







 本文详细介绍了OpenCV2.4.9中随机森林(Random Trees)的原理,包括Bootstrap过程、决策树的多样性策略以及OOB误差评估。随机森林由多棵不相关的决策树组成,通过两次随机过程确保多样性和准确性。在训练过程中,通过Bootstrap采样和随机选择特征属性减少噪声和偏差,同时利用OOB误差评估预测性能。此外,还介绍了如何计算特征属性的重要性。
本文详细介绍了OpenCV2.4.9中随机森林(Random Trees)的原理,包括Bootstrap过程、决策树的多样性策略以及OOB误差评估。随机森林由多棵不相关的决策树组成,通过两次随机过程确保多样性和准确性。在训练过程中,通过Bootstrap采样和随机选择特征属性减少噪声和偏差,同时利用OOB误差评估预测性能。此外,还介绍了如何计算特征属性的重要性。
一、原理
随机森林(Random Forest)的思想最早是由Ho于1995年首次提出,后来Breiman完整系统的发展了该算法,并命名为随机森林,而且他和他的博士学生兼同事Cutler把Random Forest注册成了商标,这可能也是Opencv把该算法命名为Random Trees的原因吧。
一片森林是由许多棵树木组成,森林中的每棵树可以说是彼此不相关,也就是说每棵树木的生长完全是由自身条件决定的,只有保持森林的多样性,森林才能更好的生长下去。随机森林算法与真实的森林相类似,它是由许多决策树组成,每棵决策树之间是不相关的。而随机森林算法的独特性就体现在“随机”这两个字上:通过随机抽取得到不同的样本来构建每棵决策树;决策树每个节点的最佳分叉属性是从由随机得到的特征属性集合中选取。下面就详细介绍这两次随机过程。
虽然在生成每棵决策树的时候,使用的是相同的参数,但使用的是不同的训练集合,这些训练集合是从全体训练样本中随机得到的,这一过程称之为bootstrap过程,得到的随机子集称之为bootstrap集合,而在bootstrap集合的基础上聚集得到的学习模型的过程称之为Bagging (Bootstrap aggregating),那些不在bootstrap集合中的样本称之为OOB(Out Of Bag)。Bootstrap过程为:从全部N个样本中,有放回的随机抽取S次(在Opencv中,S=N),由于是有放回的抽取,所以肯定会出现同一个样本被抽取多次的现象,因此即使S=N,也会存在OOB。我们可以计算OOB样本所占比率:每个样本被抽取的概率为1/N,未被抽取的概率为(1-1/N),抽取S次仍然没有被抽到的概率就为(1-1/N)S,如果S和N都趋于无穷大,则(1-1/N)S≈e-1=0.368,即OOB样本所占全部样本约为36.8%,被抽取到的样本为63.2%。随机森林中的每棵决策树的bootstrap集合是不完全相同的,因此每棵决策树的OOB集合也是不完全相同的,所以对于训练集合中的某个样本来说,它可能属于决策树Ti的bootstrap集合,而属于决策树Tj的OOB集合。
因为在生成每棵决策树之前,都要进行bootstrap过程,而每次bootstrap过程所得到的bootstrap集合都会不同,所以保证了每棵决策树的不相关以及不相同。
为了进一步保证决策树的多样性,Breiman又提出了第二个随机性。一般的决策树是在全部特征属性中进行计算,从而得到最佳分叉属性,决策树的节点依据该属性进行分叉。而随机森林的决策树的最佳分叉属性是在一个特征属性随机子集内进行计算得到的。在全部p个特征属性中,随机选择q个特征属性,对于分类问题,q可以为p的平方根,对于回归问题,q可以为p的三分之一。对于随机森林中的所有决策树,随机子集内的特征属性的数量q是固定不变的,但不同的决策树,这q个特征属性是不同,而对于同一棵决策树,它的全部节点应用的是同一个随机子集。另外由于q远小于p,所以构建决策树时无需剪枝。
以上内容是在训练过程中,随机森林与其他基于决策树算法的不同之处。而在预测过程中,方法基本相同,预测样本作用于所有的决策树,对于分类问题,利用投票的方式,最多得票数的分类结果即为预测样本的分类,对于回归问题,所有决策树结果的平均值即为预测值。
