







前言
豆瓣作为国内知名的文化社区,拥有庞大且丰富的图书数据资源。这些数据涵盖了图书的分类、标签、详细信息以及用户的评价等多个维度,为我们深入了解图书世界提供了宝贵的素材。然而,原始的豆瓣图书数据往往存在格式不规范、信息缺失、数据重复以及异常值等问题,这些问题会严重影响数据的质量和后续的分析与应用。
为了充分挖掘豆瓣图书数据的价值,我们需要对其进行一系列的清洗和处理工作。通过对数据的全面检查和针对性处理,我们可以解决数据中存在的各种问题,使数据更加完整、准确和一致。本项目围绕豆瓣图书数据集展开,详细阐述了从数据的初步查看、各列数据的处理(包括拆分、格式转换、异常值处理等),到缺失值和重复值的处理,以及最终将处理后的数据保存到数据库的整个过程。
一、查看数据基本信息
def data_info(data):
"""
打印数据的前几行、列名和基本信息。
:param data: 待分析的DataFrame数据
"""
print("数据前几行:")
print(data.head().to_csv(sep='\t', na_rep='nan')) # 使用制表符分隔,方便查看,缺失值用nan表示
print("数据列名:")
print(data.columns)
print("数据基本信息:")
data.info()
数据前几行如下所示:
数据前几行:
category_name url img_url name pub rating rating_count plot buy_info
0 J.K.罗琳 https://book.douban.com/subject/35671734/ https://img9.doubanio.com/view/subject/s/public/s34048686.jpg 哈利·波特与死亡圣器 J.K. 罗琳 / 中国图书进出口总公司 / 2016-8-1 / 30.00元 9.6 (310人评价) 「“把哈利·波特交出来,”伏地魔的声音说,“你们谁也不会受伤。把哈利·波特交出来,我会让学校安然无恙。把哈利·波特交出来,你们会得到奖赏。”」当哈利·波特攀... nan
1 J.K.罗琳 https://book.douban.com/subject/27625554/ https://img3.doubanio.com/view/subject/s/public/s33973792.jpg 神奇动物在哪里(插图版) [英]纽特·斯卡曼德 / 一目、马爱农 / 人民文学出版社 / 2018-3 / 45.00 8.5 (483人评价) 《神奇动物在哪里》是“哈利·波特”系列*著名的官方衍生书。它是哈利·波特在霍格沃茨魔法学校的指定教材,由J.K.罗琳(化名纽特·斯卡曼德)撰写。 这一全新的... 纸质版 25.00元
2 J.K.罗琳 https://book.douban.com/subject/27594566/ https://img1.doubanio.com/view/subject/s/public/s32311010.jpg 诗翁彼豆故事集(插图版) [英]J.K.罗琳 / 马爱农 / 人民文学出版社 / 2018-3 8.9 (721人评价) 《诗翁彼豆故事集》是“哈利·波特”系列的官方衍生书。它是魔法世界家喻户晓的床边故事集,也是邓布利多留给赫敏·格兰杰的礼物。书中故事均由J.K.罗琳撰写。 这... 纸质版 25.00元
3 J.K.罗琳 https://book.douban.com/subject/35909174/ https://img1.doubanio.com/view/subject/s/public/s34330260.jpg 哈利·波特与被诅咒的孩子 [英] J.K.罗琳、[英] 约翰·蒂法尼、[英] 杰克·索恩 / 马爱农 / 人民文学出版社 / 2022-6 / 69.00元 7.0 (84人评价) 第八个故事。 十九年后。 十九年前,哈利·波特、罗恩·韦斯莱和赫敏·格兰杰携手拯救了魔法世界;如今,他们再次踏上了一场非同寻常的冒险旅程。这次与他们同行的,... 纸质版 40.40元
4 J.K.罗琳 https://book.douban.com/subject/26984868/ https://img9.doubanio.com/view/subject/s/public/s29443244.jpg 神奇动物在哪里 [英] J. K. 罗琳 / 马爱农、马珈 / 人民文学出版社 / 2017-4 / 58 8.3 (1346人评价) 读懂“哈利·波特”,从前传开始 《神奇动物在哪里》 J.K.罗琳首次挑战电影编剧 纽特·斯卡曼德邀请你一同探索魔法世界新纪元! 冒险家、神奇动物学家纽特·... 纸质版 32.00元
数据列名如下所示:
数据列名:
Index(['category_name', 'url', 'img_url', 'name', 'pub', 'rating',
'rating_count', 'plot', 'buy_info'],
dtype='object')
数据基本信息如下所示:
数据基本信息:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 129839 entries, 0 to 129838
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 category_name 129839 non-null object
1 url 129839 non-null object
