






半小时到秒级,京东零售定时任务优化怎么做的?
—图文分析
原作者:京东零售技术
链接:https://juejin.cn/post/7339742783236702271
来源:稀土掘金
项目背景
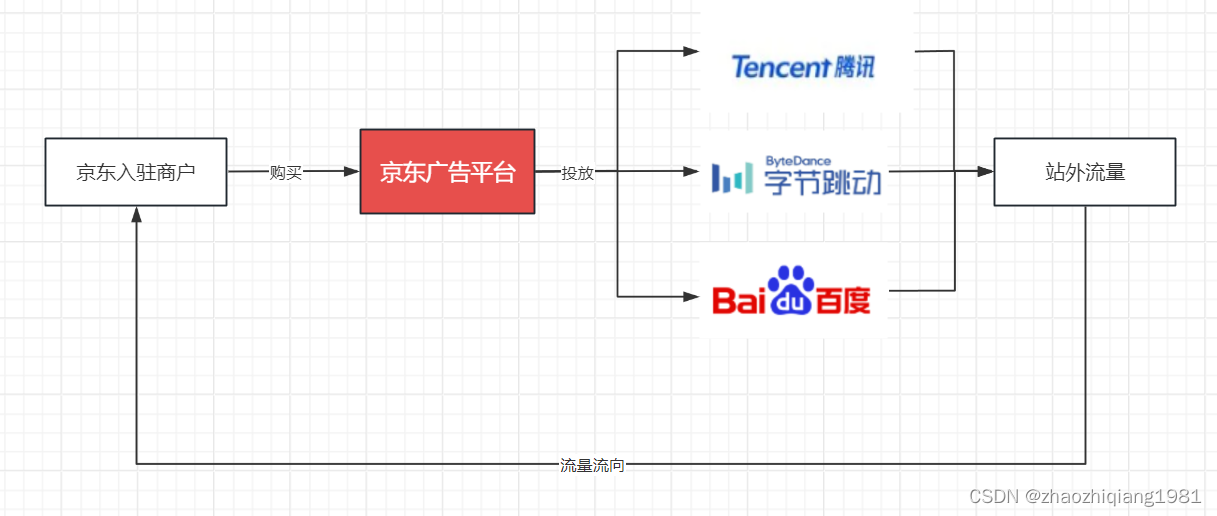
规模很大,单日最高2000万RMB
京东专门建了一张表叫做dsp_show_status
用来管理购买站外广告流量的京东用户
为了让尽可能多的商户购买广告,最小广告投放时间为半小时
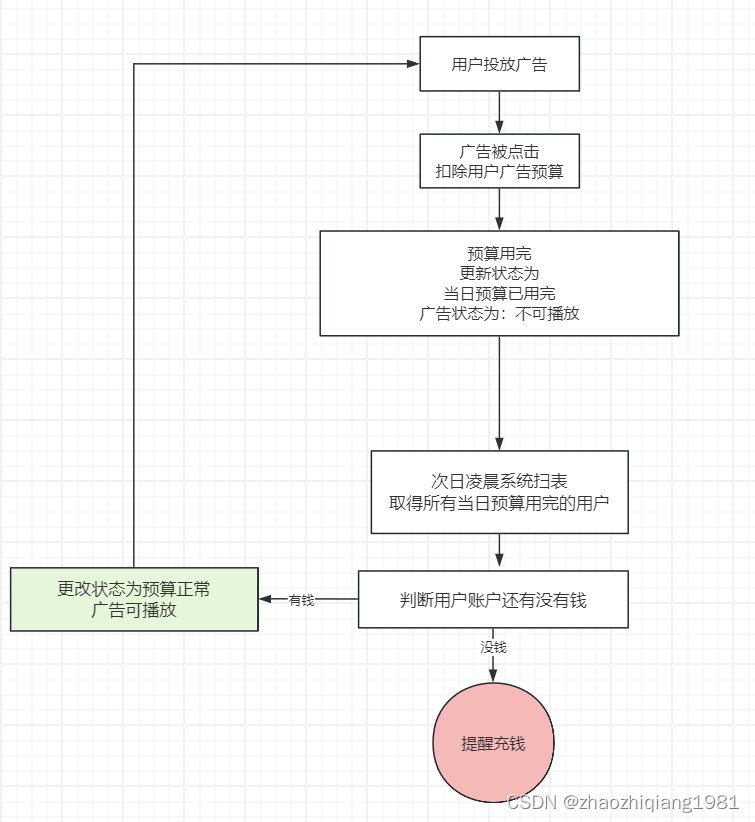
单元预算恢复任务
费用通常为:账户管理费,广告点击收费
当日预算用完后,系统更新数据库状态为当日预算已用完
第二天凌晨 定时任务扫表 扫到所有状态为预算已用完的商户 查账,账上有钱—状态恢复为可播放—第二天继续投放广告
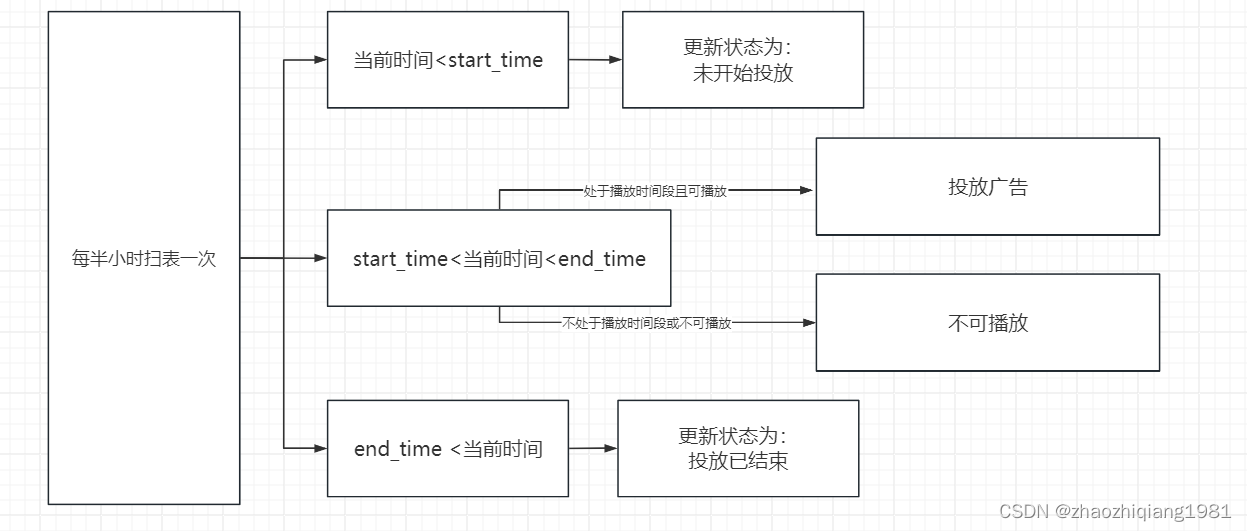
时间段更新更新任务
最小粒度–半小时
每半小时扫表一次,
找到当前时间段 可投放广告 的用户
投放广告
