






上一章:八、(二)深度学习训练技巧
下一章:十、生成对抗网络
更多章节:人工智能入门课程
目录
变分自编码器(Variational Autoencoder,VAE)
当训练CNN时,一个问题是我们需要很多标记了的数据。在图片分类的例子中,我们需要将图像分成不同的分类,这是一个手动工作。
然而,我们可能想使用未经处理(没打标签)的数据来训练CNN特征提取器,这被称为自监督学习。我们将训练图像同时作为网络的输入和输出,而不需要标签。 自编码器的主要思想是,我们使用一个编码器网络,把输入图像转换为某个隐空间(通常它只是一个大小更小的向量),然后是解码器网络,它的目标是重建原始图像。
✅ 自编码器是“一种用于学习未标记数据的有效编码的人工神经网络”。
因为我们训练自编码器是为了尽可能多的从原始图像中提取信息以准确重建图像,神经网络尝试找到输入图片的最佳“嵌入(embedding)”来提取“.л.”(图片内容)的含义。
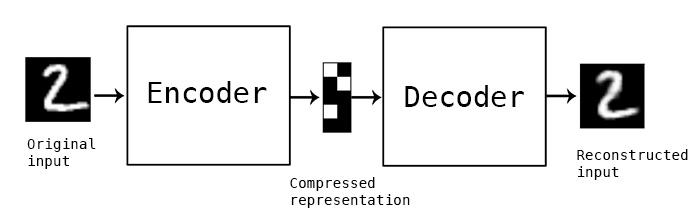
图像由Keras blog提供
使用自编码器的场景
尽管编码器在重建原始图像本身时好像没有用,但有一些场景下编码器非常有用:
- 降低图像的维度以进行可视化或者训练图像embedding。通常自编码器的结果比PCA好,因为它考虑了图像的空间特性和分层特征。
- 去燥(Denoising)即去除图像中的噪声。因为噪声携带了大量无效信息,自编码器无法将其全部放入相对较小的隐空间,所以它只提取图像重要的部分。当我们训练降噪器时,我们从原始图像开始,然后使用人为添加了噪声的图像作为自编码器的输入。
- 超分辨率(Super-resolution),增加图像的分辨率。我们从高分辨率图像开始,并使用低分辨率图像作为自编码器的输入。
- 生成(式)模型(Generative models). 一旦我们训练了自编码器,就可以使用随机潜向量利用解码器部分创建新对象。
变分自编码器(Variational Autoencoder,VAE)
传统自编码器使用某种方法减少输入数据维度,找出输入图像的重要特征。然而,潜在向量通常并不那么有意义。也就是说,以MNIST数据集为例,确定哪个数字对应于不同的潜在向量并不容易,因为接近的潜在向量(latent vector)并不一定对应相同的数字。
在另一方面,要训练生成式模型,最好对潜在空间(latent space)有一些了解。这个想法引出了变分自编码(VAE)。
VAE是学习预测潜在参数(latent parameters)的统计分布的自编码,称为潜在分布(latent distribution)。例如,我们希望潜在向量以一定的均值和标准差
服从正态分布(均值和标准差都是d维向量)。VAE中的编码器学习预测这些参数,然后解码器使用从该分布中取一个随机向量来重建对象。
总结:
- 从输入向量,我们预测z_mean和z_log_sigma(我们预测标差的对数,而不是其本身)。
- 我们从分布N(zmean,exp(zlog_sigma))中采样一个样本向量。
- 解码器尝试使用样本向量作为输入向量来解码原始图像。
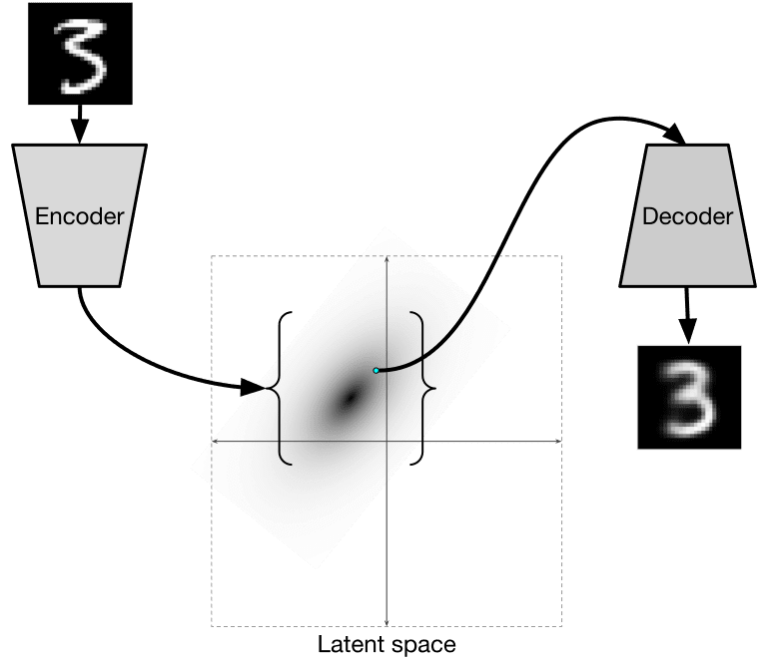
图片出自这篇博客文章 由Isaak Dykeman提供
变分自编码器使用一个复杂的由两部分组成的损失函数:
- 重建损失函数(Reconstruction loss)是显示重建的图像与目标图像接近程度的损失函数(它可以是均方误差,或者MSE)。它与普通的自编码器中的损失函数一样。
- KL损失,它确保潜在变量分布保持接近正态分布。它基于Kullback-Leibler divergence(K-L散度)的概念-一种用于评估两个统计分布相似度的指标。
VAE的一个重要优势是它允许我们比较容易的生成新图像,因为我们知道从哪个分布中抽样潜在向量。例如,如果我们使用MNIST
数据集上的2D潜在向量训练VAE,我们可以改变潜在向量上的组成部分来获得不同的数字:

图片由Dmitry Soshnikov提供
当我们开始从潜在参数空间的不同部分提取潜在向量,观察图像如何(渐变)融入彼此。我们也可以在2D中可视化这个空间。
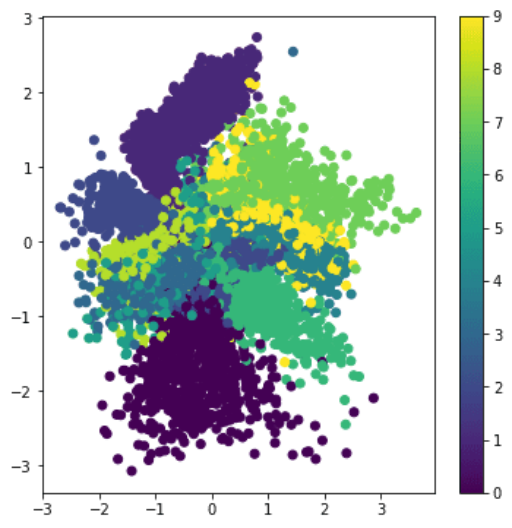
图片由Dmitry Soshnikov提供
✍️ 练习:自编码器
在这些相应的笔记本中学习更多关于自编码器的知识:
自编码器的属性
- 特定数据(Data Specific)-它们仅在它们所被训练的类型的图像上表现良好。比如,如果我们在花朵上训练超分辨率网络,它在肖像类图像上就表现不好。这是因为网络之能够从训练数据集中提取的特征中的细节来生成高分辨率图像。
- 有损(Lossy) - 重建的图与原始图像并不完全一样。损失的性质是由训练期间使用的损失函数定义的。
- 适用于未标记数据(unlabeled data)。
总结
在这节课中,您学习了AI科学家可用的各种类型的自编码器。您学习了如何构建它们,如何使用它们重建图像。您也学习了VAE以及如何使用它生成图像。
挑战
在这节课中,您学习了如何使用自编码器处理图像。但是它们也可以用来处理音乐!查看Magenta的MusicVAE子项目,它使用了自编码器来学习重建音乐。使用这个库来做一些实验 ,看看您能创造什么。
复习与自学
作为参考,阅读以下关于自编码器的资源:
作业
在本使用TensorFlow的笔记的末尾,您将发现一个“任务”-把其当作您的作业。
上一章:八、(二)深度学习训练技巧
下一章:十、生成对抗网络
更多章节:人工智能入门课程















 432
432

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