2 img_url 129839 non-null object
3 name 129827 non-null object
4 pub 129436 non-null object
5 rating 111810 non-null float64
6 rating_count 129839 non-null object
7 plot 119919 non-null object
8 buy_info 93330 non-null object
dtypes: float64(1), object(8)
memory usage: 8.9+ MB
二、拆分pub列
# 拆分pub列的函数
def split_pub(pub):
"""
拆分pub列,根据不同的分隔符和格式提取作者、译者、出版社、出版日期和价格信息。
:param pub: pub列的单个值
:return: 包含提取信息的Series
"""
if pd.isna(pub):
return pd.Series([None, None, None, None, None],
index=['author', 'translator', 'publisher', 'publish_date', 'price'])
author = translator = publisher = publish_date = price = None
if '/' in pub:
parts = pub.split('/')
if len(parts) == 5:
author, translator, publisher, publish_date, price = parts
elif len(parts) == 4:
if '.' in pub:
author, publisher, publish_date, price = parts
else:
author, translator, publisher, publish_date = parts
elif len(parts) == 3:
if '.' in pub:
author, publish_date, price = parts
else:
author, publisher, publish_date = parts
elif len(parts) == 2:
if '-' in pub and '.' in pub:
publish_date, price = parts
else:
publisher, publish_date = parts
else:
if '-' in pub:
publish_date = pub
elif '出版社' in pub:
publisher = pub
else:
price = pub
return pd.Series([author, translator, publisher, publish_date, price],
index=['author', 'translator', 'publisher', 'publish_date', 'price'])
三、日期列处理
此函数用于处理日期列,将日期字符串转换为有效的图书发布年份。会对输入的日期字符串进行格式检查,提取年份部分,并验证年份是否处于合理范围(1900 - 2025),若不符合要求则返回 None。
def process_date(date_str):
"""
处理日期列,提取年份并进行有效性检查。
:param date_str: 日期字符串
:return: 有效的年份或None
"""
if pd.notna(date_str):
date_str = date_str.strip()
try:
year_str = date_str[:4]
if len(year_str.strip()) != 4:
return None
year = int(year_str)
if 1900 <= year <= 2025: # 检查年份范围
return year
except ValueError:
pass
return None
四、价格列处理
此函数的作用是处理包含价格信息的字符串,从其中提取有效的价格,并对提取出的价格进行有效性检查。 包含价格信息的字符串,通常是类似 “纸质版 39.8 元” 这样的格式。若字符串中包含有效的价格信息且价格在合理范围内,返回该价格(浮点数类型);若价格超出合理范围,返回设定的上限价格 2000;若字符串为空值、格式不符合要求或在处理过程中出现错误,返回 None。
def process_buy_info(buy_info_str):
"""
处理价格信息,提取价格并进行有效性检查。
:param buy_info_str: 包含价格信息的字符串
:return: 有效的价格或None
"""
if pd.notna(buy_info_str):
buy_info_str = buy_info_str.strip()
try:
price_str = buy_info_str.split(' ')[1].split('元')[0]
price = float(price_str)
if price <= 2000: # 检查价格范围
return price
return 2000
except (IndexError, ValueError):
pass
return None
五、出版社列处理
