







 文章探讨了GPU在特定计算任务中的优势,如大规模并行处理,但也指出一维数据加法可能因内存访问模式和任务规模等因素导致GPU效率降低。通过实例比较了CUDA在加法和矩阵乘法中的表现。
文章探讨了GPU在特定计算任务中的优势,如大规模并行处理,但也指出一维数据加法可能因内存访问模式和任务规模等因素导致GPU效率降低。通过实例比较了CUDA在加法和矩阵乘法中的表现。
作者:翟天保Steven
版权声明:著作权归作者所有,商业转载请联系作者获得授权,非商业转载请注明出处
GPU一定比CPU快吗?
不一定。CUDA是一种用于并行计算的平台和编程模型,可以在NVIDIA的GPU上进行高效的并行计算。在某些特定的计算任务上,使用CUDA进行GPU计算可能比使用CPU更快,特别是对于涉及大量数据并需要并行处理的任务。GPU在处理大规模数据集和并行计算方面通常具有优势。
然而,并不是所有的任务都适合在GPU上执行。有些任务可能更适合在CPU上执行,特别是涉及到频繁的控制流程、内存访问模式不规则或数据量较小的情况下。此外,GPU的性能还受到算法的优化程度和硬件特性的影响。
下文将通过数组加法和矩阵乘法这两种基本算法来进行对比。
配置与代码
1)配置CUDA,教程如下:
2)创建一个空项目(假设为Project1),创建一个main.cpp,右键项目->生成依赖项->生成自定义,选择CUDA(自己的版本)。
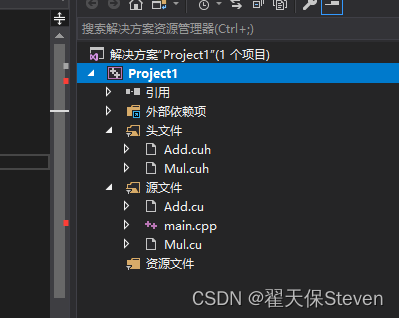
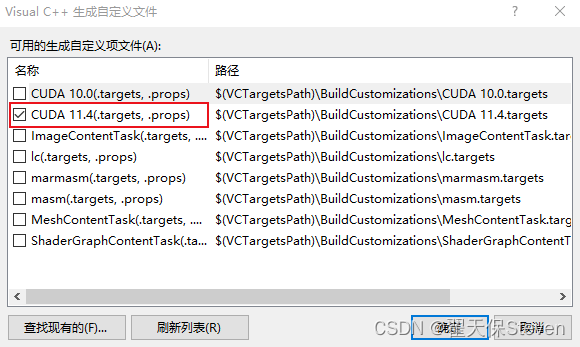
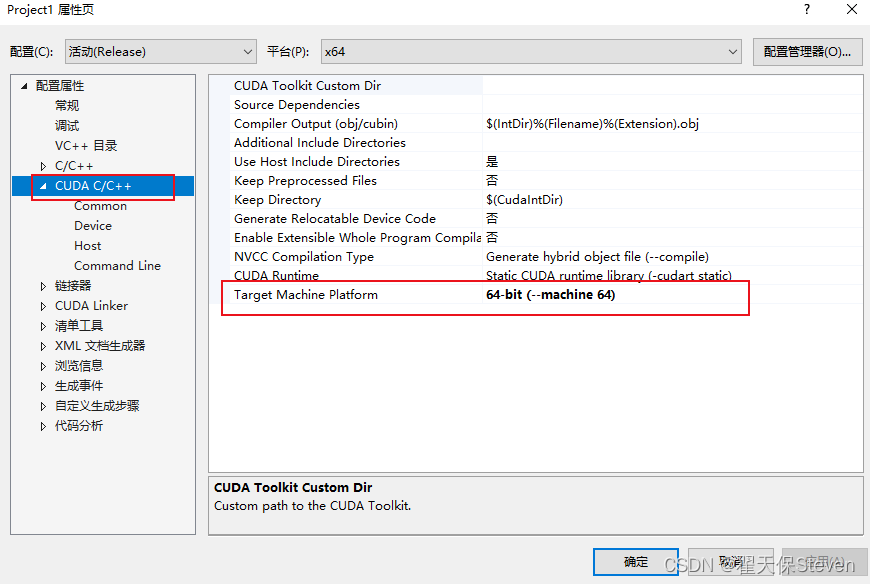
3)打开项目属性,CUDA C/C++就出来了,选平台选项,我是64位。这样就CUDA配置完成了。
4)头文件创建Add.cuh和Mul.cuh,源文件创建Add.cu和Mul.cu,将如下代码分别输入。__global__的意思就是用设备(GPU)运行。然后把这四个文件右键->属性->项类型,改为CUDA C/C++。
Add.cuh
#ifndef ADD_H
#define ADD_H
void vectorAddCUDA(const float* a, const float* b, float* c, int size);
#endif // ADD_HAdd.cu
#include <cuda_runtime.h>
#include "Add.cuh"
__global__ void vectorAddGPU(const float* a, const float* b, float* c, int size)
{
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < size)
{
c[idx] = a[idx] + b[idx];
}
}
void vectorAddCUDA(const float* a, const float* b, float* c, int size)
{
float *d_a, *d_b, *d_c;
cudaMalloc((void**)&d_a, size * sizeof(float));
cudaMalloc((void**)&d_b, size * sizeof(float));
cudaMalloc((void**)&d_c, size * sizeof(float));
cudaMemcpy(d_a, a, size * sizeof(float), cudaMemcpyHostToDevice);
cudaMemcpy(d_b, b, size * sizeof(float), cudaMemcpyHostToDevice);
dim3 threadsPerBlock(256);
dim3 blocksPerGrid((size + threadsPerBlock.x - 1) / threadsPerBlock.x);
vectorAddGPU << <blocksPerGrid, threadsPerBlock >> > (d_a, d_b, d_c, size);
cudaMemcpy(c, d_c, size * sizeof(float), cudaMemcpyDeviceToHost);
cudaFree(d_a);
cudaFree(d_b);
cudaFree(d_c);
}
Mul.cuh
#ifndef MUL_H
#define MUL_H
