







 2023年7月19日Meta发布开源可商用模型Llama2,它是参数规模不等的生成文本模型集合。本文介绍了几个高star的GitHub开源项目,如FlagAlpha/Llama2 - Chinese、hiyouga/LLaMA - Efficient - Tuning等,这些项目大多有开放数据、可下载商用模型及详细微调过程。
2023年7月19日Meta发布开源可商用模型Llama2,它是参数规模不等的生成文本模型集合。本文介绍了几个高star的GitHub开源项目,如FlagAlpha/Llama2 - Chinese、hiyouga/LLaMA - Efficient - Tuning等,这些项目大多有开放数据、可下载商用模型及详细微调过程。
【大模型】基于 LlaMA2 的高 star 的 GitHub 开源项目汇总
Llama2 简介
2023年7月19日:Meta 发布开源可商用模型 Llama2。
Llama2 是一个预训练和微调的生成文本模型的集合,其规模从70亿到700亿个参数不等。
LLaMA2 的详细介绍可以参考这篇文章:【大模型】更强的 LLaMA2 来了,开源可商用、与 ChatGPT 齐平
下面介绍几个高 star 的 GitHub 开源项目:
star 数量截止日期2023年8月23日
开源项目汇总
NO1. FlagAlpha/Llama2-Chinese
-
star:4.2K
-
介绍:
Llama中文社区,最好的中文Llama大模型,完全开源可商用。 -
良好的社区

-
开放且不断增加的数据
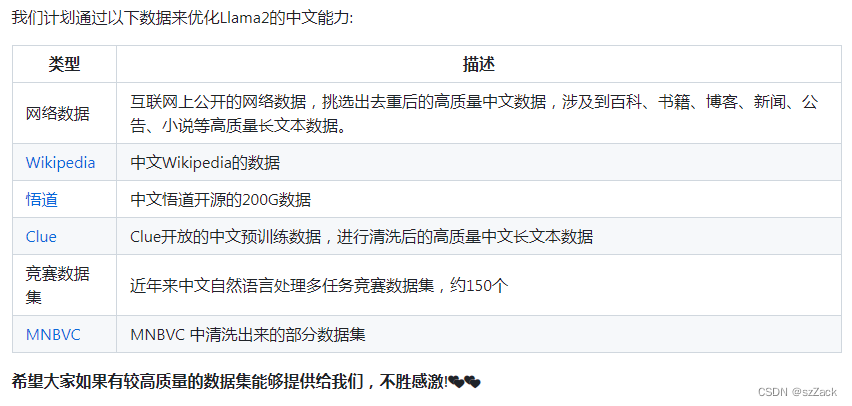
-
开源可下载可商用的模型
我们基于中文指令数据集对Llama2-Chat模型进行了微调,使得Llama2模型有着更强的中文对话能力。LoRA参数以及与基础模型合并的参数均已上传至Hugging Face https://huggingface.co/FlagAlpha,目前包含7B和13B的模型。

- 详细的模型微调过程

- 其他
包括:模型量化、推理假设、模型评测、集成LangChain框架等
NO2. hiyouga/LLaMA-Efficient-Tuning
-
star:3.2K
-
介绍:
Easy-to-use LLM fine-tuning framework (LLaMA-2, BLOOM, Falcon, Baichuan, Qwen, ChatGLM2) -
开放且不断增加的数据
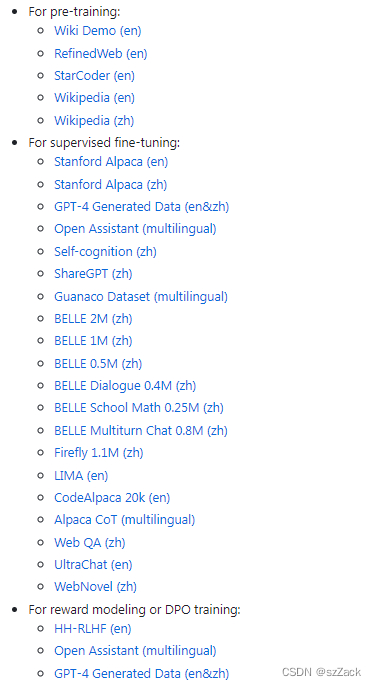
-
开源可下载可商用的模型,且支持很多开源模型