该函数用于处理数据集中的出版社列信息,对传入的出版社信息字符串进行检查,去除其中包含无效信息的部分,筛选出有效的出版社信息。出版社信息的字符串可能是正确的出版社名称,也可能包含如日期等无效信息。若字符串是有效的出版社信息,则返回该字符串;若字符串为缺失值或者包含无效信息(如“年”或“-”),则返回 None。
def process_publish(publish_str):
"""
处理出版社列,去除无效信息。
:param publish_str: 出版社信息字符串
:return: 有效的出版社信息或None
"""
if pd.notna(publish_str):
publish_str = publish_str.strip()
if '年' not in publish_str and '-' not in publish_str:
return publish_str
return None
六、评价人数列处理
该函数的主要作用是处理包含评价人数信息的字符串,将不同格式的评价人数描述转换为对应的整数形式,以便后续的数据处理和分析。如果输入的字符串为空值或者无法正确转换为整数,则返回 None。
def process_rating_count(rating_count_str):
"""
处理评价人数列,将不同格式的评价人数转换为整数。
:param rating_count_str: 评价人数信息字符串
:return: 评价人数的整数表示或None
"""
if pd.notna(rating_count_str):
rating_count_str = rating_count_str.strip()
if rating_count_str == '(少于10人评价)':
return 10
elif rating_count_str == '(目前无人评价)':
return 0
try:
rating_count = int(rating_count_str.split('(')[1].split('人')[0])
return rating_count
except (IndexError, ValueError):
pass
return None
七、缺失值处理
该函数的主要功能是处理输入的DataFrame数据中的缺失值。针对数据中的不同列,采用不同的策略来处理缺失值,以提高数据的质量和可用性。
缺失值统计情况如下:
缺失值情况:
category_name 0
url 0
img_url 0
name 12
rating 18029
rating_count 0
plot 9920
author 3842
translator 63390
publisher 15669
publish_year 15801
price 36509
dtype: int64
对于图书名称列的缺失值,使用dropna方法,指定subset为[‘name’],即删除’name’列中值为缺失值的行。
对于作者列的缺失值,首先使用replace方法,利用正则表达式r’^\s*$'匹配空字符串(包括只包含空白字符的字符串),将其替换为pd.NA(表示缺失值)。然后再使用dropna方法,删除’author’列中值为缺失值的行。
对于评分列的缺失值,使用groupby方法按’category_name’分组,然后对每个组内的’rating’列进行操作。通过transform方法,对每个组内的缺失值使用该组的评分均值(保留一位小数)进行填充。
对于情节简介列的缺失值,使用fillna方法,将’plot’列中的缺失值填充为字符串’未知’。
对于译者列的缺失值,先使用replace方法,将空字符串(包括只包含空白字符的字符串)替换为pd.NA。然后使用fillna方法,将缺失值填充为字符串’无译者’。最后使用apply方法,对每一个译者字符串应用lambda函数,去除字符串前后的空格。
对于出版社列的缺失值,类似作者列的处理方式,先将空字符串替换为pd.NA,然后删除该列中值为缺失值的行。
对于出版年份列的缺失值,按’category_name’分组,对每个组内的’publish_year’列的缺失值使用该组的中位数进行填充。
对于价格列的缺失值,按’category_name’分组,对每个组内的’price’列的缺失值使用该组的均值(保留两位小数)进行填充。
缺失值统计及处理代码如下:
def process_null_data(data):
"""
处理数据中的缺失值,根据不同列采用不同的处理方法。
:param data: 待处理的DataFrame数据
"""
# data_info(data) # 查看处理前的数据信息
print("缺失值情况:")
print(data.isnull().sum())
# 处理各列的缺失值
data.dropna(subset=['name'], inplace=True) # 删除图书名称缺失的行
data['author'] = data['author'].replace(r'^\s*$', pd.NA, regex=True)
data.dropna(subset=['author'], inplace=True) # 删除作者缺失的行
data['rating'] = data.groupby('category_name')['rating'].transform(
lambda x: x.fillna(x.mean().round(1))) # 按类别填充评分缺失值
data['plot'].fillna('未知', inplace=True) # 填充情节简介缺失值
data['translator'] = data['translator'].replace(r'^\s*$', pd.NA, regex=True)
