






加州大学伯克利分校发表的创建大语言模型虚拟人格的方法
原创 无影寺 AI帝国 2024年07月17日 08:58 广东

AI帝国
分享大语言模型(LLM)相关最新的理论、动态、应用等等
303篇原创内容
公众号

一、结论写在前面
论文来自加州大学伯克利分校。
论文标题:Virtual Personas for Language Models via an Anthology of Backstories
论文链接:https://www.arxiv.org/abs/2407.06576
代码和数据:https://github.com/CannyLab/anthology
大型语言模型(LLMs)从由数百万不同作者撰写的庞大文本库中进行训练,反映了人类特质的巨大多样性。尽管这些模型具有在行为研究中用作人类主体近似值的潜力,但先前的努力在引导模型响应以匹配个别用户方面受到限制。
论文引入了“Anthology”,一种通过利用开放式生活叙事(open-ended life narratives,论文称之为“背景故事”,“backstories)来条件化LLMs以特定虚拟角色(virtual personas)的方法。
论文证明这种方法与现实世界的人口统计数据高度一致,并展示了在模拟人类般反应以应用于社会科学方面的巨大潜力。
二、论文的简单介绍
2.1 论文的背景
大型语言模型(LLMs)从大量人类撰写的文本中进行训练。这些文本由数百万不同的作者撰写,反映了人类特质的巨大多样性。因此,当一个语言模型完成一个提示时,生成的响应隐含地编码了来自产生训练文本的人类作者的混合声音,这些声音是从中推断出完成的。尽管由于在当前广泛采用的LLMs应用(如实证问答(QA)和算法推理)中这种性质的影响微不足道而被忽视,但当模型被询问开放式问题或旨在被条件化为特定角色时,解决这些模型固有地反映了来自人类作者混合的平均声音这一事实至关重要。
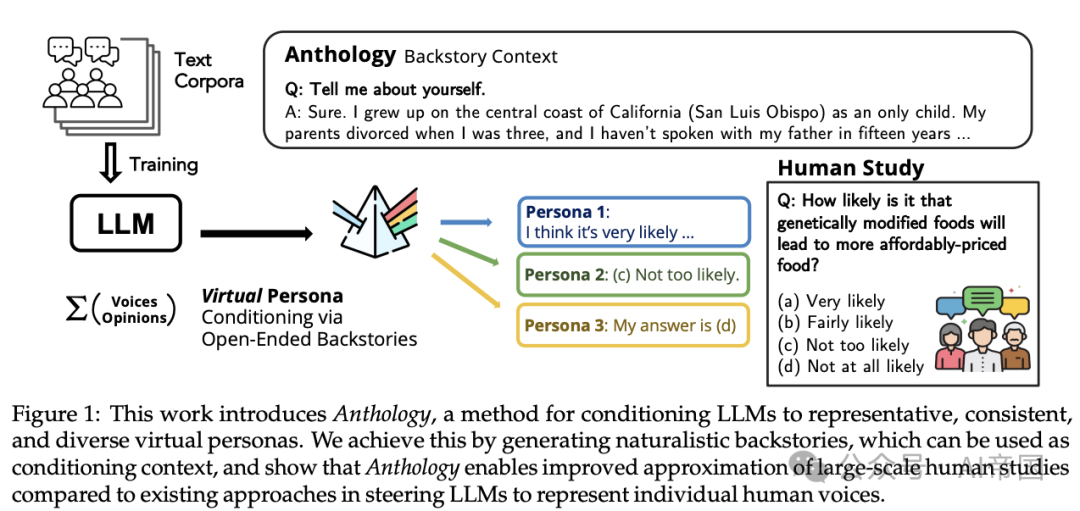
图1:本研究引入了Anthology方法,用于训练大型语言模型(LLMs)以代表性、一致性和多样性地呈现虚拟角色。论文通过生成自然主义的背景故事作为调节上下文来实现这一点,并展示Anthology方法在引导LLMs模拟个体人类声音方面相比现有方法能够更好地近似大规模人类研究
一个日益重要的典型例子是使用LLMs在行为研究背景下模拟人类。在努力招募足够大、具有代表性和公正的样本时,这一过程充满挑战。尽管LLMs本身存在明显风险,包括基于互联网数据训练的模型固有偏见,但使用语言模型进行近似试点研究可以帮助调查设计者满足最佳实践(的慈善和正义要求,而无需且在实际对人类受访者造成潜在伤害之前。
