






1 原理介绍
是多模态分类任务——也就是融合视觉和文本特征,并进行分类。这篇文章主要的亮点在于使用了类似于LSTM中的gate机制,提出了一种基于门控神经网络的多模态学习新模型。 门控多模态单元 (GMU) 模型旨在用作神经网络架构中的内部单元,其目的是根据来自不同模态的数据的组合找到中间表示。 GMU 学习使用乘法门来决定模态如何影响单元的激活。
我们提出的模块基于门的想法,用于选择输入的哪些部分更有可能有助于正确生成所需的输出。 我们使用同时为各种特征分配重要性的乘法门,创建不需要手动调整的丰富的多模态表示,而是直接从训练数据中学习。
这项工作的主要假设是,与手动编码的多模态融合架构相比,使用门控单元的模型将能够学习一种依赖于输入的门控激活模式,该模式决定了每种模态如何对隐藏单元的输出做出贡献 。

每个
x
i
x_i
xi 对应一个与模态
i
i
i 相关的特征向量。 每个特征向量都为神经元提供一个
t
a
n
h
tanh
tanh 激活函数,该函数旨在根据特定的模态对内部表示特征进行编码。 对于每个输入模态
x
i
x_i
xi,都有一个门神经元(在图中由 σ 节点表示),它控制从
x
i
x_i
xi 计算的特征对单元整体输出的贡献。 当一个新样本被馈送到网络时,与模态
i
i
i 相关的门神经元接收来自所有模态的特征向量作为输入,并使用它们来决定模态
i
i
i 是否有助于特定输入的内部编码样本。
图 2.b 显示了用于两种输入模态
x
v
x_v
xv(视觉模态)和
x
t
x_t
xt(文本模态)的
G
M
U
GMU
GMU 的简化版本,将在本文的其余部分中使用。 应该注意的是,这两个模型并不完全等效,因为在双峰情况下,门是绑定的。 这种权重绑定限制了模型,因此单元在两种模式之间进行权衡,同时它们使用的参数少于多模式情况。 控制这个 GMU 的方程如下
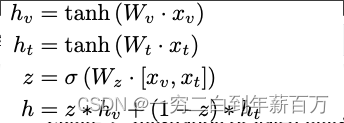
2 代码实现
class GatedMultimodalLayer(nn.Module):
"""
Gated Multimodal Layer based on 'Gated multimodal networks,
Arevalo1 et al.' (https://arxiv.org/abs/1702.01992)
"""
def __init__(self, size_in1, size_in2, size_out=16):
super(GatedMultimodalLayer, self).__init__()
self.size_in1, self.size_in2, self.size_out = size_in1, size_in2, size_out
self.hidden1 = nn.Linear(size_in1, size_out, bias=False)
self.hidden2 = nn.Linear(size_in2, size_out, bias=False)
self.hidden_sigmoid = nn.Linear(size_out*2, 1, bias=False)
# Activation functions
self.tanh_f = nn.Tanh()
self.sigmoid_f = nn.Sigmoid()
def forward(self, x1, x2):
h1 = self.tanh_f(self.hidden1(x1))
h2 = self.tanh_f(self.hidden1(x2))
x = th.cat((h1, h2), dim=1)
z = self.sigmoid_f(self.hidden_sigmoid(x))
return z.view(z.size()[0],1)*h1 + (1-z).view(z.size()[0],1)*h2
3 参考文献
[1]【多模态】《GATED MULTIMODAL UNITS FOR INFORMATION FUSION》论文阅读笔记
[2]https://github.com/IsaacRodgz/GMU-Baseline/tree/master/runs_pl

















 20万+
20万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