data['translator'].fillna('无译者', inplace=True)
data['translator'] = data['translator'].apply(lambda x: x.strip()) # 去除译者前后空格
data['publisher'] = data['publisher'].replace(r'^\s*$', pd.NA, regex=True)
data.dropna(subset=['publisher'], inplace=True) # 删除出版社缺失的行
data['publish_year'] = data.groupby('category_name')['publish_year'].transform(
lambda x: x.fillna(x.median())) # 按类别填充出版年份缺失值
data['price'] = data.groupby('category_name')['price'].transform(
lambda x: x.fillna(x.mean().round(2))) # 按类别填充价格缺失值
print("处理后缺失值情况:")
print(data.isnull().sum())
处理后缺失值情况如下,可以看到已经没有缺失值。
处理后缺失值情况:
category_name 0
url 0
img_url 0
name 0
rating 0
rating_count 0
plot 0
author 0
translator 0
publisher 0
publish_year 0
price 0
dtype: int64
八、重复数据处理
def process_repeat_data(data):
"""
处理数据中的重复值,删除重复行。
:param data: 待处理的DataFrame数据
:return: 处理后的DataFrame数据
"""
print("重复值情况:")
count = data.duplicated().sum()
print(count)
if count > 0:
data.drop_duplicates(inplace=True)
return data
九、异常值处理
def process_outliers(data):
"""
处理数据中的异常值,对评分进行范围限制。
:param data: 待处理的DataFrame数据
"""
print("异常值情况:")
print(data.describe())
data['rating'] = data['rating'].clip(0, 10) # 限制评分范围在0-10之间
十、完整代码
豆瓣图书数据清洗与处理的完整代码如下:
import pandas as pd
from sqlalchemy import create_engine
# 查看数据基本信息的函数
def data_info(data):
"""
打印数据的前几行、列名和基本信息。
:param data: 待分析的DataFrame数据
"""
print("数据前几行:")
print(data.head().to_csv(sep='\t', na_rep='nan')) # 使用制表符分隔,方便查看,缺失值用nan表示
print("数据列名:")
print(data.columns)
print("数据基本信息:")
data.info()
# 拆分pub列的函数
def split_pub(pub):
"""
拆分pub列,根据不同的分隔符和格式提取作者、译者、出版社、出版日期和价格信息。
:param pub: pub列的单个值
:return: 包含提取信息的Series
"""
if pd.isna(pub):
return pd.Series([None, None, None, None, None],
index=['author', 'translator', 'publisher', 'publish_date', 'price'])
author = translator = publisher = publish_date = price = None
if '/' in pub:
parts = pub.split('/')
if len(parts) == 5:
author, translator, publisher, publish_date, price = parts
elif len(parts) == 4:
if '.' in pub:
author, publisher, publish_date, price = parts
else:
author, translator, publisher, publish_date = parts
elif len(parts) == 3:
if '.' in pub:
author, publish_date, price = parts
else:
author, publisher, publish_date = parts
elif len(parts) == 2:
if '-' in pub and '.' in pub:
publish_date, price = parts
else:
publisher, publish_date = parts
else:
if '-' in pub:
publish_date = pub
elif '出版社' in pub:
publisher = pub