为了让语言模型能够有效地作为虚拟主体,我们必须能够引导它们的回应以反映特定的人类用户,即将模型调节为可靠的虚拟人格。为此,现有的工作通过提示大型语言模型使用明确列出目标人格的人口统计学和个人特征的上下文:例如,Santurkar等人(2023)、Liu等人(2024a)、Kim和Lee(2024)以及Hwang等人(2023)尝试通过一系列关于人口统计指标的问答对组成的对话、列出所有特征的自由文本传记,以及以第二人称视角描述该人格来引导大型语言模型的回应。
虽然这些方法取得了一定的成功,但它们在以下方面仍有局限性:(i)准确表现人类对应者的回应,(ii)一致性,以及(iii)成功地绑定到多样化的人格,特别是那些来自代表性不足的亚群体的人格。
那么,如何条件化LLMs以形成具有代表性、一致性和多样性的虚拟人格呢?论文探讨了使用描述个体生活故事的自然主义文本,即背景故事,作为模型提示的前缀以进行人格条件化。开放式的生活叙述既明确又隐含地体现了关于作者的多样细节,包括年龄、性别、教育水平、情感和信仰等。因此,冗长的背景故事能够精确限制用户特征,包括未明确征求的潜在特质如性格或心理健康,并强烈条件化LLMs以形成多样化的虚拟人格。
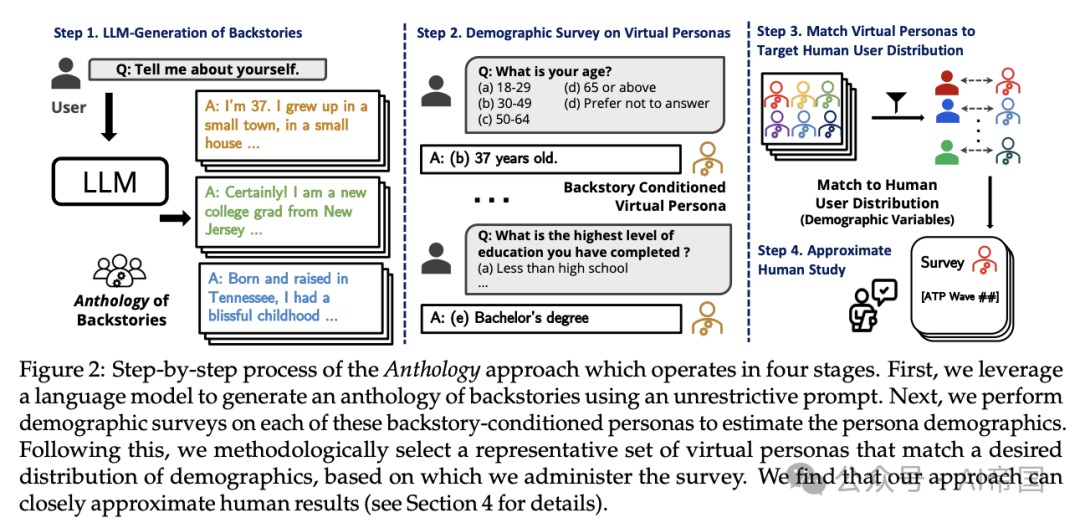
图2:Anthology方法的逐步流程,该方法分为四个阶段。首先,论文利用语言模型通过一个无限制的提示生成一系列背景故事。接下来,论文对每个基于背景故事的虚拟人物进行人口统计调查,以估计人物的人口统计特征。随后,论文根据目标人口统计分布,系统性地选择一组代表性的虚拟人物,并基于此进行调查。论文发现,论文的方法能够紧密地逼近人类结果(详见第4节)
论文提出了一种从LLMs自身生成背景故事的方法,作为高效生成覆盖广泛人类人口统计特征的大量集合的手段——论文称之为背景故事集。论文还引入了一种方法,从背景故事中采样以匹配目标人类人口分布。论文的整体方法通过模拟Pew研究中心的美国趋势小组(ATP)调查中进行的著名大规模人类研究得到了验证。论文证明,与基线方法相比,通过LLM生成的背景故事条件化的语言模型在匹配调查响应分布和一致性方面更接近真实人类受访者。特别是,论文展示了对于反映来自代表性不足群体用户的虚拟人物的优越条件化,Wasserstein距离和一致性分别提高了18%和27%。
2.2 通过背景故事文集对LLM进行虚拟角色条件化
在使用背景故事作为条件化虚拟角色以近似人类对象时,有两个实际考虑因素。论文将讨论如何解决这些影响:(i) 论文必须获取一个反映足够多样人类作者的背景故事集合,因为目标人类研究可能需要任意的人口分布。为此,论文引入了LLM生成的背景故事,以高效生成多样化的背景故事;以及 (ii) 论文无法事先确定给定背景故事可能的人口统计特征,因为人口统计变量可能不会在自然的生活叙述中明确提及。因此,论文引入了估计由每个背景故事条件化的虚拟角色人口统计特征的方法,并从文集中抽取与目标人群匹配的背景故事子集。
