







 本文综述了图神经网络(GNN)在计算机视觉领域的应用,包括图像分类(如AlexNet、VGGnet、GoogleNet、ResNet、SENet)、目标检测(R-CNN系列、YOLO、SSD)、图像分割(FCN、Mask R-CNN)、图像重构(部分卷积、DeepFill v1)、图像生成(GAN、PixelCNN、BigGAN)、视觉问答(VQA)和行为识别。GNN因其强大的图数据拟合能力和推理能力,在这些任务中展现出优势,未来发展方向在于提高推理任务的性能和应对超大规模图的建模。
本文综述了图神经网络(GNN)在计算机视觉领域的应用,包括图像分类(如AlexNet、VGGnet、GoogleNet、ResNet、SENet)、目标检测(R-CNN系列、YOLO、SSD)、图像分割(FCN、Mask R-CNN)、图像重构(部分卷积、DeepFill v1)、图像生成(GAN、PixelCNN、BigGAN)、视觉问答(VQA)和行为识别。GNN因其强大的图数据拟合能力和推理能力,在这些任务中展现出优势,未来发展方向在于提高推理任务的性能和应对超大规模图的建模。
摘 要:近几年,机器学习和深度学习发展迅速。研究人员借鉴了卷积神经网络(CNN)、循环神经网络(RNN)和深度自动编码器(AutoEncoder)的思想,定义和设计了用于处理图数据的神经网络结构,这类方法统称为图神经网络(Graph Neural Networks,GNN)。如今,GNN在人工智能领域应用广泛,其中最大应用领域之一是计算机视觉(Computer Vision, CV)。近年来,国内外许多研究机构和科研人员不断探索利用GNN解决图像分类、目标检测、动作识别等多种计算机视觉任务,并取得很多优秀成果。
关键词:GNN;计算机视觉;深度学习
1引 言
计算机视觉是以图像或视频为输入,以对环境的表达和理解为目标,研究图像信息组织、物体和场景识别、进而对事件给予解释的学科,诞生于1966年MIT AI Group的“the summer vision project”。计算机视觉经过50余年的发展,已成为一个十分活跃的研究领域。据统计,目前互联网上超过70%的数据是图像和视频,全世界的监控摄像头数目已超过人口数,每天生成超过八亿小时的监控视频数据。如此大的数据量亟待自动化的视觉理解与分析技术。作为深度学习的新兴领域,GNN因强大而灵活的特性,在计算机视觉的相关任务上取得不俗成绩。本文主要介绍GNN在图像分类(Image Classification)、目标检测(Object Detection)、图像分割(Object Segmentation)、图像重构(Image Reconstruction)、图像生成(Image Synthesis)、视觉问答(Visual Question & Answering,VOA)、行为识别(Action Recognition)、3D视觉(3D vision)等计算机视觉任务。
2 GNN在CV中应用现状
2.1 图像分类
2.1.1 概念
图像分类是指给定一组被标记为单一类别的图像,对一组新的测试图像的类别进行预测,并计算预测的准确性结果。
2.1.2 经典模型
GNN模型在图像分类研究领域始于1998年,当年Yann Lecun发表的关于卷积神经网络的探索[1],但在深度学习真正爆发之前历经了多年的沉寂。随着机器处理能力的大幅提升,以及海量的数据和先进的算法技术的涌现,陆续出现了AlexNet[2]、VGGnet[3]、GoogLeNet[4]、ResNet[5]、SENet[6]等。目前较为流行的图像分类架构是CNN,它将图像送入网络,网络再对图像数据分类。现在,大部分图像分类技术都是在ImageNet数据集上开展训练。