机器配置和垃圾回收器
单台机器用的8C16G
-Xms8192m -Xmx8192m
-XX:MaxMetaspaceSize=1024m -XX:MetaspaceSize=1024m
-XX:MaxDirectMemorySize=1966m
-XX:+UseG1GC
-XX:MaxGCPauseMillis=200
-XX:ParallelGCThreads=8
定时任务处理逻辑
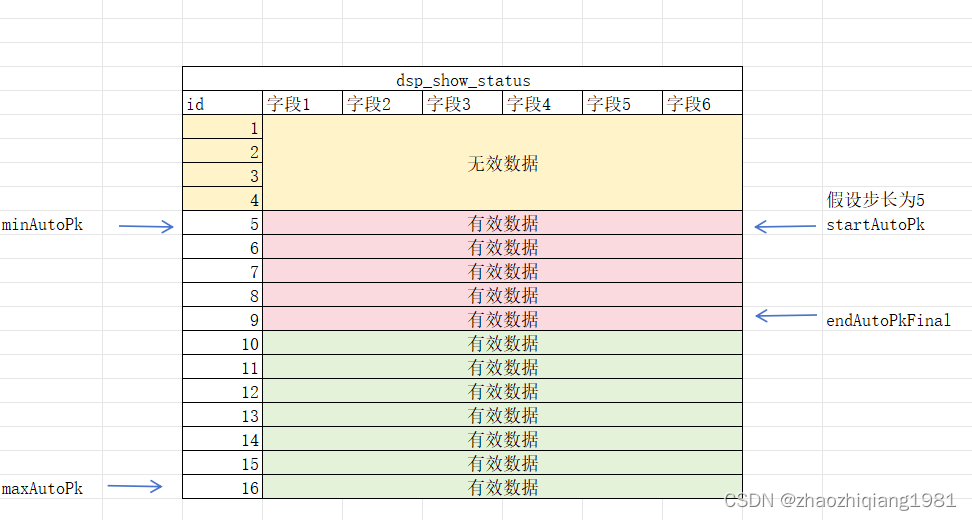
//先查出最小主键与最大主键区间,进行类似分页的逐次查询
startAutoPk=minAutoPk;
while (startAutoPk <= maxAutoPk) {
//每次循环的开始区间
startAutoPkFinal = startAutoPk;
//每次循环的结束区间
endAutoPkFinal = Math.min(startAutoPk + 步长, maxAutoPk);
List<showSatusVo> showSatusVoList =