void vectorMulCUDA(const float* a, const float* b, float* c, int N);
#endif // MUL_HMul.cu
#include <vector>
#include <cuda_runtime.h>
#include "Mul.cuh"
__global__ void vectorMulGPU(const float* a, const float* b, float* c, int size)
{
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
if (row < size && col < size)
{
float sum = 0.0f;
for (int k = 0; k < size; ++k)
{
sum += a[row * size + k] * b[k * size + col];
}
c[row * size + col] = sum;
}
}
void vectorMulCUDA(const float* a, const float* b, float* c, int size)
{
float *d_a, *d_b, *d_c;
cudaMalloc((void**)&d_a, size * size * sizeof(float));
cudaMalloc((void**)&d_b, size * size * sizeof(float));
cudaMalloc((void**)&d_c, size * size * sizeof(float));
cudaMemcpy(d_a, a, size * size * sizeof(float), cudaMemcpyHostToDevice);
cudaMemcpy(d_b, b, size * size * sizeof(float), cudaMemcpyHostToDevice);
dim3 threadsPerBlock(16, 16);
dim3 blocksPerGrid((size + threadsPerBlock.x - 1) / threadsPerBlock.x, (size + threadsPerBlock.y - 1) / threadsPerBlock.y);
vectorMulGPU << <blocksPerGrid, threadsPerBlock >> > (d_a, d_b, d_c, size);
cudaMemcpy(c, d_c, size * size * sizeof(float), cudaMemcpyDeviceToHost);
cudaFree(d_a);
cudaFree(d_b);
cudaFree(d_c);
}
5)在main.cpp中加上CPU测试代码,并调用GPU进行对比。
#include <iostream>
#include <vector>
#include <time.h>
#include "Add.cuh"
#include "Mul.cuh"
using namespace std;
// 预准备过程
void warmupCUDA()
{
float* dummy_data;
cudaMalloc((void**)&dummy_data, sizeof(float));
cudaFree(dummy_data);
}
void vectorAddCPU(const float* a, const float* b, float* c, int size)
{
for (int i = 0; i < size; ++i)
{
c[i] = a[i] + b[i];
}
}
void vectorMulCPU(const std::vector<float>& a, const std::vector<float>& b, std::vector<float>& c, int size)
{
#pragma omp parallel for
for (int i = 0; i < size; ++i)
{
for (int j = 0; j < size; ++j)
{
float sum = 0.0f;
for (int k = 0; k < size; ++k)
{
sum += a[i * size + k] * b[k * size + j];
}
c[i * size + j] = sum;
}
}
}
int main()
{
// 预准备
warmupCUDA();
// 加法测试
const int size = 1000000;
