







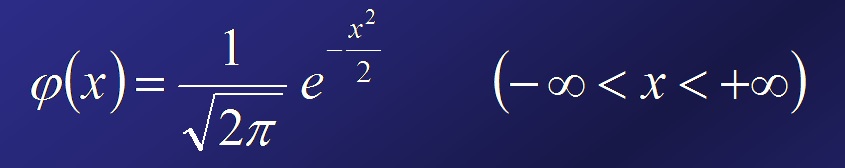
上面的公式是标准正态公布的密度函数,但为什么公式要这样写?下面是相关原因:

也就是说,公式这样写可以保证积分为1,那么为什么用e指数函数?下面是e指数函数图像:
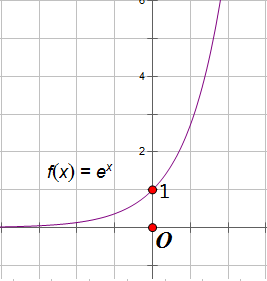
e指数函数图像特征:
过点(0,1),过第二、第一象限。
定义域是R,值域是f(x)>0
在定义域内f(x)是随着x的增大而增大。
当x -> -∞ 时f(x)=0
当x -> +∞ 时f(x)=+∞
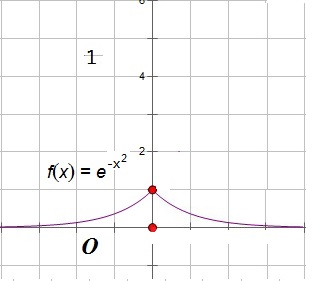
e^(-x^2/2) 函数的定义域是R, 最大值是1,也就是会把上面指数函数图像大于1的部分去掉,把左侧图像作映射补到右侧,这就接近正态分布的对称图像。
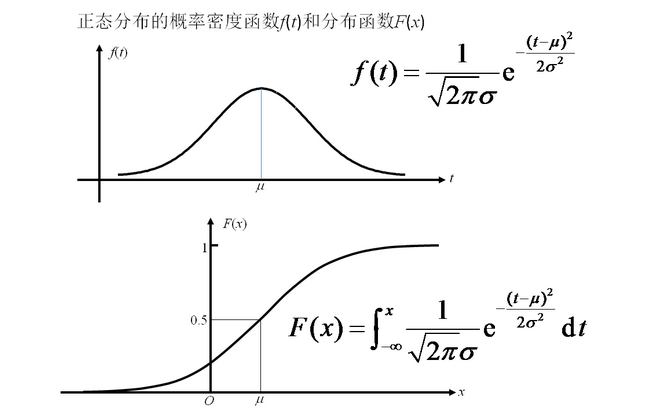
最后用正态分布的函数生成图像就成为如下图像(上面的部分)
ref: 1. 点击打开链接
2. 点击打开链接
















 1520
1520











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