- AlexNet
AlexNet是(首届ImageNet竞赛)ILSVRC2012的冠军,由Alex Krizhevsky等人提出,错误率首次达到15.4%。AlexNet创新:使用ReLU激活函数;使用dropout;大量使用数据扩充技术。AlexNet极大地震动了计算机视觉领域,使人们意识到卷积神经网络的优势,促使深度学习和卷积神经网络的爆发性增长。
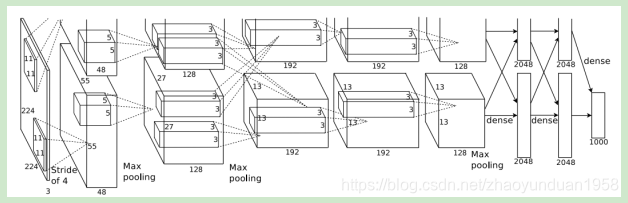
图1 AlexNet模型网络结构图
- VGGnet
VGGnet是ISLVRC2014亚军,由牛津大学的Karen Simonyan和Andrew Zisserman于2014年提出。VGGnet展示了可以在先前网络架构的基础上通过增加网络层数和深度来提高网络的性能。VGGnet包含16-19层权重网络,比先前的网络架构更深层数更多。VGGnet关键点:结构简单,只有3×3卷积和2×2卷积两种配置;参数多,且大部分参数集中在全连接层中;合适的网络初始化和使用批量归一层对训练深层网络很重要。
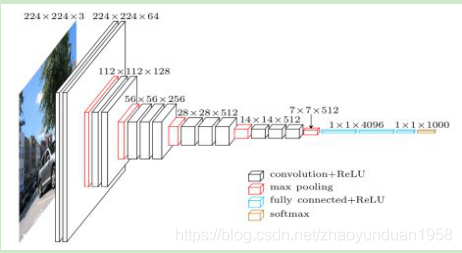
图2 VGGnet模型网络结构图
(3)GoogleNet
GoogleNet是ISLVRC2014冠军,是由Google的Christian Szegedy等人提出的22层神经网络,错误率仅6.7%。该模型架构极大改善了计算机计算资源的利用率:模型的计算开销在深度和宽度增加的情况下保持常数。GoogleNet在模型中引入Inception模块,利用非序列化的并行方式来提高模型的性能。
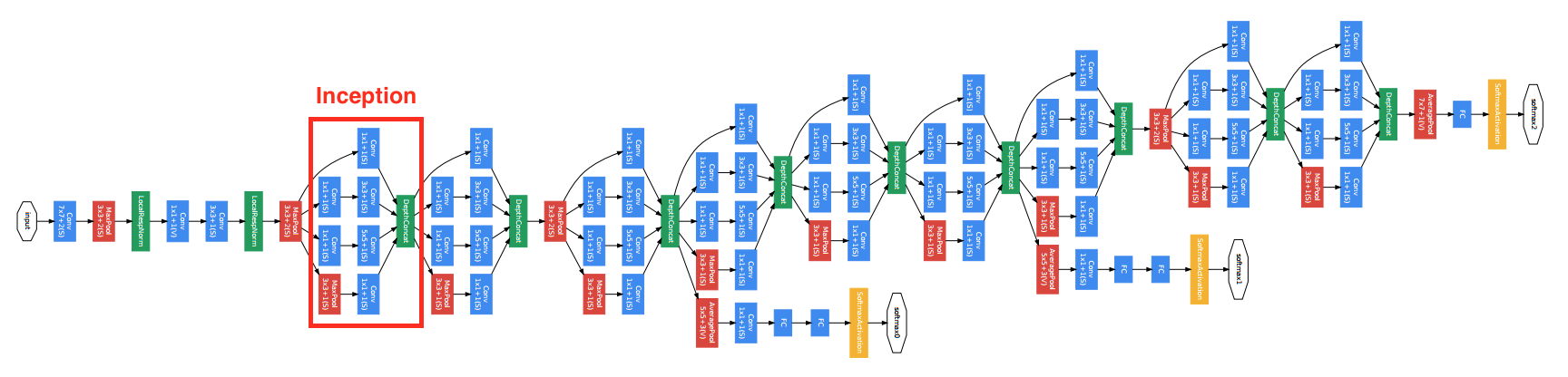
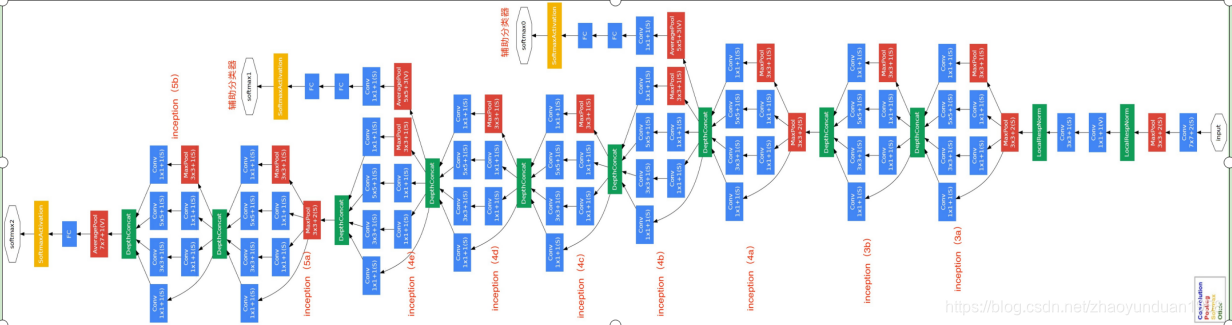
图3 GoogleNet模型网络结构图
(4)ResNet
ResNet是ILSVRC2015冠军,由微软的Kaiming He等人提出。ResNet旨在解决网络加深后训练难度增大的问题。ResNet创新:使用快捷连接,使训练深层网络更容易,并且重复堆叠相同的模块组合;大量使用批量归一层;对于深层网络(超过50层),ResNet使用了更高效的瓶颈(bottleneck)结构。
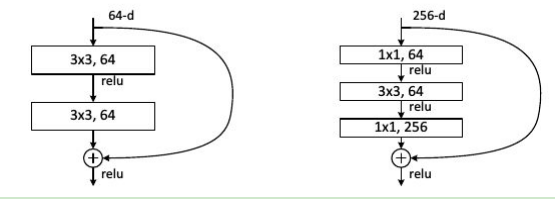
图4 快捷结构(左图)与瓶颈结构(右图)示意图
(5)SENet
SENet是ILSCRV2017冠军。SENet包含特征压缩、激发和重配权重等过程。SENet在不引入新的空间维度的前提下,使用了“特征重标定”的策略对特征进行处理;通过学习获取每个特征通道的重要程度,根据重要性抑制或提升相应的特征,最终在当年的比赛测试集中达到2.251%的Top-5错误率。
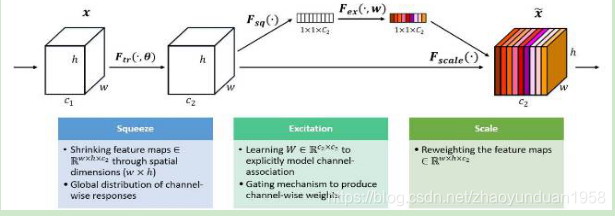
图5 SENet 模型示意图
2.1.3 图像分类算法
(1)输入是由N个图像组成的训练集,共有K个类别,每个图像都被标记为其中一个类别。
(2)使用该训练集训练一个分类器,学习每个类别的外部特征。
(3)预测一组新图像的类标签,评估分类器的性能,用分类器预测的类别标签与真实的类别标签进行比较。
2.2 目标检测
2.2.1 概念及分类
给定一张输入图片,算法自动找出图片中
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









