








 本文介绍了latentdiffusionmodels(LDMs),这是一种两阶段的图像生成方法,能减少计算复杂度并生成高保真度的图像。LDMs首先通过感知压缩将图像转化为隐变量,然后用扩散模型进行处理。通过实验,LDM-4和LDM-8展示出较好的图像合成质量,且模型参数相对较少,适用于高分辨率和条件生成任务。
本文介绍了latentdiffusionmodels(LDMs),这是一种两阶段的图像生成方法,能减少计算复杂度并生成高保真度的图像。LDMs首先通过感知压缩将图像转化为隐变量,然后用扩散模型进行处理。通过实验,LDM-4和LDM-8展示出较好的图像合成质量,且模型参数相对较少,适用于高分辨率和条件生成任务。
1 简介
本文根据2022年4月的《High-Resolution Image Synthesis with Latent Diffusion Models 》翻译总结的。论文地址https://arxiv.org/pdf/2112.10752.pdf。源码地址:GitHub - CompVis/latent-diffusion: High-Resolution Image Synthesis with Latent Diffusion Models。
以前的扩散模型(diffusion models (DMs) )基于像素级别的,其需要上百个GPU day 进行训练。我们的方法latent diffusion models (LDMs) 在减少计算复杂度和保留细节、提升保真度中接近了最佳。
我们的方法latent diffusion models (LDMs)是两阶段模型(two-stage)。先对图片进行压缩,将图片压缩为隐变量表示(latent),减少计算复杂度,然后输入扩散模型。
如下图所示,我们进行的感知(perceptual)图片压缩不会丢失太多语义信息,但减少了计算量。
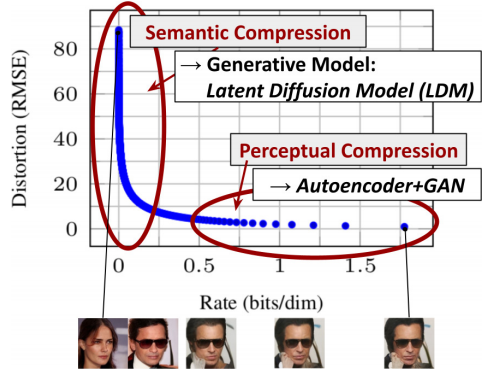
2 相关工作
图片生成模型
- GAN模型的结果是被限制在比较的数据集,因为它的对抗学习过程不是很容易扩展模型复杂度和多模态分布。GAN虽然可以生成高分辨率的图片,但很难优化而较难捕捉完整的数据分布。
- Variational autoencoders (VAE) 和 flow-based的模型可以高效的合成高分辨率图片,但其效果不如GAN模型。
- autoregressive models (ARM)在密集(density)估计上有很强的表现,但计算要求高的体系结构和顺序采样过程,故只能生成低分辨率图像。因为图片的像素级别的表示包含着几乎不可感知、高频的细节, maximum-likelihood 训练花费大量的精力来对这些细节建模,导致了很长的训练时间。为了扩展到高分辨率,一些两阶段(two-stage)方法使用ARM来构建压缩的图片隐变量表示,而不是原始像素级别的表示。
- 扩散模型是属于基于可能性的( likelihood-based )模型。基于可能性的方法强调好的密集(density)估计,这使得其表现良好。
两阶段(two-stage)图片生成
VQ-VAEs在一个离散化的空间使用自回归模型(ARM)学习图片的先验。
我们的方法latent diffusion models (LDMs)也是两阶段模型。
3 方法
我们模型latent diffusion models (LDMs)是两阶段的。第一部分就是下面左半部分(红色),对图片进行压缩,将图片压缩为隐变量表示(latent),这样可以减少计算复杂度;第二部分还是扩散模型(diffusion与denoising),中间绿色部分。此外引入了cross-attention机制,下图右半部分,方便文本或者图片草稿图等对扩散模型进行施加影响,从而生成我们想要的图片,比如根据文本生成我们想要的图片。
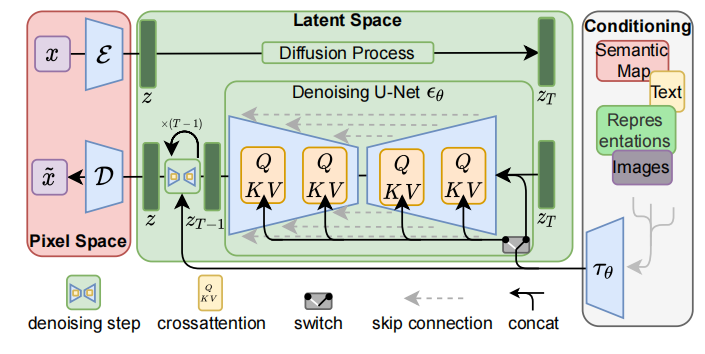
3.1 感知(perceptual)图片压缩
主要讲上图模型的左半部分(红色)。

