







【学习总结】
参考文献:
Bretto A. Hypergraph theory[J]. An introduction. Mathematical Engineering. Cham: Springer, 2013.
可以阅读以下文献,一个在工程领域建模的示例
https://doi.org/10.1016/j.comcom.2022.08.016
1.1 超图的定义
(1)超图
在有限集合 V V V上用 H = ( V ; E = ( e i ) i ∈ I ) H=(V;E = (e_{i})_{i∈I}) H=(V;E=(ei)i∈I)表示的超图H是 V V V的集合族 ( e i ) i ∈ I (e_{i})_{i∈I} (ei)i∈I,( I I I是有限的索引集),称为超边。有时 V V V用 V ( H ) V(H) V(H)表示, E E E用 E ( H ) E(H) E(H)表示。
令 ( e j ) j ∈ J , J ⊆ I (e_{j})_{j∈J},J⊆ I (ej)j∈J,J⊆I是 E = ( e i ) i ∈ I E=(e_{i})_{i∈I} E=(ei)i∈I的超边的一个子族,我们用 V ( U j ∈ J e j ) V(U_{j∈J}e_{j}) V(Uj∈Jej)表示属于 U j ∈ J e j U_{j∈J}e_{j} Uj∈Jej的顶点集合,但有时我们用 e e e表示 V ( e ) V(e) V(e)。例如,有时我们用 e ∩ V ‘ e∩V‘ e∩V‘来表示 V ( e ) ∩ V ‘ , V ‘ ⊆ V V(e)∩V‘,V‘⊆V V(e)∩V‘,V‘⊆V。
如果
⋃
i
∈
I
e
i
=
V
\bigcup_{i∈I}^{}e_{i}=V
i∈I⋃ei=V
则超图没有孤立顶点。如果其中顶点
x
x
x是孤立的:
x
∈
V
∖
⋃
i
∈
I
e
i
x∈V\setminus\bigcup_{i∈I}^{}e_{i}
x∈V∖i∈I⋃ei
(2)相邻、关联
如果存在包含两个顶点的超边,则超图中的两个顶点是相邻的(adjacent)。 特别是,如果 { x } {\{x\}} {x}是超边,则 x x x与其自身相邻。 如果超图中的两个超边的交点不为空,则它们是关联的( incident)。
(3)导出子超图、子超图、部分超图
详见原文。
(4)度数、秩、K-正则超图、K一致超图
详见原文。
1.2 超图示例
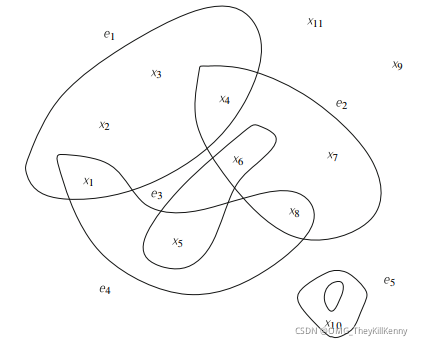
1.3 超图的代数定义
1.3.1矩阵、超图和熵
(1)关联矩阵和邻接矩阵
设
H
=
(
V
;
E
)
H = (V ; E)
H=(V;E) 是一个超图,
V
=
{
v
1
,
v
2
,
,
.
.
.
,
v
n
,
}
和
E
=
(
e
1
,
e
2
,
.
.
.
,
e
m
)
V =\{v_{1}, v_{2},, . . . , v_{n},\} 和 E = (e_{1}, e_{2}, . . . , e_{m})
V={v1,v2,,...,vn,}和E=(e1,e2,...,em)
并且
⋃
i
∈
I
e
i
=
V
\bigcup_{i∈I}e_{i} = V
i∈I⋃ei=V
(没有孤立的顶点)。 那么 H 有一个
n
×
m
n × m
n×m 关联矩阵
A
=
(
a
i
j
)
A = (a_{ij})
A=(aij) 其中:
a
i
j
=
⎱
0
其他
⎰
1
如果
v
i
∈
e
j
a_{ij} = ^{\lmoustache 1 如果v_{i}∈e_{j}}_{\rmoustache 0 其他}
aij=⎱0其他⎰1如果vi∈ej
这个矩阵也可以写成一个
m
×
n
m × n
m×n 矩阵。 例如图 1.4 左侧超图的关联矩阵是 3 × 5 矩阵:
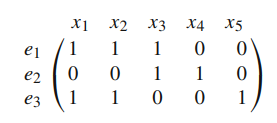