showStatusConsumer.betweenListByParam(
startAutoPkL, endAutoPkL,
条件(type=2单元层级,不包含已过期的数据,腾讯渠道))
//showSatusVoList中取出所有id组成ids,在扩展表中查出扩展数据后进行状态更新等操作
startAutoPk = endAutoPkFinal + 1;
}
个人理解的伪SQL:
SELECT
id,cga_id,status_bitmap1,user_id
FROM
dsp_show_status
where
id BETWEEN startAutoPk AND endAutoPk
任务执行现象
(一阶段)任务执行时间长且CPU利用率高
cpu80%,且执行了半个小时才执行完成 问题非常严重,执行不会间断,客户明显感知bug
服务端:任务每半小时执行一次,一次执行半个小时…永无休止的任务…

客户端:客户选择9点开始投放,9点29分才扫到客户数据,只投放了一分钟…

(二阶段)分析数据源,调大步长缩短任务运行时间
通过分析发现:表里数据稀疏
8500万行数据中只有约150万有效数据
解决方案:调大步长(比如之前每次步长为5000,现在为4万)
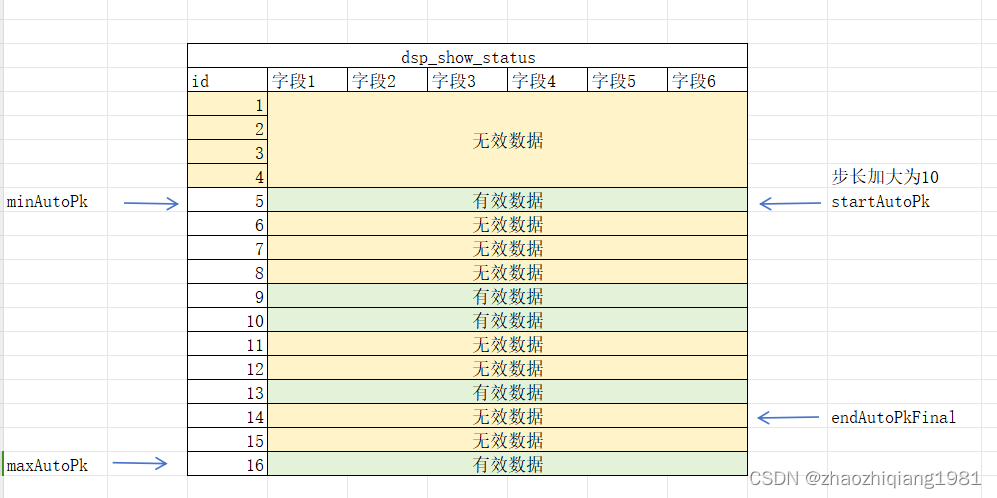
结果:时间短了,需要五分钟,cpu 飙到100%,原因是每次取过来的数据量太大了,cpu运算量大
(三阶段)减少临时对象大小和无效日志,避免多次ygc
想法一:通过mq负载多台机器减少单台cpu压力,可行,但需要增加机器,需要花钱
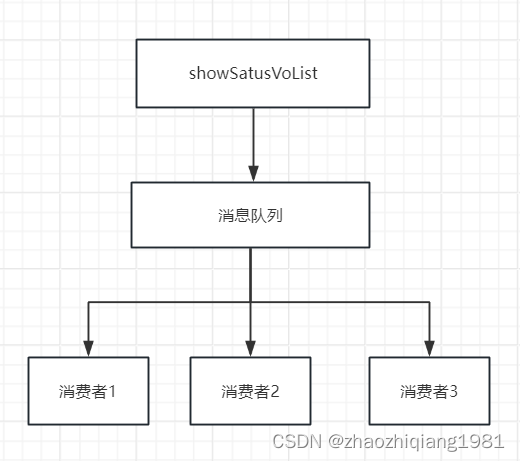
想法二(采纳):优化代码结构。
去掉无效日志(开发测试过程中随手写的log.info,log.debug),减少变量数(之前是全表查询,现在只查询关键字段,接收的实体类也只设置几个关键属性变量接收即可)。
结果:cpu降到60%
依然存在的问题一:数据库查询依然很频繁,每半小时200万的qpm,增加数据库隐患,需要减少数据库查询次数
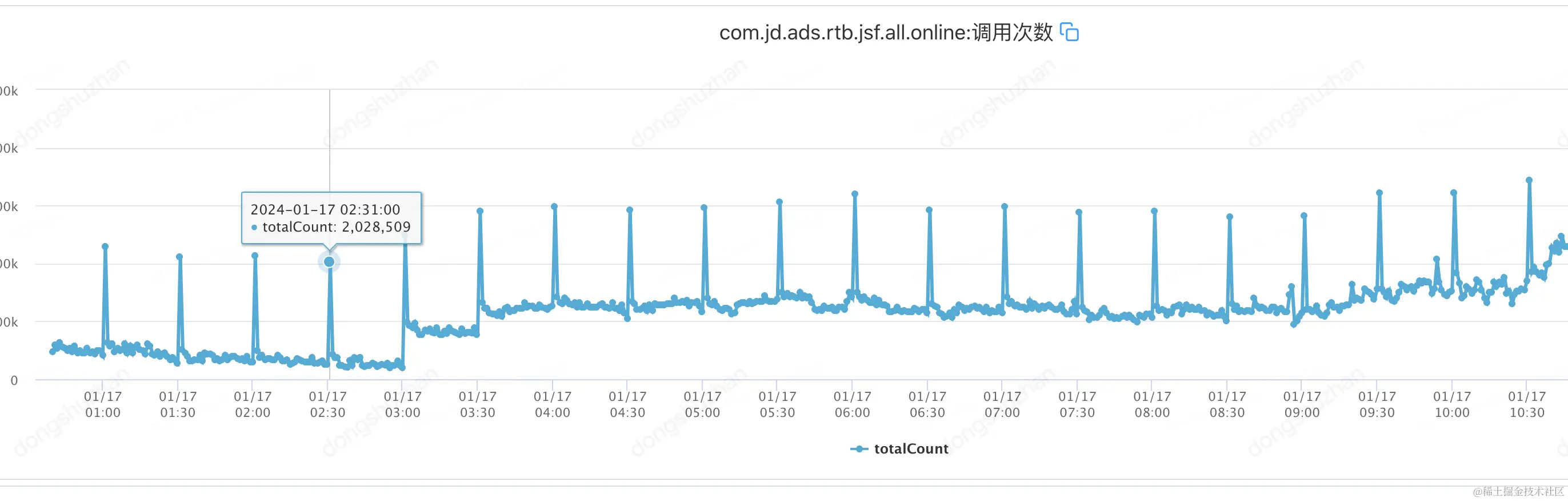
依然存在的问题二:执行时间由30分钟减少到5分钟,但客户依然能明显感知bug.
