






一、举个例子
一般常见指标是F1-score、precision、recall、roc、auc、accuracy,但他们存在的最大问题是,没有考虑TN。
例如下面这个分类器,预测出21只是狗(其中18个TP,3个是FP),3只是猫(其中2个是FN、1个是TN):
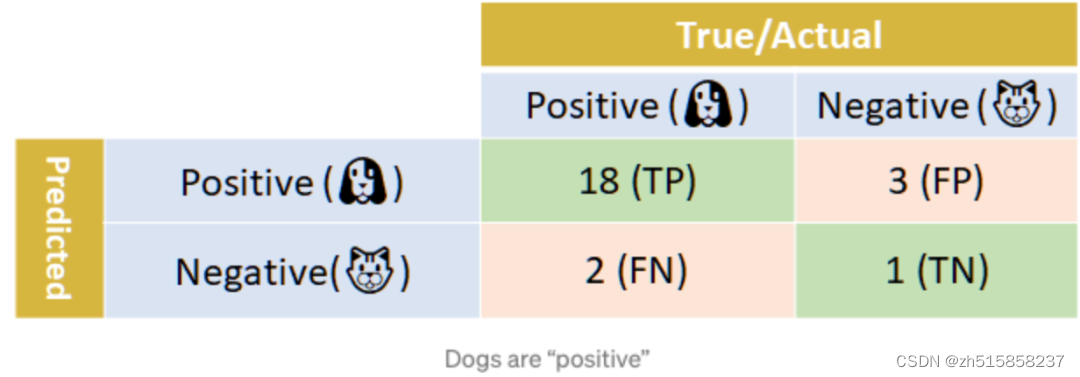
计算得到对应的精确率和召回率看起来貌似还不错的样子:
Precision = TP/(TP+FP) = 18/(18+3) = 0.86
Recall = TP/(TP+FN) = 18/(18+2) = 0.90
F1 = 2 * (Precision*Recall/Precision+Recall) = 0.88
但实际上,如果使用马修斯相关系数来计算,其性能就差强人意了:


需要注意的是,在上面的计算公式中,分母中任意一对括号相加之和如果为0,那么整个MCC的值就为0。
在python中,scikit-learn模块包含MCC计算的函数
from sklearn.metrics import matthews_corrcoef
y_true = [+1, +1, +1, -1]
y_pred = [+1, -1, +1, +1]
matthews_corrcoef(y_true, y_pred)
 Where:
Where:
s = number of samples
c = number of samples correctly predicted
p = number of times class k was predicted
t = number of times class k really/truly occurred
K = number of classes
二、参考文档
- https://cloud.tencent.com/developer/article/1975817
- https://qinqianshan.com/machine_learning/sklearn/clustering-performance-evaluation/
- https://www.cnblogs.com/qiu-hua/p/14905473.html
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