-
支持多种模型训练、微调方法
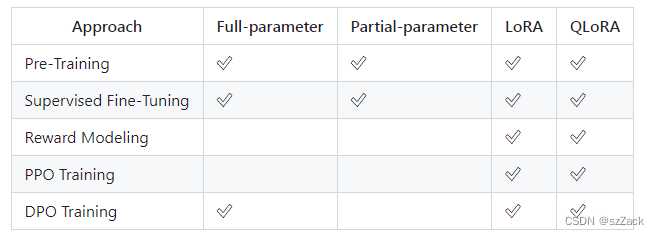
支持单卡训练、分布式多级多卡并行训练,脚本很详细,建议看作者的GitHub。
NO3. yangjianxin1/Firefly
-
star:2.1K
-
GitHub地址:
https://github.com/yangjianxin1/Firefly -
介绍:
Firefly(流萤): 中文对话式大语言模型(全量微调+QLoRA),支持微调Llma2、Llama、Qwen、Baichuan、ChatGLM2、InternLM、Ziya、Bloom等大模型 -
本项目主要内容如下:
📗 支持全量参数指令微调、QLoRA低成本高效指令微调、LoRA指令微调(后续将会提供支持)。
📗 支持绝大部分主流的开源大模型,如百川baichuan、Ziya、Bloom、LLaMA等。
📗 支持lora与base model进行权重合并,推理更便捷。
📗️ 模型裁剪:通过LLMPruner:大语言模型裁剪工具 ,开源裁剪后的Bloom模型权重 。在保留预训练中文知识的前提下,有效减少模型参数量,降低训练成本,提高训练效率。
📗 整理并开源指令微调数据集:firefly-train-1.1M 、moss-003-sft-data、ultrachat、 WizardLM_evol_instruct_V2_143k、school_math_0.25M。
📗 开源Firefly系列指令微调模型权重 。 -
开放且不断增加的数据

-
开源可下载可商用的模型
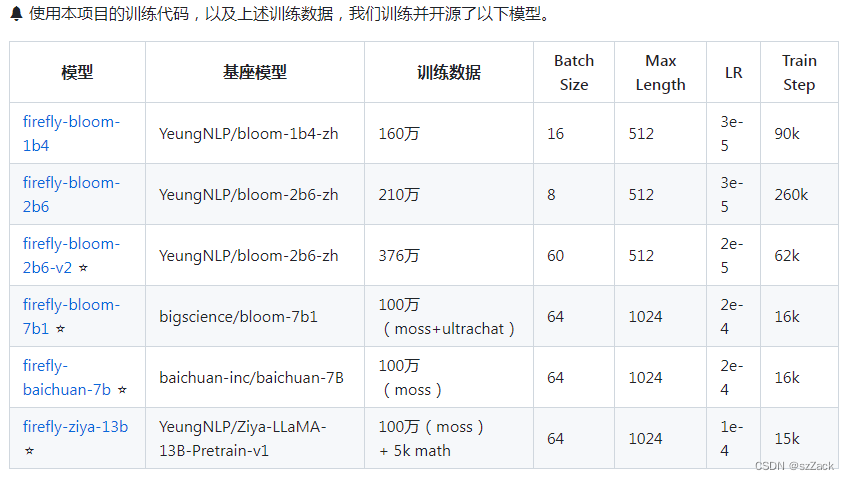
-
详细的模型微调过程
目前支持全量参数指令微调、QLoRA指令微调,后续会添加对LoRA的支持(经过实测,QLoRA的效率与效果优于LoRA)。

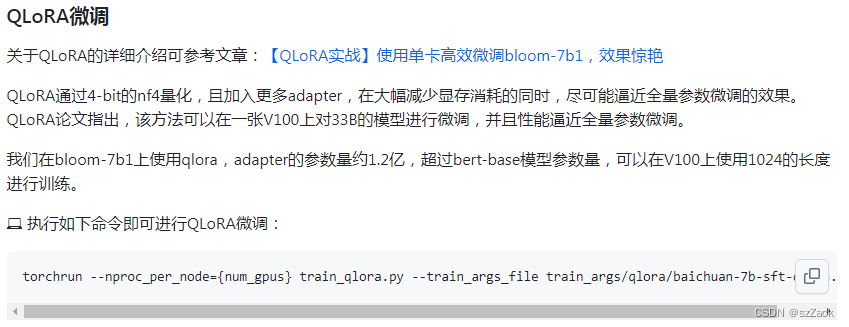
- 其他
包括:权重合并、模型推理等
NO4. LinkSoul-AI/Chinese-Llama-2-7b
-
star:1.7K
-
介绍:
开源社区第一个能下载、能运行的中文 LLaMA2 模型!
全部开源,完全可商用的中文版 Llama2 模型及中英文 SFT 数据集,输入格式严格遵循 llama-2-chat 格式,兼容适配所有针对原版 llama-2-chat 模型的优化。 -
开放且不断增加的数据
我们使用了中英文 SFT 数据集,数据量 1000 万。
数据集:https://huggingface.co/datasets/LinkSoul/instruction_merge_set -
开源可下载可商用的模型

