站的状态,如果里面有东西就记为忙碌状态
FP register也有和保留站相似的结构但是只有两个部件:
RS:记录需要读取的操作数来自于哪一个保留站
Val:如果保留站的值能够读取就会在这两个地方进行记录
对于Load/Store操作,这由两个步骤组成
- 计算物理地址(EA)
- 访问存储器
为了支持这样的操作,于是分别对于load和store都加了一个buffer,结构如下。在Store Buffer里得Val可以由RS产生,RS也可以等待Load Buffer里的值。
Load操作:
- 计算EA
- 比较Store Buffer中的A,如果有匹配到的话就表示可能会有RAW,这个load就不会被发送到load buffer中去,直到这个冲突解决为止
Store操作:
- 和上面一样,只是说要同时检查Store Buffer中的值和Load Buffer中的值,避免WAR和WAW。

3.基于tomasulo算法的结构改进
> 多发射
在消除data dependences和control dependences导致的停顿后处理器的CPI会越来越近似1,但是如果说每一个周期内只发射一条指令的话这个CPI就不能更小,所以为了进一步缩小CPI就需要一次性多issue几个指令。目前市面上比较多的是以下几种:

> 基于硬件的预测
这个玩意相当于动态调度算法的扩展插槽,其在原有write back阶段分离出了一个commit阶段,计算所得到的所有结果也不会直接放到register file中而是先放到一个reorder buffer中等待commit,在这个commite阶段之前所做的一切都是可以改的,如果说预测不正确,那么就可以将存在reoder budder中将错误的结果给改掉然后再commit。这个东西显然得搭配上动态预测或者静态预测使用,其主要就是为了解决控制相关在预测错误的时候带来的延迟问题,而使用了这个方法后就可以将运行看做是一直都判断正确了。硬件预测主要基于以下三个关键的思想:
- 用动态分支预测选择要执行哪些指令
- 用推测处理在控制指令判断之后需要执行的指令
- 用动态调度来解决在basic block中的不同指令组合执行问题
其与原先的tomasulo不同的地方在于这里先把一些依照原先程序执行的顺序将结果放到reorder buffer中,放在reorder buffer中的数据也能用,只是说可能会在commit之前改掉而已。然后再按顺序commit,得到确认好的数据依次再到register或者memory中。
改进之后的结构如下图所示:

ARM汇编编程(基于恩智浦LPC1768)
1.ARM V7 寄存器结构
通用寄存器结构:

其中R0~R12用作通用寄存器用于暂存数据和进行运算。R13位堆栈指针的地址,在堆栈操作时会改变值。R14是连接寄存器,用于子程序的处理,在调用子程序时其会将主程序的PC值存进去。R15为当前PC执行地址。
特殊寄存器结构:

xPSR是状态寄存器,其实包含了三个不同的寄存器分别为APSR(application)\IPSR(interrupt)\EPSR(execution)用于表明各个部分的状态。
在ARM V7架构下的数据有:byte(8 bits), halfword(16 bits), word(32 bits)
寄存器带宽为32位
指令集只支持thumb和thumb-2指令集,其中就包含了16bits 指令和32 bits指令
2. ARM汇编指令的操作
汇编指令集主要包含有三种不同的指令:instruction, pseudo-instruction, directive
其中只有instruction是有对应的机器码可以翻译成101010这样的程序的,其他两种都是给编译器看的,可以引导编译器的行为。
directive
常用的有
- AREA(定义段)
area 段名 {段属性1} {段属性2}
段属性主要有两类:
表明段内容是什么 code,data,stack,heap
表明段是不是可以读写 readonly, readwrite, writeonly
- RN(寄存器重命名)
RN {新寄存器名},{寄存器编号}- EQU(定义常量)
- DCx(定义变量或变量数组)
x的参数表明了变量需要预留空间的大小: B(byte), W(halfword), WU(halfword unsigned), D(word), DU(word unsigned)
- ALIGN(用于数据对齐)
- SPACE(用于预留空间)
pseudo-instruction
存取memory中的数,其存储顺序是从低地址到高地址

