






1 简介
本文根据2014年《Distributed Representations of Sentences and Documents》翻译总结的。
Bag-of-words方法有两个主要的缺点:一是丢失了词汇间的顺序,二是忽视了词汇的语义信息。如果把“powerful”、 “strong” 、“Paris”这3个单词认为是相同距离的。实际上,“powerful”相比“Paris”应该更靠近“strong”。
本文,我们提出了Paragraph Vector,采用无监督算法从可变长度的文本中学习固定长度的特征表示,可变长度的文本包括句子、段落、文档等等。Paragraph Vector克服了word vector的两个缺点,一是使“powerful”相比“Paris”更靠近“strong”,二是考虑了单词顺序,至少在小的上下文中。
2 算法介绍
2.1 Word vector
如下图,根据the、cat、sat预测第4个单词on。每个单词构成矩阵W的一列,然后W通过concatenate或者average进行预测“on”。
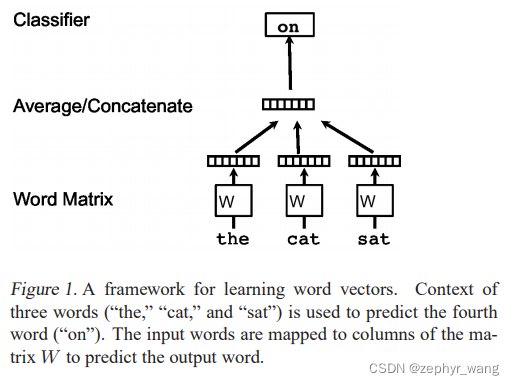
公式如下:
根据周边单词预测下一个单词,目标函数如下:
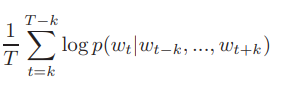
预测任务一般采用多分类,如softmax,如下:
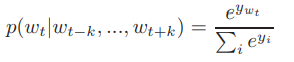
每一个输出的单词y,公式如下,其中U,b是softmax参数,h是由W通过concatenate或者average构建的:
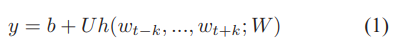
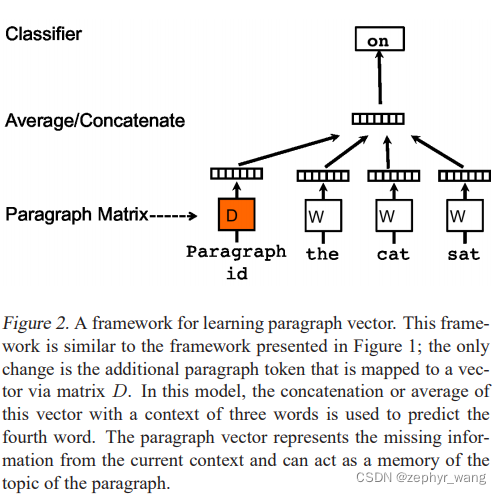
2.2 Paragraph Vector
如下图,在word vector基础上引入矩阵D,代表paragraph。主要修改就是在word vector公式1中的h变成由W和D一起构建的。
Paragraph token可以认为一个记录,其记录了当前上下文丢失的信息,如段落主题。因为我们称该模型为 Distributed Memory Model of Paragraph Vectors (PV-DM).
该Paragraph vector D是跨段落的,不同段落的不一样。而 word vector W是在各段落间共享的、相同的。
Paragraph vector和word vector 是使用stochastic gradient descent进行训练的,采用了反向传播(backpropagation)。
在预测时,固定word vector,采用梯度下降实时生成Paragraph vector。
我们然后可以使用Paragraph vector D做一些分类预测任务。
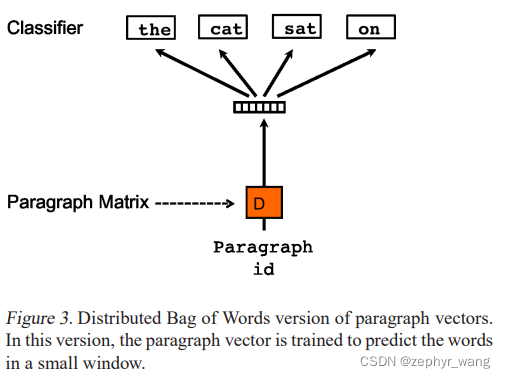
2.3 Paragraph Vector without word ordering: Distributed bag of words
如下图,忽略输入单词的顺序。称为Distributed Bag of Words version of Paragraph Vector (PV-DBOW)。
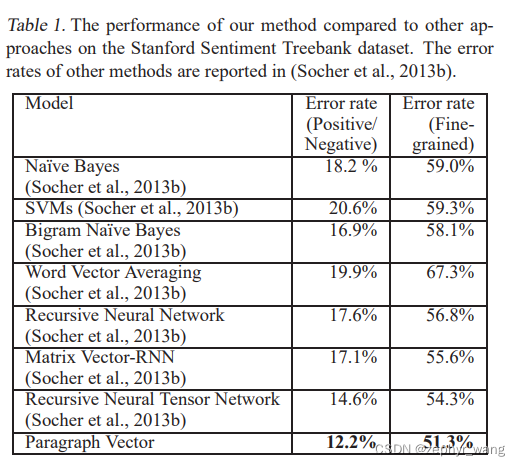
3 实验结果
4 使用
from nltk.tokenize import word_tokenize
from gensim.models.doc2vec import Doc2Vec, TaggedDocument
tail_msg_list = msgs_df[‘msgs’].tolist()
tokenized_sent = [word_tokenize(s.lower()) for s in tail_msg_list]
print(‘开始训练embbeding模型(Doc2Vec)…’)
tagged_data = [TaggedDocument(d, [i]) for i, d in enumerate(tokenized_sent)]
model_d2v = Doc2Vec(tagged_data,dm = 1, alpha=0.1, vector_size= VECTOR_SIZE, min_alpha=0.025)
#训练
model_d2v.train(tagged_data, total_examples=model_d2v.corpus_count, epochs=20)
#预测
v = model_d2v.infer_vector(word_tokenize(row[‘msgs’].lower()), epochs=10)














 784
784











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