2.2.1 什么是背景故事?
论文使用“背景故事”一词来指代涵盖个人生活各个方面的第一人称叙述,从他们成长的地方和方式、形成性经历、教育、职业和个人关系,到他们的价值观和信仰。这些故事本质上是开放式的和个人化的,触及作者人口统计和个性特征的多样方面。
考虑图3所示的例子。论文观察到,生活故事不仅明确而且隐含地编码了关于作者的信息,从而提供了对作者身份的丰富洞察。例如,背景故事明确地暗示了作者的年龄(“在我60多岁时”)、家乡和/或地区(“这个国家的偏远地区”)以及童年时期的财务状况(“在非常贫困的环境中长大”)。但与其说是上述特质的简单列举,不如说故事本身体现了一个特定人类的自然、真实的嗓音,反映了他们的价值观和个性。
论文提出的方法是,通过将背景故事作为前缀放置在LLM之前,以此来强烈地条件化后续的文本完成,这与标准提示方法的精神相同。正如论文在图3中看到的,背景故事通过高水平的细节捕捉了关于作者的广泛属性,并且是提供真实性和一致性的自然主义叙事,这些叙事使得LLM所条件化的角色更加真实。

图3: LLM生成的背景故事示例。生成的生平故事可以揭示作者的明确细节,如年龄、家乡和财务背景,同时也通过叙述的风格和内容隐含地反映作者的价值观、个性和独特声音
2.2.2 LLM生成的背景故事
可以从现有的自传或口述历史集合中收集一系列人类编写的背景故事。然而,这一挑战在规模和多样性方面都存在。论文发现,目前公开可用的自传生活叙事和口述历史资源在样本数量上有限,不足以充分近似更大规模的人类研究。
相反,论文提出利用语言模型生成看似真实背景故事作为成本效益更高的替代方案。如图2的步骤1所示,论文向大型语言模型(LLMs)提供一个开放式提示,例如,“请介绍一下你自己。”论文特别关注提示的简洁性,以确保模型响应不受限制且无偏见。然而,该提示隐含地要求一个全面的叙述。响应此提示需要语言模型生成一系列相互关联的事件和经历,形成一条连贯的生活轨迹,这自然意味着一致性和发展性,如图3所示。在采样温度 ( T= 1.0 ) 下,论文生成的背景故事涵盖了多样人类用户的广泛生活经历。
2.2.3 虚拟人物人口统计调查(Demographic Survey on Virtual Personas)
由于我们打算在行为研究中使用虚拟人格来近似人类受访者,因此精心策划一套适当的背景故事来调节代表目标人群的人格至关重要。每项研究都会有一组特定的人口统计变量,以及对其受访者人口统计的估计或准确统计数据。尽管自然主义的背景故事包含了关于个人作者的丰富细节,但并不能保证明确提及所有感兴趣的人口统计变量。因此,我们模拟了收集人类受访者人口统计特征的过程——对虚拟人格进行人口统计调查,如图2的步骤2所示。