(四阶段)基于游标查询数据源,基于数据库分片批量更新,降低数据库交互次数,避免空跑缩短任务运行时间。
减少数据库qpm的方式可以通过继续调大步长的方式实现,但继续调大步长又会给cpu带来压力(本来cpu 60%也不低了)
解决方案:采用游标查询数据源
常规查询:一次性读取 500w 数据到 JVM 内存中,或者分页读取
流式查询:每次读取一条加载到 JVM 内存进行业务处理
游标查询:和流式一样,通过 fetchSize 参数,控制一次读取多少条数据
//上层业务代码
Long maxId = null;
do {
showStatuses = showStatusConsumer.betweenListByParam(
startAutoPkL, endAutoPkL, maxId,每次批次要查出来的数据,
其他条件(type=2单元层级,不包含已过期的数据,腾讯渠道)
)
if (CollectionsJ.isEmpty(showStatuses)) {
//如果为空的,直接推出,代表已经查到最后了。
break;
}
//循环变量值叠加,查出来的数据最后一行的id,数据库进行了升序,也就是这批记录的最大id
maxId = showStatuses.get(showStatuses.size() - 1).getId();
//处理查出来的数据
processShowStatuses( showStatuses);
} while (CollectionsJ.isNotEmpty(showStatuses));
//下层sql
</select>
SELECT
id,cga_id,status_bitmap1,user_id
FROM dsp_show_status
<where>
id BETWEEN #{startAutoPk,jdbcType=BIGINT} AND #{endAutoPk,jdbcType=BIGINT}
//param.maxId 上一批次查出数据的最大maxId
<if test="param.maxId != null">
AND id >#{param.maxId,jdbcType=BIGINT}
</if>
<----!其他条件------>
</where>
order by id
<if test="param.batchSize != null">
//上层传过来的每个批次要查询的出来的数据量
limit #{param.batchSize}
</if>
</select>
有效需要满足一下两个条件
1.jed表里有唯一键,且基于唯一键查询排序
