






上一章:六、计算机视觉介绍、OpenCV
下一章:八、(一)预训练网络(Pre-trained Networks)与迁移学习(Transfer Learning)
更多章节:人工智能入门课程
目录
我们前面已经看到,神经网络非常擅长于处理图像,甚至单层感知器就能以精度识别MNIST数据集中的手写数字。然而,MNIST数据集非常特殊,所有的数字都在图像的中间,这使得任务更简单。
现实生活中,我们希望能够识别物体,不管它在图像中具体哪个位置。计算机视觉于普通的分类不同,因为当我们试图在图片中找一个特定的物体时,我们通过某个特定的模式或者它们的组合来扫描图像。例如,当寻找一只猫,我们可能首先会寻找平行线,这些平行线可以形成胡须,然后一些特定的胡须组合可以告诉我们,它实际是一张猫的图片。特定的模式的存在和相对位置非常重要,而不是它们在图像中的确切位置。
为了提取模式,我们将使用卷积滤波器的概念。正如你所知,图像使用2D矩阵,或者带颜色深度的3D张量表示。应用一个滤波器意味着,我们采用相对较小的滤波器核(filter kernel)矩阵,并针对原始图像中的每一个像素点,我们计算与相邻点的加权平均值。我们可以将这视为一个小窗口在整个图像上滑动,并根据滤波核矩阵中的权重对所有像素进行平均。
|
|
|

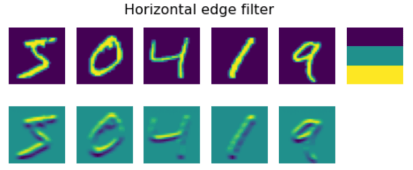
图像由Dmitry Soshnikov提供
例如,我们对MNIST数字应用3*3的垂直边缘和水平边缘滤波器,我们可以在原始图像中有垂直边缘和水平边源的地方得到一个高亮(例如,高值)。因此,这两个滤波器可以用来寻找边缘。同样,我们可以设计不同的滤波器来寻找其他低级的模式:

然而,我们可以手动设计滤波器来提取某些模式,但同时我们也可以设计网络使其自动学习模式。这是CNN背后主要的思想之一。
CNN背后的主要思想
CNN的工作方式基于以下重要思想:
- 卷积滤波器能够提取模式
- 我们能够设计网络,以自动训练滤波器
- 我们可以使用相同的方法在高级特征中寻找模式,不仅仅局限于原始图像中。所以CNN特征提取在特征层级结构上工作,从低级的像素组合开始,逐步到高级的图片部分组合。

图像来自 a paper by Hislop-Lynch, 基于 他们的研究
✍️ 练习:卷积神经网络
让我们通过相应的代码笔记,继续探索卷积神经网络的工作原理,我们如何实现可训练的滤波器:
金字塔结构
大部分的处理图像的CNN遵循所谓的金字塔架构。第一个应用于原始图片分类的卷积层,具有相对较少数量的滤波器(8-16)。对应于不同的像素组合,例如水平/垂直的笔画线条。在下一个层级,我们减少网络的空间纬度,并增加滤波器数量,这对应于更多可能的简单特征组合。在每一层,当我们向最终的分类器靠近,图像的空间纬度会降低,而滤波器数量会增加。
例如,让我们看看VGG-16的架构,该网络在2014年,在ImageNet的前5名分类中,实现了92.7%的精准度。:
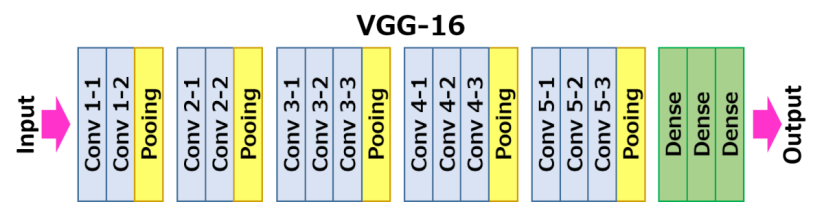
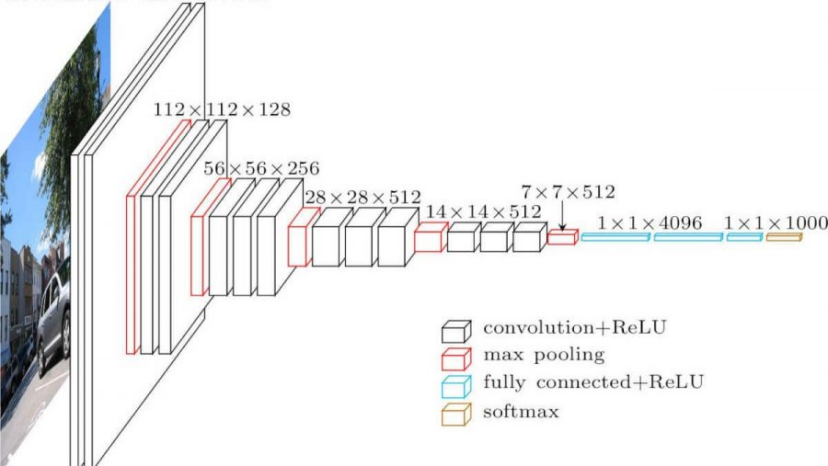
最著盛名的CNN架构
VGG-16
VGG-16是2014年在ImageNet top-5分类中准确度达到92.7%的网络。它具有以下层次结构:

如您所见,VGG 遵循传统的金字塔架构,这是一系列卷积池层序列。

图像由 Researchgate提供
残差网络(ResNet)
残差网络是由微软研究院于2015年提出的一系列模型。残差网络的思想是使用残差块:
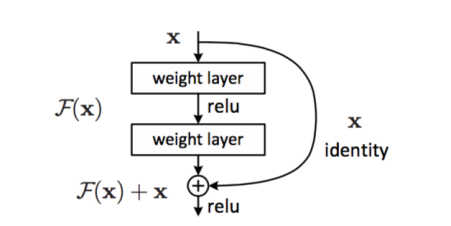
图像出自 这篇文章
使用身份传递的原因是让我们的“层”预测前一层的结果与残差块输出之间的差异,因此得名残差(residual)。这些块更容易训练,人们可以构建具有数百个这些块的网络。(最常见的变体是ResNet-52, ResNet-101 and ResNet-152)
你也可以认为这些网络可以针对数据集调整复杂度。最初,当你才开始训练网络,权重值很小,大部分信号能够通过透传身份层。随着训练进行,权重变得越来越大,网络参数的重要性随之增加,网络调节以适应正确分类训练图像所需的表达力。
Google Inception
Google Inception 架构将这种想法更进一步,将每层网络构建成几种不同路径的组合:
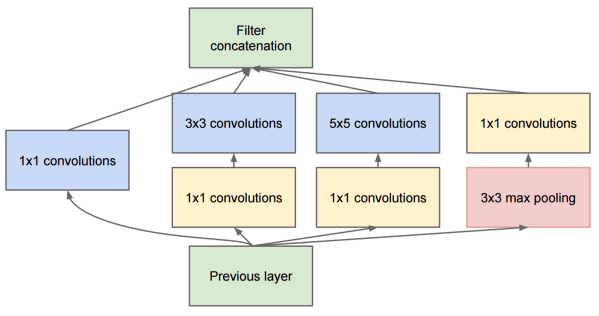
图像由 Researchgate提供
这里,我们要提到1*1卷积的作用,因为起初他们看起来并没有意义。为什么我们需要用1*1的滤波器对图像进行处理?然而,您要记住,卷积滤波器可以处理多个深度通道(最初是RGB颜色,在后续层中是不同的滤波器的通道),而1*1卷积的用于将这些输入通道使用不同的可训练权重混合在一起。这可以视为在通道维度上降采样(池化)。
移动网络(MobileNet)
移动网络是一系列减小了大小,适合移动设备的模型。如果您缺少资源,同时可以牺牲一点准确度,那么使用它们。它们背后的主要思想是所谓的深度可分离卷积,它允许通过空间卷积和深度通道上1*1的组合来表示卷积滤波器。这显著的减少了参数的数量,使得网络的大小更小,同时更容易在较少数据上进行训练。
总结
在这个单元用,你学习了计算机视觉神经网络背后的主要概念-卷积网络。现实生活中,支持图像分类,物体检测,甚至图像生成的网络都是基于CNN架构,只是具有更多层或者使了额外的训练技巧。
挑战
在随附的笔记本中,在底部有关于如何获得更高准确率的说明。做一些实验,看看您是否能取得更高准确率。
复习和自学
虽然CNN最常用于计算机视觉任务,它们通常也适用于提取固定大小的模式。例如,如果我们正在处理声音,我们可能也像使用CNN来寻找音频信号中的某些特殊模式-在这种情况下,滤波器将是1维的(这种CNN被称作1D-CNN)。此外,有时某些3D-CNN被用于在多维空间中提取特征,比如视频中发生的特定的事件-CNN能够捕获特征随时间变化的特定的模式。进行一些关于CNN可以完成的其他任务的回顾和自学。
作业
在这个实验中,您的任务是对不同的猫和狗的品种进行分类。这些图像集比MINIST数据集更复杂,及维度更高,并且有超过10个类型。
上一章:六、计算机视觉介绍、OpenCV
下一章:八、(一)预训练网络(Pre-trained Networks)与迁移学习(Transfer Learning)
更多章节:人工智能入门课程















 60万+
60万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