else:
price = pub
return pd.Series([author, translator, publisher, publish_date, price],
index=['author', 'translator', 'publisher', 'publish_date', 'price'])
# 日期列处理函数
def process_date(date_str):
"""
处理日期列,提取年份并进行有效性检查。
:param date_str: 日期字符串
:return: 有效的年份或None
"""
if pd.notna(date_str):
date_str = date_str.strip()
try:
year_str = date_str[:4]
if len(year_str.strip()) != 4:
return None
year = int(year_str)
if 1900 <= year <= 2025: # 检查年份范围
return year
except ValueError:
pass
return None
# 价格列处理函数
def process_buy_info(buy_info_str):
"""
处理价格信息,提取价格并进行有效性检查。
:param buy_info_str: 包含价格信息的字符串
:return: 有效的价格或None
"""
if pd.notna(buy_info_str):
buy_info_str = buy_info_str.strip()
try:
price_str = buy_info_str.split(' ')[1].split('元')[0]
price = float(price_str)
if price <= 2000: # 检查价格范围
return price
return 2000
except (IndexError, ValueError):
pass
return None
# 出版社列处理函数
def process_publish(publish_str):
"""
处理出版社列,去除无效信息。
:param publish_str: 出版社信息字符串
:return: 有效的出版社信息或None
"""
if pd.notna(publish_str):
publish_str = publish_str.strip()
if '年' not in publish_str and '-' not in publish_str:
return publish_str
return None
# 评价人数列处理函数
def process_rating_count(rating_count_str):
"""
处理评价人数列,将不同格式的评价人数转换为整数。
:param rating_count_str: 评价人数信息字符串
:return: 评价人数的整数表示或None
"""
if pd.notna(rating_count_str):
rating_count_str = rating_count_str.strip()
if rating_count_str == '(少于10人评价)':
return 10
elif rating_count_str == '(目前无人评价)':
return 0
try:
rating_count = int(rating_count_str.split('(')[1].split('人')[0])
return rating_count
except (IndexError, ValueError):
pass
return None
# 空值处理函数
def process_null_data(data):
"""
处理数据中的缺失值,根据不同列采用不同的处理方法。
:param data: 待处理的DataFrame数据
"""
# data_info(data) # 查看处理前的数据信息
print("缺失值情况:")
print(data.isnull().sum())
# 处理各列的缺失值
data.dropna(subset=['name'], inplace=True) # 删除图书名称缺失的行
data['author'] = data['author'].replace(r'^\s*$', pd.NA, regex=True)
data.dropna(subset=['author'], inplace=True) # 删除作者缺失的行
data['rating'] = data.groupby('category_name')['rating'].transform(
lambda x: x.fillna(x.mean().round(1))) # 按类别填充评分缺失值
data['plot'].fillna('未知', inplace=True) # 填充情节简介缺失值
data['translator'] = data['translator'].replace(r'^\s*$', pd.NA, regex=True)
data['translator'].fillna('无译者', inplace=True)
data['translator'] = data['translator'].apply(lambda x: x.strip()) # 去除译者前后空格
data['publisher'] = data['publisher'].replace(r'^\s*$', pd.NA, regex=True)
