






很想给我的Wordpress文章引用行楷和魏碑等字体,但搜片全网,都没有这些字体的添加范例、好在本尊愿意依照网络热帖的路子甘予尝试,算是找到此一极简的方术。正因为简单几被忽略,今不吝显掰给兴致同修鉴赏。相信将福泽一大波喜欢行楷和魏碑而苦于找不到的wordpress同修。
依照网上Wordpress文章加字体的时髦帖子路数,折腾如下代码:
function add_fontfamily($initArray)
{
$initArray[‘font_formats’] = “微软雅黑=’微软雅黑’;宋体=’宋体’;黑体=’黑体’;仿宋=’仿宋’;楷体=’楷体’;隶书=’隶书’;幼圆=’幼圆’;华文新魏=’华文新魏’;华文行楷=’华文行楷’;华文彩云=’华文彩云’;华文琥珀=’华文琥珀’;Algerian=’Algerian’;Arial=’Arial’;”;
return $initArray;
}
add_filter(‘tiny_mce_before_init’, ‘add_fontfamily’);
将代码贴于当前主题的function.php文件末尾,想要的字体就出来了。
我在阿贝云免费虚拟主机和免费服务器上的Wordpress的成功示例,如图:
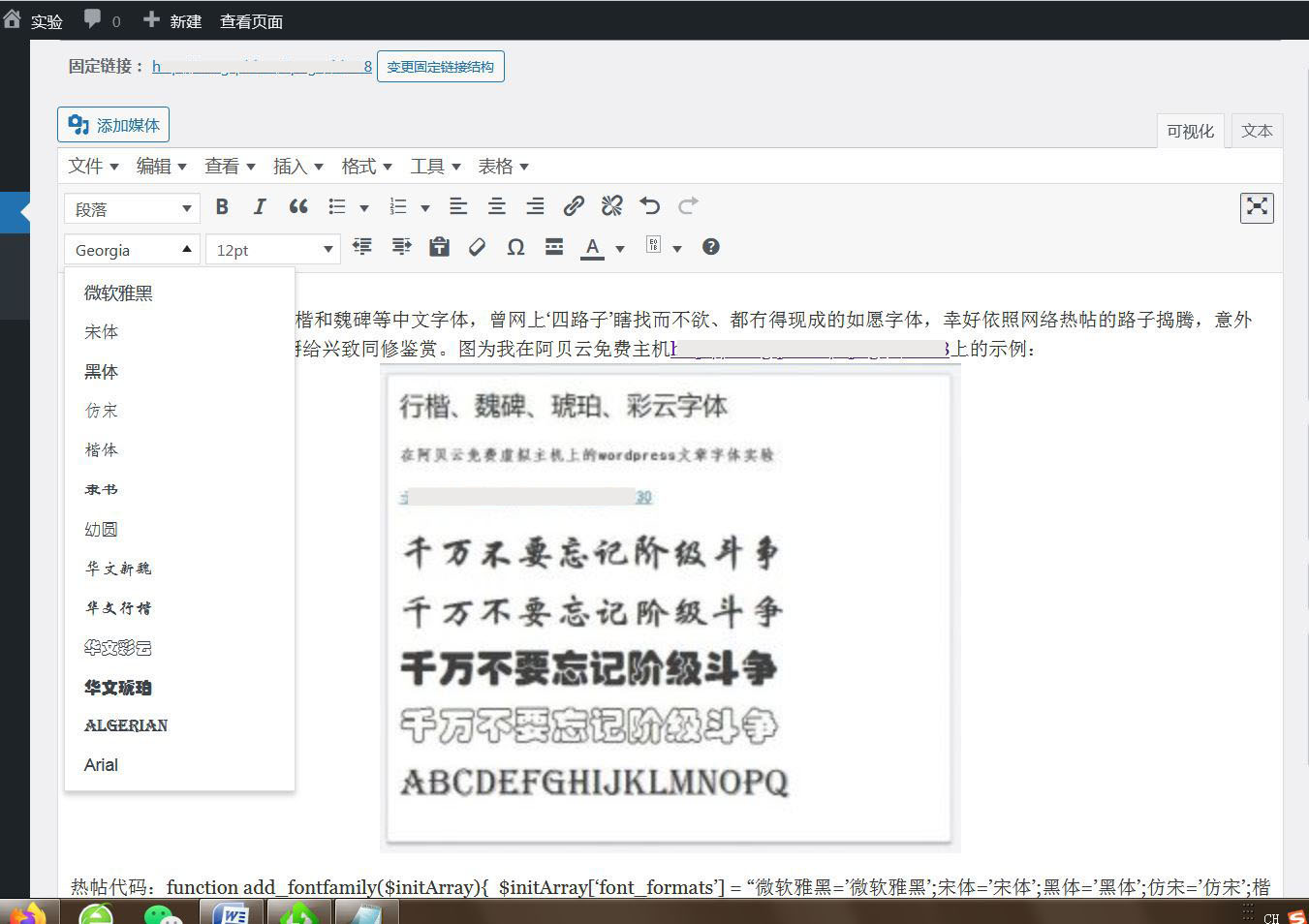
不过,此方法依赖本地电脑字库,浏览Wordpress网站文章的机器得有相应字库,比如手机一般无此类字库,只能遗憾手机浏览冇得字体效果。















 1228
1228











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