对偶矩阵,图1.4右侧,是上面矩阵的转置。也很容易看出,任何导出子超图的关联矩阵(H的子超图,部分超图)是H的关联矩阵的子矩阵。设
H
=
(
V
;
E
)
H = (V; E)
H=(V;E) 是一个超图。 H 的邻接矩阵 A(H) 定义如下:
它是一个正方形矩阵,其行和列由 H 的顶点索引,对于所有
x
,
y
∈
V
x, y ∈ V
x,y∈V ,
x
≠
y
x ≠ y
x=y 每一条
a
x
,
y
=
∣
e
∈
E
:
x
,
y
∈
e
∣
并且
a
x
,
x
=
0
a_{x,y} = |{e ∈ E : x, y ∈ e}| 并且 a_{x,x} = 0
ax,y=∣e∈E:x,y∈e∣并且ax,x=0。
这个矩阵是对称的,所有的
a
x
,
y
a_{x,y}
ax,y 都属于 N。它也是多重图的矩阵。例如图 1.4 中超图 H 的邻接矩阵为:

(2)拉普拉斯矩阵
定义
D
(
x
)
=
∑
y
∈
V
a
x
,
y
D(x)=\sum_{y∈V}a_{x,y}
D(x)=∑y∈Vax,y. H 的拉普拉斯矩阵是这样的矩阵:
L
(
H
)
=
D
−
A
(
H
)
,
其中
D
=
d
i
a
g
(
D
(
x
1
)
,
D
(
x
2
)
,
.
.
.
,
D
(
x
n
)
)
.
L(H) = D-A(H),其中D=diag(D(x_{1}), D(x_{2}), ...,D(x_{n})).
L(H)=D−A(H),其中D=diag(D(x1),D(x2),...,D(xn)).
(3)超图熵
我们可以通过以下方式定义代数上的超图熵(algebraic hypergraph entropy)
I
(
H
)
I (H)
I(H):
I
(
H
)
=
−
∑
i
=
1
n
λ
i
l
o
g
2
λ
i
I(H)=-\sum_{i=1}^{n}\lambda_{i}log_{2}\lambda_{i}
I(H)=−i=1∑nλilog2λi
1.3.2 超图的相似度和度量
(1)相似度函数
令
H
=
(
V
;
E
=
(
e
i
)
i
∈
I
)
和
H
‘
=
(
V
;
E
’
=
(
e
i
′
)
i
∈
I
)
H=(V;E=(e_{i})_{i∈I})和H‘=(V;E’=(e'_{i})_{i∈I})
H=(V;E=(ei)i∈I)和H‘=(V;E’=(ei′)i∈I)是没有空超边的超图。
令
f
P
(
E
)
和
f
P
(
E
′
)
f_{P(E)}和f_{P(E')}
fP(E)和fP(E′)是映射
f
P
(
E
)
:
P
(
E
)
→
P
(
E
)
⊆
P
(
P
(
V
)
)
f_{P(E)}:P(E)\to P(E) \subseteq P(P(V))
fP(E):P(E)→P(E)⊆P(P(V))
和
f
P
(
E
′
)
:
P
(
E
′
)
→
P
(
E
′
)
⊆
P
(
P
(
V
)
)
f_{P(E')}:P(E')\to P(E') \subseteq P(P(V))
fP(E′):P(E′)→P(E′)⊆P(P(V))
假设
f
p
(
E
)
(
A
)
=
ϕ
f_{p(E)}(A)=\phi
fp(E)(A)=ϕ表示
A
=
ϕ
A=\phi
A=ϕ和
f
p
(
E
’
)
(
A
)
=
ϕ
f_{p(E’)}(A)=\phi
fp(E’)(A)=ϕ表示
A
=
ϕ
A=\phi
A=ϕ我们现在通过以下方式定义相似度函数:
P
(
E
)
×
P
(
E
′
)
→
R
+
P(E)\times P(E') \to R^{+}
P(E)×P(E′)→R+
(
A
≠
ϕ
,
B
≠
ϕ
)
⊢
→
s
(
A
;
B
)
=
∣
f
P
(
E
)
(
A
)
∩
f
P
(
E
′
)
(
B
)
∣
∣
f
P
(
E