data.dropna(subset=['publisher'], inplace=True) # 删除出版社缺失的行
data['publish_year'] = data.groupby('category_name')['publish_year'].transform(
lambda x: x.fillna(x.median())) # 按类别填充出版年份缺失值
data['price'] = data.groupby('category_name')['price'].transform(
lambda x: x.fillna(x.mean().round(2))) # 按类别填充价格缺失值
print("处理后缺失值情况:")
print(data.isnull().sum())
# 重复数据处理函数
def process_repeat_data(data):
"""
处理数据中的重复值,删除重复行。
:param data: 待处理的DataFrame数据
:return: 处理后的DataFrame数据
"""
print("重复值情况:")
count = data.duplicated().sum()
print(count)
if count > 0:
data.drop_duplicates(inplace=True)
return data
# 异常值处理函数
def process_outliers(data):
"""
处理数据中的异常值,对评分进行范围限制。
:param data: 待处理的DataFrame数据
"""
print("异常值情况:")
print(data.describe())
data['rating'] = data['rating'].clip(0, 10) # 限制评分范围在0-10之间
# 保存数据到MySQL数据库的函数
def save_to_mysql(data, table_name):
"""
将处理后的数据保存到MySQL数据库。
:param data: 待保存的DataFrame数据
:param table_name: 数据库表名
"""
engine = create_engine(f'mysql+mysqlconnector://root:zxcvbq@127.0.0.1:3306/douban')
try:
data.to_sql(table_name, con=engine, index=False, if_exists='replace')
print(f'清洗后的数据已保存到 {table_name} 表')
except Exception as e:
print(f"保存数据到数据库时出错: {e}")
if __name__ == '__main__':
# 读取数据
data = pd.read_csv('./原始数据层/豆瓣图书数据集.csv')
# 查看数据基本信息
data_info(data)
# 拆分pub列
data[['author', 'translator', 'publisher', 'publish_date', 'price']] = data['pub'].apply(split_pub)
data.drop(['pub'], axis=1, inplace=True)
data.drop(['price'], axis=1, inplace=True)
data.to_csv('./中间处理层/拆分列后的豆瓣图书数据集.csv', index=False)
data = pd.read_csv('./中间处理层/拆分列后的豆瓣图书数据集.csv')
# 日期列处理
data['publish_date'] = data['publish_date'].apply(process_date)
data.rename(columns={'publish_date': 'publish_year'}, inplace=True)
# 价格列处理
data['price'] = data['buy_info'].apply(process_buy_info)
data.drop(['buy_info'], axis=1, inplace=True)
# 出版社列处理
data['publisher'] = data['publisher'].apply(process_publish)
# 评价人数列处理
data['rating_count'] = data['rating_count'].apply(process_rating_count)
# 空值处理
process_null_data(data)
# 重复数据处理
data = process_repeat_data(data)
# 异常值处理
process_outliers(data)
# 保存处理后的数据
data.to_csv('./中间处理层/清洗后的豆瓣图书数据集.csv', index=False, encoding='utf-8-sig')
# 保存分析后的数据到MySQL数据库
save_to_mysql(data, '清洗后的豆瓣图书数据集')
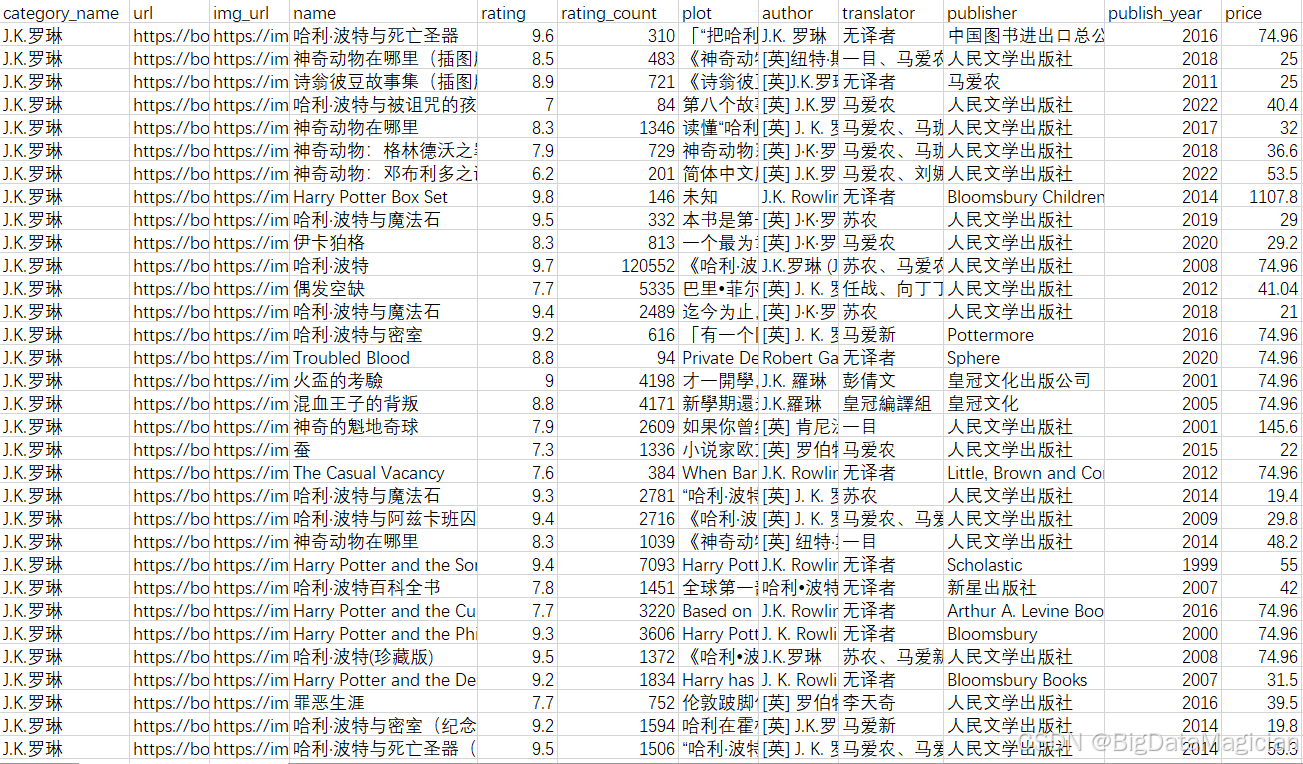
十一、清洗与处理后的数据集展示
清洗与处理后的数据集部分数据如下图所示:


















 332
332

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