虽然我们使用与人类研究中相同的人口统计问题集,但我们考虑到,与每个人都有明确定义的确定性特征集的人类受访者不同,大型语言模型的虚拟人格应该用人口统计变量的概率分布来描述。因此,我们对每个人口统计问题采样多个回答,以估计给定虚拟人格的特征分布。
2.2.4 匹配目标人类群体
剩下的问题是:论文如何为每个调查选择合适的背景故事集来近似?通过人口统计调查的结果,论文将虚拟人格与真实人类群体进行匹配,如图2中的步骤3所示。为此,论文构建了一个由元组定义的完全加权二分图,G= (H, V,E)。
顶点集H ={h_1, .. h_n}表示大小为n的人类用户组,而另一个顶点集V = {v_1,v_2,...,v_n}表示大小为m的虚拟用户组。每个顶点h_i包含第i个人类用户的特征。具体来说,h (t_i1,t_i2,.... t_ik),其中k是人口统计变量的数量,t_il是第i个用户的第l个人口统计变量的特征。类似地,V中的每个顶点v包含每个虚拟用户的人口统计变量的概率分布,定义为v_j = (P(d_j1) ,P(d_j2) ,...P(d_jk) ),其中d_jl是第j个用户的第l个人口随机变量及其概率分布。
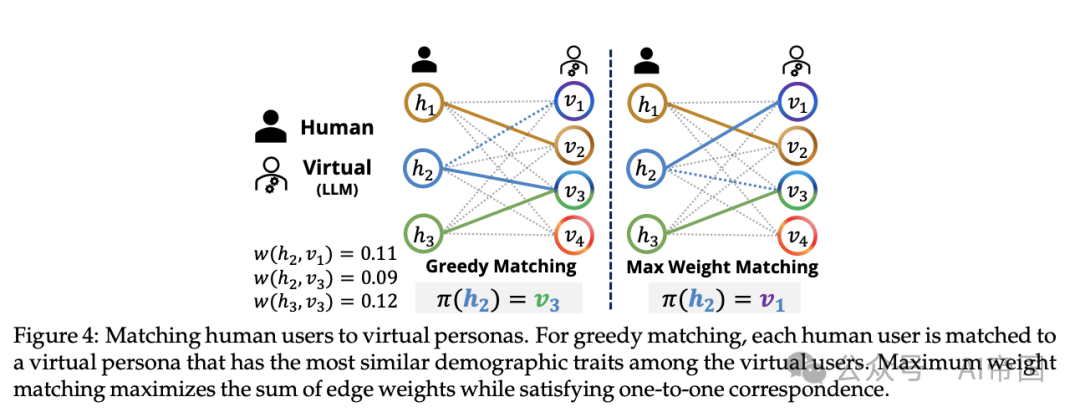
图 4:将人类用户匹配到虚拟角色。对于贪心匹配,每个用户被匹配到一个具有最相似人口统计特征的虚拟角色。最大权重匹配在满足一对一对应关系的同时,最大化边权重的总和
边集包含 e_ij,表示 h_i 和 v_j 之间的边。边的权重 w(e_ij) 或等价地 w(h_i, v_j) ,定义为第 ( j ) 个虚拟用户的特征对应于第 ( i ) 个人类用户的人口统计特征的似然度的乘积。论文正式定义这样的边权重:
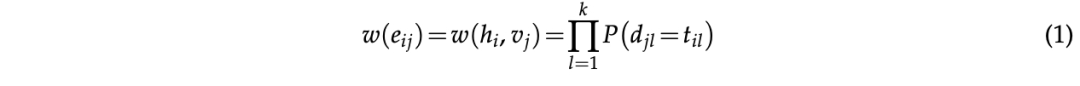
论文执行二分匹配,以选择其人口统计概率分布与真实人类用户群体最相似的虚拟角色。目标是找到匹配函数 以最大化以下目标:
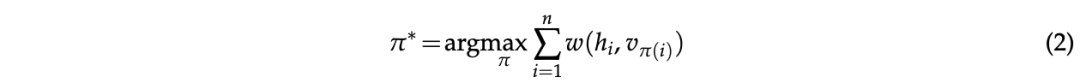
论文探索两种匹配方法:(1) 最大权重匹配,和 (2) 贪心匹配。首先,最大权重匹配是找到使式 (2) 目标最优的 π^*的方法,同时确保 π建立用户之间的一对一对应关系。论文采用匈牙利匹配算法 Kuhn (1955) 来确定π。另一方面,贪心匹配旨在最大化相同目标,而不需要一对一对应关系。它确定最优匹配函数,使得
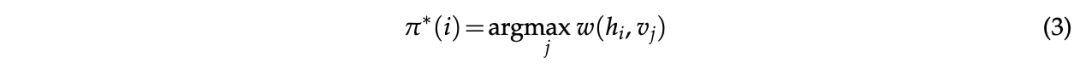
其中每个人类用户被分配到具有最高权重的虚拟角色,允许多人被分配到同一个虚拟角色。
完成匹配过程后,我们将目标人群的人口统计特征分配给匹配的背景故事。在后续的调查中,我们将这些人口统计信息附加到背景故事中,并使用匹配的背景故事子集,使得背景故事的数量与目标人类人群的数量相同。
2.3 使用 LLM Personas 近似人类研究