-
详细的模型微调过程
DATASET="LinkSoul/instruction_merge_set"
DATA_CACHE_PATH="hf_datasets_cache"
MODEL_PATH="/PATH/TO/TRANSFORMERS/VERSION/LLAMA2"
output_dir="./checkpoints_llama2"
torchrun --nnodes=1 --node_rank=0 --nproc_per_node=8 \
--master_port=25003 \
train.py \
--model_name_or_path ${MODEL_PATH} \
--data_path ${DATASET} \
--data_cache_path ${DATA_CACHE_PATH} \
--bf16 True \
--output_dir ${output_dir} \
--num_train_epochs 1 \
--per_device_train_batch_size 4 \
--per_device_eval_batch_size 4 \
--gradient_accumulation_steps 1 \
--evaluation_strategy 'no' \
--save_strategy 'steps' \
--save_steps 1200 \
--save_total_limit 5 \
--learning_rate 2e-5 \
--weight_decay 0. \
--warmup_ratio 0.03 \
--lr_scheduler_type cosine \
--logging_steps 1 \
--fsdp 'full_shard auto_wrap' \
--fsdp_transformer_layer_cls_to_wrap 'LlamaDecoderLayer' \
--tf32 True \
--model_max_length 4096 \
--gradient_checkpointing True
NO5. wenge-research/YaYi
-
star:1.5K
-
GitHub地址:
https://github.com/wenge-research/YaYi -
介绍:
雅意大模型在百万级人工构造的高质量领域数据上进行指令微调得到,训练数据覆盖媒体宣传、舆情分析、公共安全、金融风控、城市治理等五大领域,上百种自然语言指令任务。雅意大模型从预训练初始化权重到领域模型的迭代过程中,我们逐步增强了它的中文基础能力和领域分析能力,并增加了多轮对话和部分插件能力。同时,经过数百名用户内测过程中持续不断的人工反馈优化,我们进一步提升了模型性能和安全性。通过雅意大模型的开源为促进中文预训练大模型开源社区的发展,贡献自己的一份力量,通过开源,与每一位合作伙伴共建雅意大模型生态。
News: 🔥 雅意大模型已开源基于 LLaMA 2 的中文优化模型版本,探索适用于中文多领域任务的最新实践。
-
开放且不断增加的数据
雅意大模型基于中科闻歌百万级高质量领域指令微调数据集训练而来,我们本次开源 5w 条训练数据集,可在我们的 Huggingface 数据仓库 https://huggingface.co/wenge-research 下载。数据集主要涵盖了金融、安全、舆情、媒体等几大领域,我们为各领域任务大部分指令数据添加了离散 prompt 前缀,以区分各领域数据。此外,训练数据中还包含部分安全增强数据、插件能力数据、多轮对话数据等。 -
开源可下载可商用的模型

-
详细的模型微调过程
- 指令数据全参数微调
- 指令数据 LoRA 微调
- 多轮对话数据全参数微调
- 多轮对话数据 LoRA 微调
NO6. michael-wzhu/Chinese-LlaMA2
-
star:686
-
介绍:
就在不久前,Meta最新开源了Llama 2模型,完全可商用,看来Meta势必要与OpenAI (ClosedAI) 硬刚到底。虽然Llama 2对原版的LlaMA模型做了升级,但是其仍然对中文没有太好的支持,需要在中文上做定制化。所以我们决定在次开展Llama 2的中文汉化工作:🚀 Chinese-LlaMA2-chat-sft:对Llama-2直接进行有监督微调,
采用开源指令微调数据,如UltraChat, 各种版本的中文alpaca语料(如Chinese-alpaca, BELLE)等;
注意LlaMA词表本身是支持中文的,所以我们会训练不扩充词表版本和扩充词表版本
⏳ Chinese-LlaMA2: 对Llama 2进行大规模中文预训练;
第一步:先在42G中文语料上进行训练;后续将会加大训练规模
⏳ Chinese-LlaMA2-chat: 对Chinese-LlaMA2进行指令微调和多轮对话微调,以适应各种应用场景和多轮对话交互。
注意,遵循相应的许可,我们将发布完整的, 合并LoRA权重的完整,且同时发布LoRA权重,方便开源社区使用。同时,我们将会围绕Chinese-LlaMA2打造各种垂直领域模型:
⏳Chinese-LlaMA2-chatmed: Chinese-LlaMA2医学领域大模型,支持多轮在线问诊;
⏳Chinese-LlaMA2-tcm: Chinese-LlaMA2中医药大模型,专注于中医药细分领域,赋能中医药传承【】后续工作值得期待
-
团队介绍
本项目由华东师范大学计算机科学与技术学院智能知识管理与服务团队完成,团队指导老师为王晓玲教授。 -
指令微调
对LlaMA-2进行指令微调(不扩充词表/扩充词表),也就是现在常见的SFT,见SFT-README.md
-
扩充词表和扩展embedding层
我们现在采用的方案是:使用Chinese-LLaMA的词表,该词表是对llama原始词表的扩充,将词汇量从32000扩展到49953大小。同时LlaMA-2模型会进行embedding层的resize,即采用随机初始化的参数扩展embedding层和lm_head层。 -
继续预训练
由于扩展词表后,LlaMA-2的embedding层和lm_head层会有随机初始化的参数,所以我们需要采用大规模的预训练学习中文语料的知识。继续预训练运行以下命令(数据,模型的路径,卡数等需要自行配置):CUDA_VISIBLE_DEVICES="2,3" ./src/further_ft/run_train.sh



















 1158
1158

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











