







想要在移动端部署CNN,需要模型大小比较小、时耗比较低,才能适用于算力和内存受限的移动设备。
空域滤波
从通信的内容出发,尽量减少要通信的数据量,对传输的内容进行过滤、压缩或者量化,减少每一次传输所需的时间。
模型过滤
比较直观的方法是对模型参数进行过滤。如果一次迭代过程中某些参数没有明显变化,则可以将其过滤掉,从而减少通信量。实践中,在训练的后期,众多的参数会趋于收敛,只需要保留少量的参数更新信息,整个模型学习的结果就可以有效地保留下来。
模型低秩化处理
模型过滤通过去除不重要的参数来减少通信量,而模型低秩化处理则通过低秩分解压缩参数来减少通信量。这种方法探索了
参数中的低秩结构,其具体做法是通过矩阵低秩分解,如SVD分解,将原来比较大的参数矩阵分解为几个比较小的矩阵的乘积。在网络通信的时候实际传输的是分解得到的比较小的矩阵,在传输之后再重新恢复成比较大的参数矩阵。
奇异值分解
模型量化
通过对要传输的信息的精度进行控制来降低通信代价。这种方法通过降低参数的每一维浮点数的精度来减少通信量。
卷积神经网络
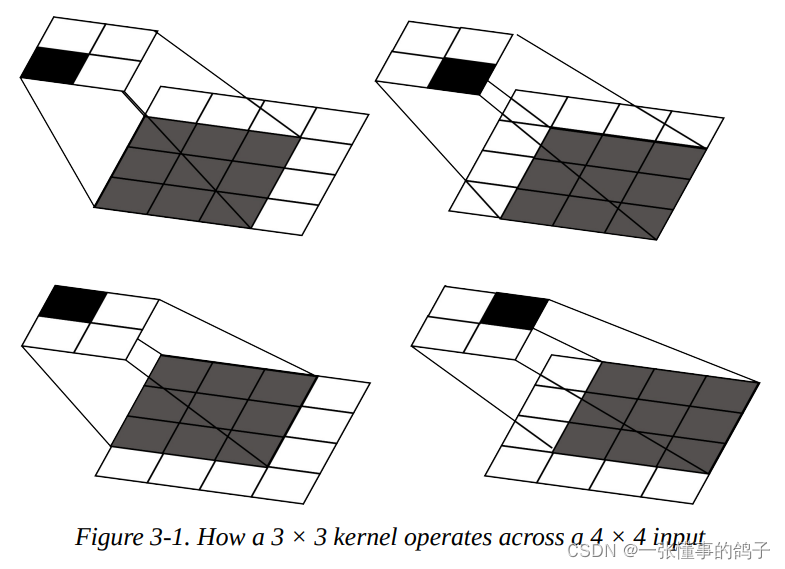
典型的非线性模型,引入局部连接的概念,并且在空间上平铺具有同样参数结构的滤波器(卷积核)。这些滤波器之间有很大的重叠区域,相当于有个空域滑窗,在滑窗滑到不同位置时,对这个窗内的信息使用同样的滤波器进行分析。这样虽然网络很大,但是由于不同位置的滤波器共享参数,其实模型参数的个数并不多,参数效率很高。
所谓卷积就是卷积核的各个参数和图像中空间位置对应的像素值进行点乘再求和。
池化一般不是参数化的模块,而是用确定性的方法求出局部区域内的平均值、中位数或最大值、最小值。


















 3249
3249

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