论文讨论论文旨在使用 LLM 虚拟对象(图 2 的步骤 4)近似的大规模人类研究,基于不同的 persona conditioning 方法。论文详细描述了总体实验设置和定义评估标准。

图 5:来自 ATP Wave 92(政治类型学)的一个示例问题(SOCIETY RELIG),询问关于给定陈述对美国社会是好是坏的意见
人类研究数据 皮尤研究中心的美国趋势小组(ATP)是一个全国性的随机抽样美国成年人代表性小组,旨在追踪公众意见和社会趋势随时间的变化。每个小组专注于特定主题,如政治、社会问题和经济状况。在本研究中,论文考虑了ATP的第34波、第92波和第99波,这是一组相对较新的调查,涵盖了广泛的议题:生物医学与食品问题、政治类型学以及人工智能与人类增强。在每一波中,论文选择了原始问卷中的6到8个问题,这些问题使用李克特量表捕捉了关于该波主题的人类观点的多样性。
实验设置 对于所考虑的每个ATP调查,论文将选定的问题格式化为语言模型提示,以进行调查近似。图5展示了此类格式化问题的示例。论文考虑的所有问题都是多选题答案格式,并且论文仔细保留了每个问题和选项的原始调查措辞。论文按顺序提问——语言模型在回答每个新问题时会给出所有先前的问题及其答案。这一过程模拟了人类受访者在调查过程中经历的心理过程。
语言模型 论文考虑了一系列近期的大型语言模型(LLMs),包括Meta的Llama3系列(Llama-3-70B )以及Mistral AI的稀疏混合专家(MoE)模型(Mixtral-8x22B)。论文主要关注具有最多活跃参数的模型,这些参数大致与模型能力和训练数据语料库的大小相关。
注意,论文主要考虑未经微调的预训练大型语言模型(即基础模型)。论文发现通过RLHF 或DPO进行指令微调的模型不适合论文的研究,因为它们的观点高度偏斜,特别是对某些群体(例如政治自由派)。先前的工作同样报告了微调模型中显著的观点偏见。
虚拟人格条件化方法 作为人格条件化的基线方法,论文遵循Santurkar et al. (2023)并使用(i)Bio,它以基于规则的方式构建自由文本传记;以及(ii)QA,它列出关于每个人口统计变量的一系列问答对。
然后论文将其与Anthology的两个变体进行比较:
(i) 自然变体:指使用没有任何预设人设的生成背景故事,如2.2节所述。在这种情况下,论文利用2.4节中的贪婪或最大权重匹配方法来选择用于每次调查的子集。
(ii) 人口统计启发变体:另一种方法是根据特定人类用户的人口统计特征来近似生成背景故事,其中语言模型被提示生成能反映指定人口统计特征的人的生活叙述(详情见附录B)。然后,论文将人口统计特征的描述附加到生成的背景故事中,并将其作为上下文提供给LLM。
评估标准 这项工作的目标是解决研究问题:论文如何将大型语言模型条件化为具有代表性、一致性和多样性的人格?