如果需要连续存取数据就要控制好指示存取地址的寄存器内容,共有两种方式来控制
- pre-indexing adddressing [Rn,offset] {!} (这个感叹号可以选择是否Rn更新)(先加后存)
- post-indexing addressing [Rn],[offset] (先存后加)
instruction
1. MOV,MVN,MOVW,MOVT
- MOV和MVN操作数的要求
- 8位数据
- 8位数移位得到的结果
- 数据格式为 00xy00xy, xy00xy00或xyxyxyxy之间的一种
- MOVW和MOVT的要求
- 16位数据
- MOVW填充寄存器的低16位,MOVT填充寄存器的高16位
- LDR除了从memory中加载数据也可以直接加载常数,加载常数时如果参数符合MOV或MVN的数据条件和格式,编译器会把LDR翻译成MOV或者MVN,如果不符合就会自动在程序末尾创建一个文字池(literary pool),并从中导入数据。
2. 计算指令(查表即可)
大多数计算指令是不能影响标志位的,除了CMP和TST,如果要影响标志位那么就需要在指令的末尾加一个S的后缀。另外在表中还有一些组合指令,可以用来精简程序结构。
3. 分支指令BL,B,BLX,BX
有没有X的区别在于能跳转的范围不同,加了X后缀的可以调用所有4GB范围内的子程序或者分支。flag就是计算时用于指示结果性质的标志位了。
另外的后缀可以在下表中找到

B系列用于调用分支;BL系列用于调用子程序,其会将主程序断点的PC值保存到LR寄存器中。
4. 堆栈和出栈 LDMxx/SMTxx,PUSH,POP
对于LDMxx/SMTxx是堆出栈指令的原本的版本,后面的xx是可以配置的选项,可选项有两个
-IA(increase after):指针指向的位置先存进去,再移动指针
-DB(decrease before):先移动指针位置,再存数据
其格式如下所示:
LDMxx/STMxx <Rm>{!}, {reglist}
其中{!}表示是否在存储后更新寄存器的值,没有!就不会一直保存寄存器的值;
reglist是你想放在堆栈里面的寄存器,这个list是自动排序的,从R0开始往上排,格式为
{R0-R3,R4,R5,LR}
在这里面可以用寄存器的别名,LR其实是R13PUSH{reglist}=STMDB SP!,{reglist}
POP{reglist}=LDMIA SP!,{reglist}
子程序
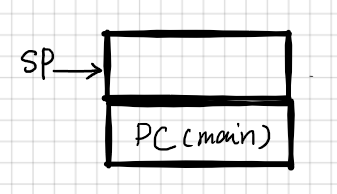
子程序的调用需要用BL或者BLX来实现,一般很长的程序才会用BLX。子程序的调用格式一般如下,BL的工作是当前指令的下条指令地址存在LR中,然后转跳到子程序中。而在子程序中将LR寄存器的值放到堆栈中就保证了在子程序中还能继续调用子程序,其堆栈步骤分析如图所示
*****主程序*****
...
BL function
...
END
*****子程序块*****
PROC function
PUSH {Rx-Ry,LR}
...
POP {Rx-Ry,PC}
ENDP

1. BL将PC(main)放入BL,并把f1标号的地址放在PC中;f1将LR(PC(main))放入堆栈中

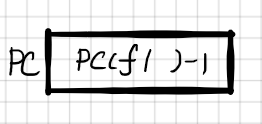
2. 把f1中的PC值放入LR寄存器,把f2标号的地址放入PC中;f2将LR(PC(f1))放入堆栈中