2.区间满足查询条件的记录越稀疏越有效
这里要一定注意排序的顺序,是升序不是降序。如果你无意间按降序排序,那么每次查询的都是最后的满足条件的batch大小的数据。
(2)深度分页引起慢sql
问题sql:
select *
from dsp_show_status
where 其他查询条件
limit 50000000 , 10;
当limit 的初始位置非常靠后时,即使压中查询条件里的二级索引,也需从二级索引得到的主键索引去加载所有的磁盘记录,然后扫描50000000行记录取50000000到-50000010条返回,这里涉及到记录的扫描,和多次磁盘到内存的IO,所以比较耗时
select * from dsp_show_status where 其他查询条件 and id >maxId oder by id limit 100
当maxId非常大时,比如50000000 时,mysql压中查询条件的里的二级索引,得到主键索引。然后MySQL会直接过滤掉 id<50000000 的主键id,然后从主键50000000开始查询数据库得到满足条件的100条记录。所以他会非常快,并不是产生慢sql。实际sql执行只需要37毫秒。
(3) 按数据库分片进行批量更新
新的问题:
数据库网关出现了问题,超时,线程被强制关闭。
原因,数据表被分片为64片,分片键:user_id.执行的sql没有携带分片键,系统无法感知应该精准访问哪一张分片表,只能把sql分发到64张分片表一次查询
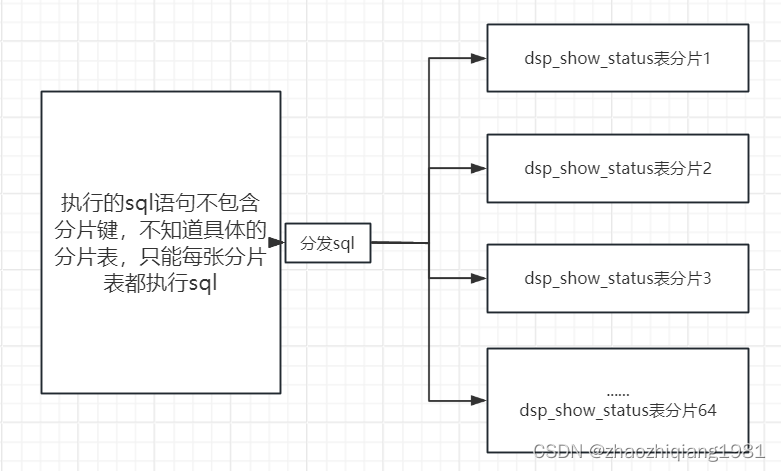
解决方案:
执行sql的时候带上分片键user_id

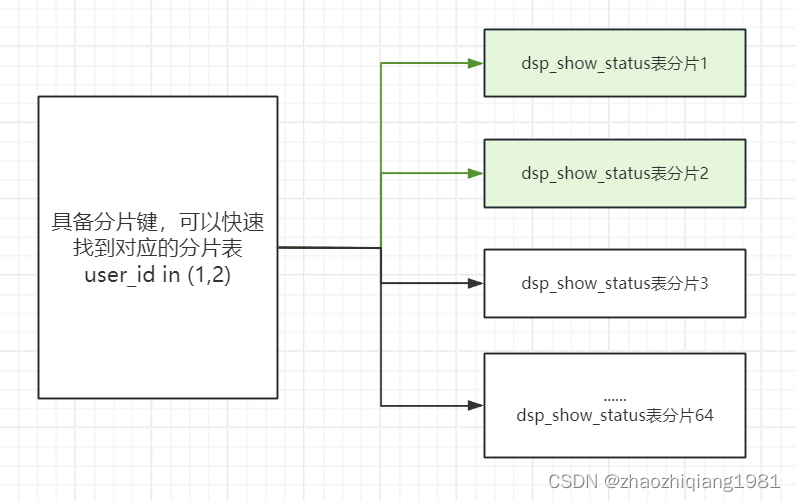
在上述的刷数任务中能够执行那么快,并且更新数据没有报错,一方面也得益于这个按数据库分片进行分组更新数据。
(五阶段)异构要更新状态的数据源,降低数据库交互次数,降低查询出来的数据量,降低机器cpu利用率。
cpu 65%,运行时长5分钟。
依然存在的问题:
1、单台机器cpu高, 仍然在60%,对于健康的程序来说,这个数值仍然不被接受。
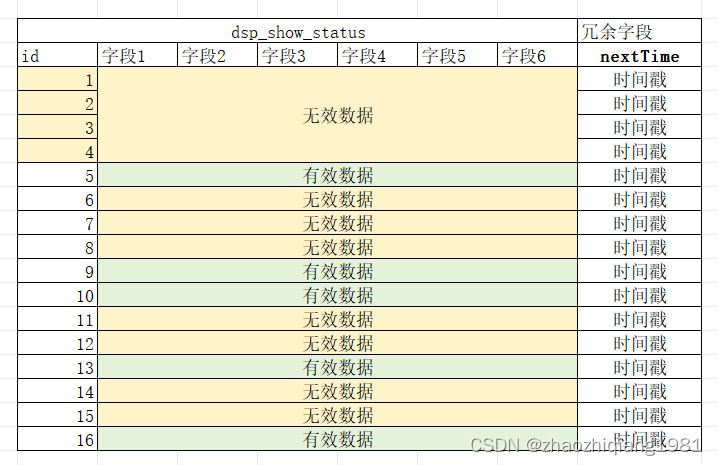
2、查询和更新数据量严重不符, 每次定时任务更新只更新了上万行记录,但是我们却查出来了上百万(130万)行记录进行子状态,这无疑还在浪费CPU和磁盘IO资源。
问题的根源:
数据库中的无效数据太多了,每次查出来一大堆的无效数据逐个判断严重影响了cpu性能。