为了避免任意的高可变的隐空间,我们实验了两种正则。第一种是KL-reg,施加了一个轻微的KL惩罚到学习到的隐变量,类似于VAE。另一种是VQ-reg,在解码器里使用了向量量化层。
这个编码器/解码器,我们可以只训练一次,适用于不同的DM模型训练。
3.2 Latent Diffusion Models
主要讲上图模型的中间部分(绿色)。
- 一般扩散模型的目标函数如下,可以参考DDPM:DDPM--Denoising Diffusion Probabilistic Models_AI强仔的博客-CSDN博客:
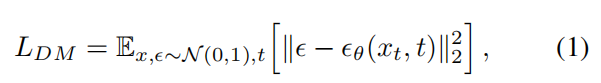
- 采用隐变量表示的扩散模型目标函数,如下:
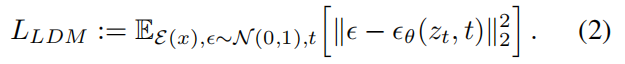
3.3 调节机制/cross-attention
我们通过在DM模型的UNET网络中引入cross-attention,实现灵活的图片生成控制。对不同输入模态,可以有效学习基于注意力的模型。

最终目标函数变成如下形式:

4 实验
4.1感知压缩权衡
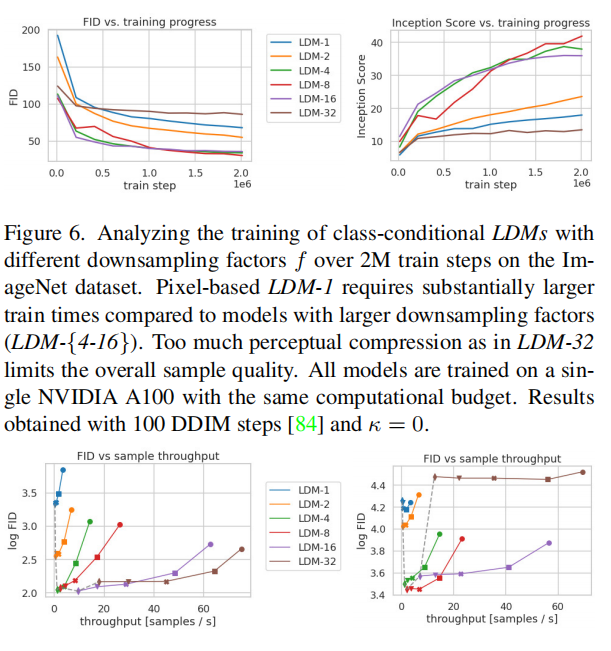
编码器下采样因子,我们取f ∈ {1, 2, 4, 8, 16, 32} ,即LDM-f表示不同的模型。其中LDM-1表示没有压缩,等同于原来基于像素的DM。
从下图,可以看出来,LDM-4和LDM-8合成高质量图片效果较好。
4.2 图片生成
如下图,LDM模型效果很好。
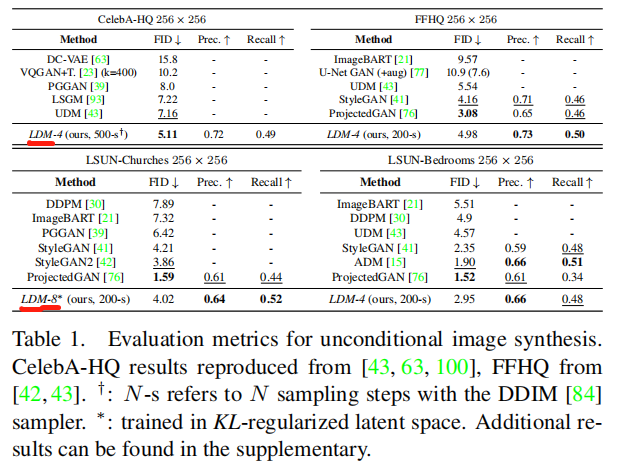
LDM的参数也较少,1.45B(14.5亿参数)。
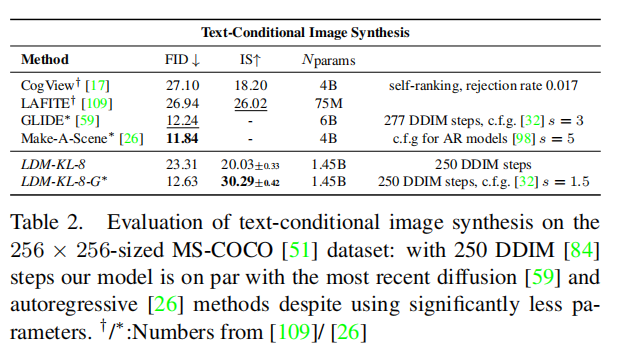
4.3条件生成
如下图,我们可以根据左上角的空间布局草稿图,生成高分辨率的大图。

下图根据文本生成图片,可以看到效果还不错。

4.4 高分辨率生成
我们可以根据低分辨率图片生成高分辨率图片,如下面中间部分。

4.5图像修复
可以将图片中的一部分恢复。下图是展示了抠图的效果。


















 4524
4524

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