代表性:论文认为一个“具有代表性”的虚拟角色应能成功近似其对应人类主体的一阶意见倾向,即对个别调查问题的回答应表现出相似性。由于问题为多项选择,论文通过Wasserstein距离(亦称为地球移动者距离)来比较每个问题的平均答案选择分布。至于整个给定调查样本集中问题的代表性,论文采用Wasserstein距离的平均值。
一致性:论文定义虚拟角色的一致性在于其成功近似人类受访者的二阶反应特质,即每项调查中对一系列问题的回答之间的相关性。形式上,论文定义虚拟主体和人类主体的调查反应相关性矩阵的一致性度量为:
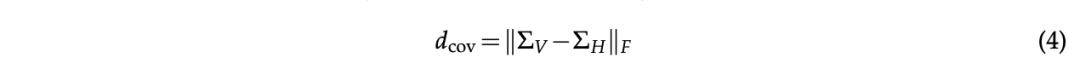
其中|·|F表示Frobenius范数。此外,论文独立于真实人类反应,考虑使用Cronbach's alpha作为内部一致性的度量。
多样性:论文通过衡量虚拟角色在近似属于特定人口统计子群体的人类受访者时的代表性和一致性,来定义对多样化虚拟主体的调节成功。
2.4 实验结果
本节描述实验结果,验证论文提出的方法在行为研究中近似人类主体的有效性。
2.4.1 人类研究近似
论文在近似三个皮尤研究中心ATP调查(的背景下,评估不同方法对虚拟角色调节的有效性。在分析虚拟主体之前,论文首先估算每个评估指标的下限:平均Wasserstein距离(WD)、Frobenius范数(Fro.)和Cronbach's alpha(k),如表1最后一行所示。这涉及随机将人类群体分成两个等大小的组,并在子组之间计算这些指标,取100次迭代的平均值以代表下限估计。
表1:关于近似Pew研究中心ATP调查第34波、第92波和第99波的人类响应结果,这些调查分别在2016年、2021年和2021年进行。论文测量了三个指标:(i)WD:人类受试者和虚拟受试者在所有调查问题上的平均Wasserstein距离;(ii)Fro.:人类和虚拟受试者相关矩阵之间的Frobenius范数;(iii)α:Cronbach's alpha,评估响应的内部一致性。Anthology(DP)指基于人口统计学背景故事的条件化,而Anthology(NA)代表基于自然生成背景故事的条件化(不预设人口统计学)。加粗和下划线的结果分别表示最接近和第二接近人类结果的值。这些比较是与表格最后一行的人类结果进行的