3. 将放入堆栈的f1地址弹出至PC中

4. 将放入堆栈的Main函数地址弹出至PC

如果说需要向子程序传递参数的话虽然说有毕竟是汇编程序有一定的自由度可以自己选择,到底是用寄存器直接传参数还是用堆栈又或是用memory传。但是寄存器这个最简单的方法有时候并不适用于过多参数的传递,尤其是在与C语言混合编程的时候,C语言是没有参数个数限制的。所以有一个标准制定出来方便统一标准和模式进行传参,这就是AAPCS。这个标准其实有两个版本,一个是ARM32另一个是ARM64,这里就只讲讲关于这个芯片的了,ARM32标准的内容如下:
- R0-R3:程序通过这4个寄存器传递前4个参数,其余参数通过堆栈传递
- 程序输出的结果:32bit结果放到R0, 64bit结果放到R0和R1中, 128bit结果放到R0-R4中
- R4-8R, R10, R11:程序使用这几个寄存器用于存储局部变量
- R9用处跟平台相关,一般来说可以用作普通的寄存器
子程序三种参数传递方式
- 寄存器
直接放到寄存器R0-R3中就可以拿来用了。easy...
- 存储器
****主程序****
...
mov r0,#0x34
mov r1,#0xa1
ldr r3,=myspace
stmia r3,{r0,r1};这里把参数放进去
bl sub2
ldr r2,[r3]
...
****子程序****
sub2 proc
push{r2,r4-r8,lr}
ldmia r3,{r4,r5};把参数对应取出来放到r4,r5里去
...
pop{r2,r4-r8,pc}
endp- 堆栈
****主程序****
...
mov r0,#0x34
mov r1,#0xa1
push {r0,r1};压栈参数
bl sub2
pop {r0,r1}
...
****子程序****
sub2 proc
push{r4-r8,lr}
ldr r4,[sp,#24]
ldr r5,[sp,#28];这两句提取堆栈中自己需要的参数
...
pop{r4-r8,pc}
endp
3. 异常处理
(这一块我就留个坑好了。为什么?因为考试不考,回头用到再回来填坑,其实这个东西很容易理解,就理解成中断操作就好了,只不过回有固定的名字,处理的东西是一些异常事件而不是中断事件而已)
4. 混合编程
混合编程在嵌入式领域是一个非常重要的技术,可以让我们更容易接触到最底层的寄存器操作,从而对在指令层级上的优化更加简便。尤其在需要很强实时性的领域,人为的优化显得尤为重要。
1. 在C程序中调用汇编函数
****c程序****
#include "lpc17xx.h"
extern void func1(void);
import int func2(int a, int b);
void main(void)
{
int k;
func1();
k=func2(2,3);
}
****汇编程序****
func1 proc
export func1 [weak]
push {Rm-Rn,LR}
...
pop {PC}
endp
func2 proc
export func2 [weak]
push {R2-Rn,LR}
;在这个函数中可以用R0,R1的值作参数了
...
;结果放到R0中相当于c函数中的return
pop {PC}
endp
2. 在汇编语言中调用C函数
****C程序****
void func1(void);
int func2(int a,int b);
void func1(void)
{
...
}
int func2(int a,int b)
{
...
}
****汇编程序****
eset_Handler PROC
EXPORT Reset_Handler [WEAK]
EXPORT func1 [WEAK]
EXPORT func2 [WEAK]
...
BL func1
...
MOV R0,#2
MOV R1,#1
BL func2
...
stop B stop
end 3. 在C程序中写汇编语句
>单句
_asm("mov R1,R2; sub R3,R4,R1")
或者
_asm{mov R1,R2; sub R3,R4,R1}>多句
_asm{
mov r1,r2
add r3,r4,r5
}需要注意的是在这种编辑方式下会有一些不支持的语句:
- BX;BXL
- 用于传递变量值的LDR
- 乘法指令及其组合指令
- 用常数和MOV(MVN)对flag寄存器进行赋值
- ADR和ADRL
>在C程序中定义汇编函数
_asm int func1(int a, int b)
{
mov r0,r1
...
}















 3862
3862











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