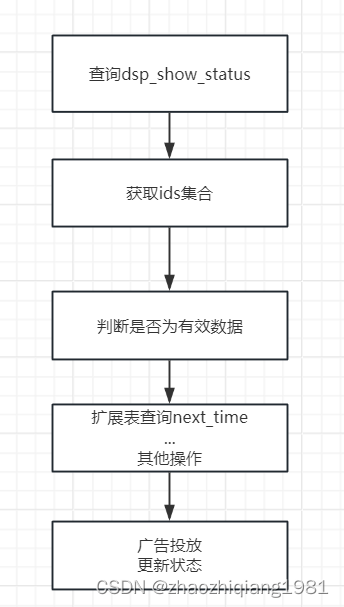
解决方案:
dsp_show_status 中直接冗余扩展表中的next_time
sql中增加查询时间范围查询条件
sql查询增加条件:
next_time_change between ADDTIME(#{param.nextTimeChange}, '-2:0:0')
and ADDTIME(#{param.nextTimeChange}, '0:30:0')
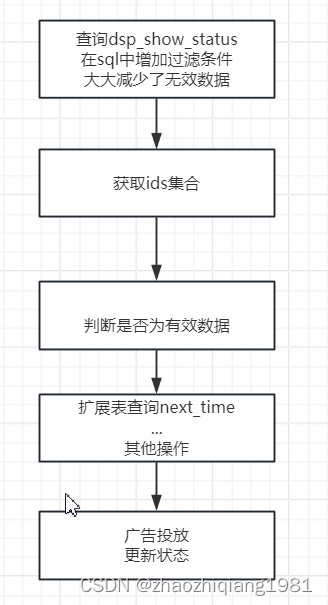
优化之后我们每次查询出来的记录从130万降到了1万左右
查询次数也从原来的1万次降到了200次
机器的监控如下cpu只用了28%,且只ygc了1次,任务执行时间30秒内完成。
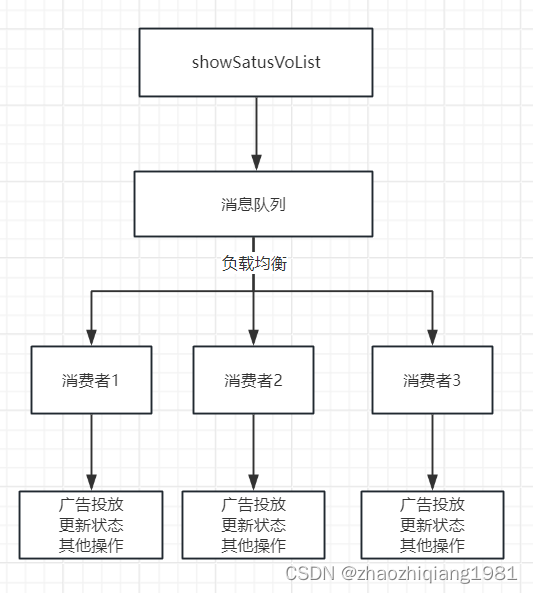
(六阶段)负载均衡,消除所有风险,让系统程序稳定运行
消除单台机器cpu不稳定的最有效办法就是,把大任务拆分为小任务,然后分发到不同的机器上进行执行。我们的定时任务本来就是按批次进行查询计算的,所以本身就是小任务。剩下的就是分发任务,很多人想到的就是利用mq的负载进行分发,但是mq不可控,不可控制失败重试时间。如果一个小任务失败了,下次什么时候被拉起重试就不得而知了,或许半个小时以后?这里用到了我们非常牛逼的一个组件,可重试总线进行负载,支持自定义重试频率,支持自动识别无效重试,防止重试叠加。
非常牛逼的组件是什么原文没有交代,个人经过搜索发现可能是京东云中的某个负载均衡组件。这里我个人把上图中的免费的mq负载均衡思路图放到下方。
消除所有风险,让系统程序稳定运行
消除单台机器cpu不稳定的最有效办法就是,把大任务拆分为小任务,然后分发到不同的机器上进行执行。我们的定时任务本来就是按批次进行查询计算的,所以本身就是小任务。剩下的就是分发任务,很多人想到的就是利用mq的负载进行分发,但是mq不可控,不可控制失败重试时间。如果一个小任务失败了,下次什么时候被拉起重试就不得而知了,或许半个小时以后?这里用到了我们非常牛逼的一个组件,可重试总线进行负载,支持自定义重试频率,支持自动识别无效重试,防止重试叠加。
非常牛逼的组件是什么原文没有交代,个人经过搜索发现可能是京东云中的某个负载均衡组件。这里我个人把上图中的免费的mq负载均衡思路图放到下方。

















 1449
1449

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