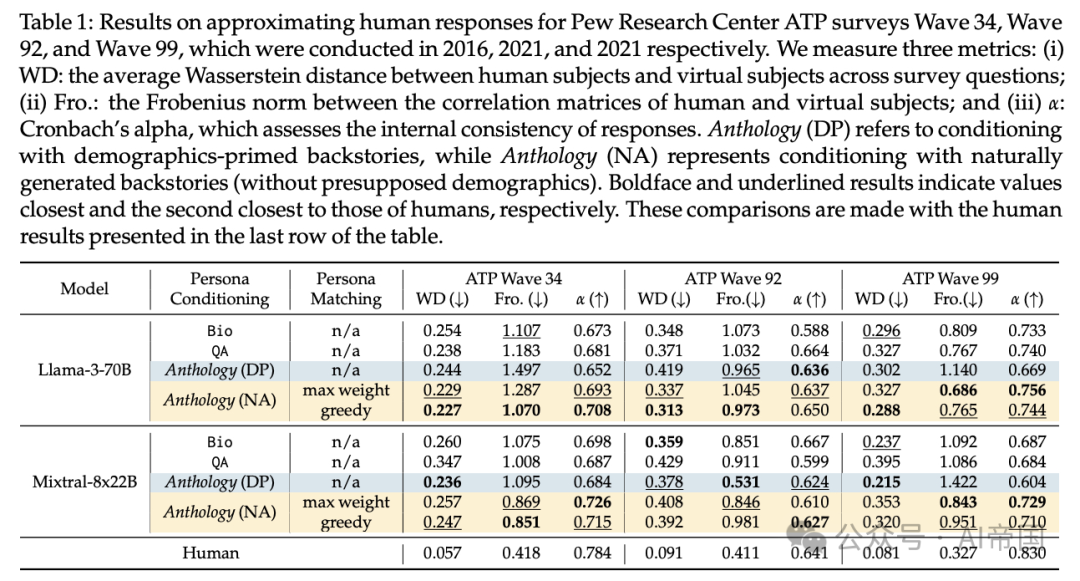
结果总结在表1中。论文一致观察到,对于Llama-3-70B和Mixtral-8x22B,Anthology在所有指标上都优于其他条件化方法。比较两种匹配方法,贪心匹配方法在所有波次的平均Wasserstein距离上往往表现出更好的性能。论文将不同匹配方法的差异归因于最大权重匹配的一对一对应条件和论文可用的虚拟用户数量的限制。
具体来说,在最大权重匹配中分配给匹配虚拟受试者的权重不可避免地低于贪心匹配中的权重,因为后者放宽了一对一对应的约束。这种差异可能导致匹配的人类和虚拟用户之间的人口统计学相似度低于贪心匹配的对应者。这些结果表明,论文的方法中生成的背景故事的丰富性可以引发比基线更细致的响应。
2.4.2 近似多样性人类主体
论文在多样性标准下,进一步评估Anthology与其他基线条件方法的性能。为此,论文根据ATP调查波次34的数据,将用户按种族(白人和其他种族群体)和年龄(18-49岁、50-64岁和65岁及以上)进行子群划分。涉及其他人口统计变量的比较结果详见附录A.2。论文选择Llama-3-70B模型和使用自然背景故事及贪婪匹配的Anthology作为论文的方法。
如表2总结所示,Anthology优于其他方法。特别地,Anthology在所有子群中实现了最低的平均Wasserstein距离和最高的Cronbach's alpha。具体而言,Anthology与次优方法在18-49岁年龄组的Wasserstein距离差距为0.029,显示出14.5%的差异。这些结果验证了Anthology在近似多样性人口统计群体方面比先前方法更为有效。
