






下一章:十六、循环神经网络(Recurrent Neural Networks)
更多章节:人工智能入门课程
目录
语义embeddings, 比如说Word2Vec和GloVe, 实际上是迈向语言模型的第一步-创建某种方式理解(表示)自然语言的模型。
课前练习
语言模型背后的主要思想是以无监督方式在未标记的数据集上进行训练。这很重要,因为我们拥有大量的未标记文本,而已标记的文本始终受限于我们可以用于标记的精力。大多数情况下,我们能够构建可以预测文本中缺失单词的语言模型,因为在文本中屏蔽随机单词,并把它用作训练样本很容易。
训练Embeddings
在我们前面的例子中,我们使用预训练语义embeddings,但是观察如何训练embeddings很有趣。我们可以使用的几种方法包括:
- N元语法(N-Gram )语言模型,当我们通过查看前N个词块(token)来预测一个词块(token)时。
- 连续词袋模型(Continuous Bag-of-Words (CBoW)), 当我们在词块(token)序列$W_{-N}$, ..., $W_N$.中预测中间词块(token)$W_0$ 时。
- Skip-gram, 当我们通过中间词块(token)$W_0$来预测相邻的一组token集合{$W_{-N},\dots, W_{-1}, W_1,\dots, W_N$} 时。
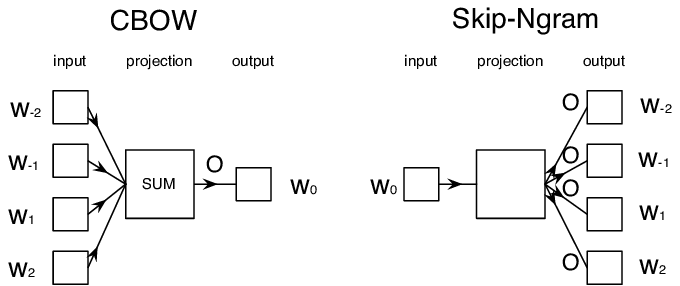
图像出自这篇论文
✍️ 示例代码笔记: 训练词袋(CBoW )语言模型
在如下代码笔记中继续您的学习:
总结
在上一节课中,我们看到了单词embeddings的神奇之处!现在我们知道了训练单词embeddings并不是很复杂的任务,同时我们应该要能够在必要时训练我们自己的特定领域的文本的单词embeddings。
课后练习
复习与自学
- PyTorch官方语言建模教程
- TensorFlow官方训练Word2Vec模型教程
- 在这个文档中讲述了如何通过gensim框架使用几行代码训练更通用的embeddings。
作业: 训练Skip-Gram 模型
在这个实验中,我们挑战您修改本课中的代码来训练Skip-Gram模型,而不是CBoW模型。查看详情
下一章:十六、循环神经网络(Recurrent Neural Networks)
更多章节:人工智能入门课程















 1281
1281

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