std::vector<float> a(size, 1.0f);
std::vector<float> b(size, 2.0f);
std::vector<float> c(size);
// CPU加法
clock_t sc1, ec1;
sc1 = clock();
vectorAddCPU(a.data(), b.data(), c.data(), size);
ec1 = clock();
cout << "add CPU time:" << float(ec1 - sc1) / 1000 << endl;
// GPU加法
clock_t sg1, eg1;
sg1 = clock();
vectorAddCUDA(a.data(), b.data(), c.data(), size);
eg1 = clock();
cout << "add GPU time:" << float(eg1 - sg1) / 1000 << endl;
// 检查错误
for (int i = 0; i < size; ++i)
{
if (c[i] != a[i] + b[i])
{
std::cerr << "Add Error: Incorrect result at index " << i << std::endl;
return 1;
}
}
std::cout << "Add successful!" << std::endl;
// 乘法测试
const int N = 1024; // 矩阵大小
std::vector<float> a1(N * N, 1.0f);
std::vector<float> b1(N * N, 2.0f);
std::vector<float> c1(N * N, 0.0f);
std::vector<float> a2(N * N, 1.0f);
std::vector<float> b2(N * N, 2.0f);
std::vector<float> c2(N * N, 0.0f);
// CPU矩阵乘法
clock_t sc2, ec2;
sc2 = clock();
vectorMulCPU(a1, b1, c1, N);
ec2 = clock();
cout << "mul CPU time:" << float(ec2 - sc2) / 1000 << endl;
// GPU矩阵乘法
clock_t sg2, eg2;
sg2 = clock();
vectorMulCUDA(a2.data(), b2.data(), c2.data(), N);
eg2 = clock();
cout << "mul GPU time:" << float(eg2 - sg2) / 1000 << endl;
// 检查结果
for (int i = 0; i < N * N; ++i)
{
if (c1[i] != c2[i])
{
std::cerr << "Mul Error: Incorrect result at index " << i << std::endl;
return 1;
}
}
std::cout << "Mul successful!" << std::endl;
return 0;
}
测试效果
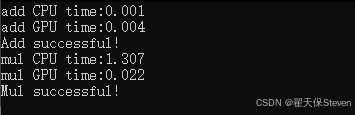
从结果中可以看出,针对一维数据的简单加法,如果用GPU反而速度慢了,而在矩阵乘法中可以很好地发挥CUDA并行策略,速度很快。针对加法速度慢的情况,我个人猜测是如下几个原因:
-
内存访问模式:CUDA的性能高度依赖于内存访问模式。一维数据的加法可能会导致不连续的内存访问,从而增加了访存延迟,降低了性能。
-
线程同步:在一维数据加法中,可能无法充分利用线程级并行性,因为每个线程可能需要等待其他线程完成其任务。
-
任务太小:在GPU上启动计算任务的开销可能会比实际的计算时间还要大,特别是对于一维数据的简单操作而言。
-
未充分利用GPU资源:一维数据加法可能无法充分利用GPU的计算资源,因为它不能很好地分解成适合GPU并行处理的任务。
本文提供的矩阵乘法和数据加法这两个函数是非常基础的,很适合初学CUDA的同学用来上手,我也初学,有经验的朋友可以多多指点。
如果文章帮助到你了,可以点个赞让我知道,我会很快乐~加油!



















 764
764

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