除了18-49岁年龄组之外,所有方法在近似整个人类受访者(表2之前的比较结果)时的平均Wasserstein距离均表现更差如表1所示。例如,在ATPV Wave 34调查中,Anthology的平均Wasserstein距离为0.227,而在50-64年龄组中增加到0.242,65+年龄组中为0.303。相反,在18-49年龄组中,Anthology显示出较低的平均Wasserstein距离0.2,相对于0.227。这一发现与先前研究一致,认为语言模型响应更倾向于年轻群体。
表2:子群比较结果目标人群被划分为不同的人口统计子群,并在每个子群内测量代表性和一致性。Anthology始终导致更低的Wasserstein距离、更低的Frobenius范数和更高的Cronbach's alpha。加粗和下划线结果分别表示最接近和第二接近人类值的数值。这些比较是基于表格最后一行中的人类结果进行的
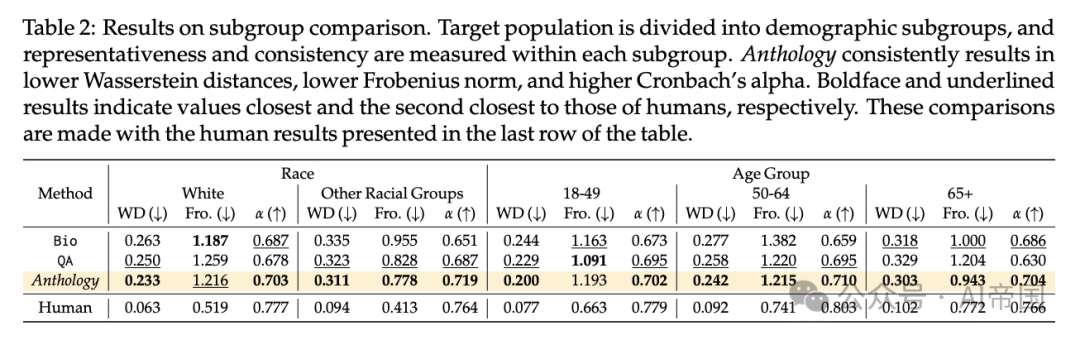
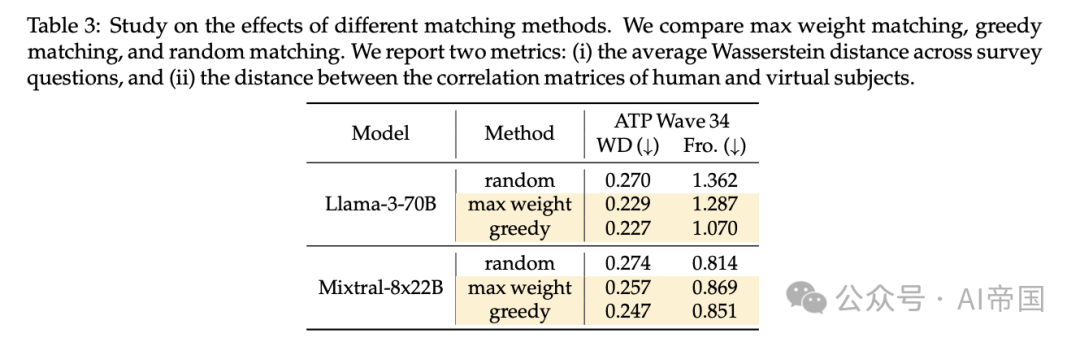
表3:不同匹配方法效果研究。论文比较了最大权重匹配、贪婪匹配和随机匹配。报告了两个指标:(i)调查问题间的平均Wasserstein距离,以及(ii)人类与虚拟受试者相关矩阵间的距离
2.4.3 匹配目标人群背景故事的采样策略
接下来,论文研究匹配策略(贪婪匹配和最大权重匹配)的效果。在表3中,论文将这些方法与随机匹配进行比较,随机匹配是将目标人群的特征随机分配给采样的背景故事。此比较在ATP Wave 34上使用Llama-3-70B和Mixtral2-8x22B模型进行。
论文观察到,论文的匹配方法在所有模型的平均Wasserstein距离上始终优于随机匹配。例如,在Llama-3-70B模型中,随机匹配与贪婪匹配之间的平均Wasserstein距离差异为18%。在Frobenius范数上的差异更为显著,达到27%。这一结果表明,背景故事与目标人群分布之间的不一致匹配会显著影响指标的有效性。因此,仔细的匹配对于确保论文研究结果的可靠性和有效性至关重要。

















 446
446

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