再回到前面的训练过程中,为什么我们要使用Bagging方法?这是因为使用Bagging方法可以减小训练过程中的噪声和偏差,并且更重要的是,它还可以评估预测的误差和衡量特征属性的重要程度。
常用的评估机器学习算法的预测误差方法是交叉验证法,但该方法费时。而Bagging方法不需要交叉验证法,我们可以计算OOB误差,即利用那些36.8%的OOB样本来评估预测误差。已经得到证明,OOB误差是可以代替bootstrap集合误差的,并且其结果近似于交叉验证。OOB误差的另一个特点是它的计算是在训练的过程中同步得到的,即每得到一棵决策树,我们就可以根据该决策树来调整由前面的决策树得到的OOB误差。对于分类问题,它的OOB误差计算的方法和步骤为:
◆构建生成了决策树Tk,k=1, 2, …, K
①用Tk预测Tk的OOB样本的分类结果
②更新所有训练样本的OOB预测分类结果的次数(如样本xi是T1的OOB样本,则它有一个预测结果,而它是T2的bootstrap集合内的样本,则此时它没有预测结果)
③对所有样本,把每个样本的预测次数最多的分类作为该样本在Tk时的预测结果
④统计所有训练样本中预测错误的数量
⑤该数量除以Tk的OOB样本的数量作为Tk时的OOB误差
对于回归问题,它的OOB误差计算的方法和步骤为:
◆构建生成了决策树Tk,k=1, 2, …, K
①用Tk预测Tk的OOB样本的回归值
②累加所有训练样本中的OOB样本的预测值
③对所有样本,计算Tk时的每个样本的平均预测值,即预测累加值除以被预测的次数
④累加每个训练样本平均预测值与真实响应值之差的平方
⑤该平方累加和除以Tk的OOB样本的数量作为Tk时的OOB误差
很显然,随着决策树的增多,OOB误差会趋于缩小,因此我们可以设置一个精度ε,当Tk的OOB误差小于ε时,我们可以提前终止迭代过程,即不必再生成Tk+1及以后的决策树了。
不仅能够预测样本,而且还能够得到样本的哪个特征属性对预测起到决定作用,即特征属性的重要性,也是机器学习的一项主要任务,并且在实际应用中越来越重要。Bagging方法在随机森林中的另一个作用就是可以计算特征属性的重要程度。目前有两种主要的方法用于计算特征属性的重要性:Gini法和置换法。Gini法依据的是不纯度减小的原则,在这里我们重点介绍置换法。
置换法依据的原则是:样本的某个特征属性越重要,那么改变该特征属性的值,则该样本的预测值就越容易出现错误。置换法是通过置换两个样本的相同特征属性的值来改变特征属性的,它的具体方法是:在决策树Tk的OOB集合中随机选择两个样本xi=(xi,1,xi,2,…,xi,p)和xj=(xj,1,xj,2,…,xj,p),每个样本具有p个特征属性,这两个样本的响应值分别为yi和yj,而用Tk对这两个样本的预测值分别为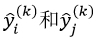
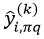
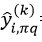
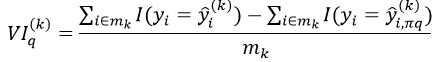
式中,分子中的第一项表示对OOB中,预测正确的样本的数量,而分子中的第二项表示置换后预测正确的样本数量。而对于回归问题,它的重要程度的量化形式为:
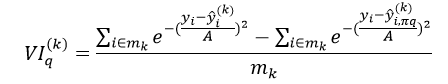
式中,
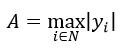
如果第q个特征属性不属于Tk,VIq(k)=0。对随机森林中的所有决策树都应用式1或式2计算第q个特征属性的重要性,则取平均得到整个随机森林对第q个特征属性的重要程度的量化形式为

最后,我们对所有的特征属性的重要程度进行归一化处理,则第q个特征属性的归一化为:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 613
613

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