)
(
A
)
∪
f
P
(
E
′
)
(
B
)
∣
(A\ne\phi, B\ne \phi) \vdash\to s(A;B) = \frac{|f_{P(E)}(A)\cap f_{P(E')}(B)|}{|f_{P(E)}(A)\cup f_{P(E')}(B)|}
(A=ϕ,B=ϕ)⊢→s(A;B)=∣fP(E)(A)∪fP(E′)(B)∣∣fP(E)(A)∩fP(E′)(B)∣
有时我们会使用以下简化:
f
E
:
E
→
P
(
E
)
f_{E}:E \to P(E)
fE:E→P(E)
e
⊢
→
f
E
(
e
)
=
f
P
(
E
)
(
{
e
}
)
e\vdash\to f_{E}(e) = f_{P(E)}(\{e\})
e⊢→fE(e)=fP(E)({e})
我们现在介绍如下相似度函数:
E
×
E
′
→
R
+
E\times E' \to R^{+}
E×E′→R+
(
e
,
e
′
)
⊢
→
s
(
e
,
e
′
)
=
∣
f
P
(
E
)
(
e
)
∩
f
P
(
E
′
)
(
e
′
)
∣
∣
f
P
(
E
)
(
e
)
∪
f
P
(
E
′
)
(
e
′
)
∣
(e, e') \vdash\to s(e, e') = \frac{|f_{P(E)}(e)\cap f_{P(E')}(e')|}{|f_{P(E)}(e)\cup f_{P(E')}(e')|}
(e,e′)⊢→s(e,e′)=∣fP(E)(e)∪fP(E′)(e′)∣∣fP(E)(e)∩fP(E′)(e′)∣
(2)示例
详见原文。
1.3.2.1 正核和相似度
详见原文。
1.3.2.2 超图的度量和相似度
命题 设 H = (V ; E) 是在 E 上的单射映射的超图(即
f
(
e
)
=
f
(
e
′
)
=
⇒
e
=
e
′
f (e) = f (e' ) =⇒ e = e'
f(e)=f(e′)=⇒e=e′ )并且 s 是一个相似度函数,那么:
s
~
(
e
,
e
′
)
=
1
−
s
(
e
,
e
′
)
是一个度量
\widetilde{s}(e, e') = 1- s(e, e')是一个度量
s
(e,e′)=1−s(e,e′)是一个度量。
证明
详见原文。
所以
s
~
(
e
,
e
′
)
\widetilde{s}(e, e')
s
(e,e′)是一个称为超图相似度的度量。
请注意,如果
f
f
f 不是单射映射,则
s
~
(
e
,
e
′
)
\widetilde{s}(e, e')
s
(e,e′) 是伪度量,即度量定义中的公理 1 不正确。
1.3.3 超图态射;群与对称
详见原文。
1.4 超图的推广
超图的概念可以通过允许超边变成顶点来概括。 因此,超边 e 可能不仅包含顶点,还可能包含超边,这将被认为与 e 不同。 例如:
- 令 V = { x 1 ; x 2 ; x 3 } V=\{x_{1};x_{2};x_{3}\} V={x1;x2;x3}
- E = { e 1 = { x 1 ; x 2 } ; e 1 = { x ! ; x 2 ; e 1 } ; e 1 = { x ! ; e 1 ; e 2 } } E=\{e_{1}=\{x_{1};x_{2}\};e_{1}=\{x_{!};x_{2};e_{1}\};e_{1}=\{x_{!};e_{1};e_{2}\}\} E={e1={x1;x2};e1={x!;x2;e1};e1={x!;e1;e2}}
这类超图的关联矩阵是一个矩阵,其大小是E的基数和V的基数加上E的基数。
例如下面的矩阵是上述超图的关联矩阵:


















 1436
1436

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









