






下一章:十一、目标检测
更多章节:人工智能入门课程
目录
在前面章节,我们了解了生成模型(generative model):可以生成与训练集中图像相似的新图像的模型。VAE是一个优秀的生成模型示例。
课前练习
然而,如果我们尝试使用VAE生成一些真正有意义的东西,比如说一幅有合理分辨率的油画,我们将发现训练并不能很好的收敛。在这种情况下,我们需要了解另一种专门用于生成模型的架构-生成对抗模型(Generative Adversarial Network),或者说GAN。
GAN 的主要思想是使用两个神经网络,并让他们进行彼此对抗训练:
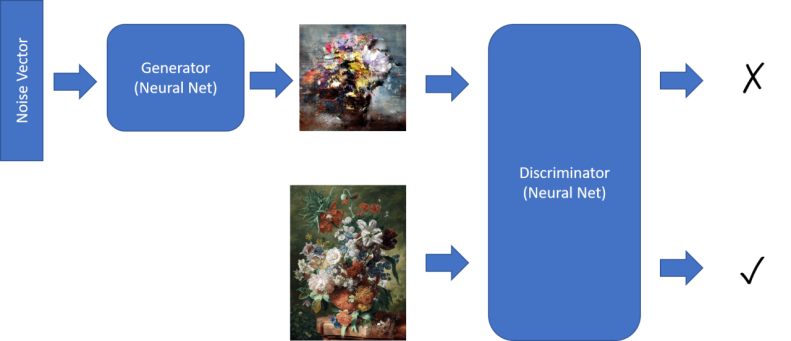
图像由Dmitry Soshnikov提供
✅ 一些术语:
- 生成器(Generator)是一个使用一些随机向量,生成图片的神经网络。
- 判别器(Discriminator)是这样一个神经网络,它输入一张图片,并判别它是一个真实图像(从训练集获取),还是由生成器生成的图像的神经网络。它实质上是一个图像分类器。
判别器
判别器的架构和普通的图像分类网络没有区别。最简单的情况下,他可以使用全连接分类器,但更常见的是使用卷积网络(CNN)。
✅ 基于卷积网络的GAN称为 深度卷积生成对抗网络(DCGAN)
判别器通常由如下几层组成:若干个卷积层+池化层(随着层级深入,图像的空间尺寸减小);一个或多个全连接层来提取图像“特征向量”;最后是一个二元分类器,该分类器仅输出两种可能的结果:图像来源是真实数据 (1) ,还是由生成器生成 (0)。
✅ “池化”是一种减小图像尺寸的技术。池化层通过将这一层的输出神经元集群组合成下一层的单个神经元,以降低数据维度。- 出处
生成器
生成器稍微棘手一些。你可以把它理解为一个“逆向判别器”。从接受一个潜在向量(代替特征向量)开始,它使用一个全连接层把潜在向量转化为所需的大小/形状,然后进行反卷积(deconvolution)+上采样(upscaling)操作逐步将信息放大,最终生成图像。这类似于自编码器的解码部分。
✅ 因为卷积层本质上是使用线性滤波器在图片上滑动来提取特征,反卷积本质上与卷积类似,可以使用相同的层逻辑来实现。
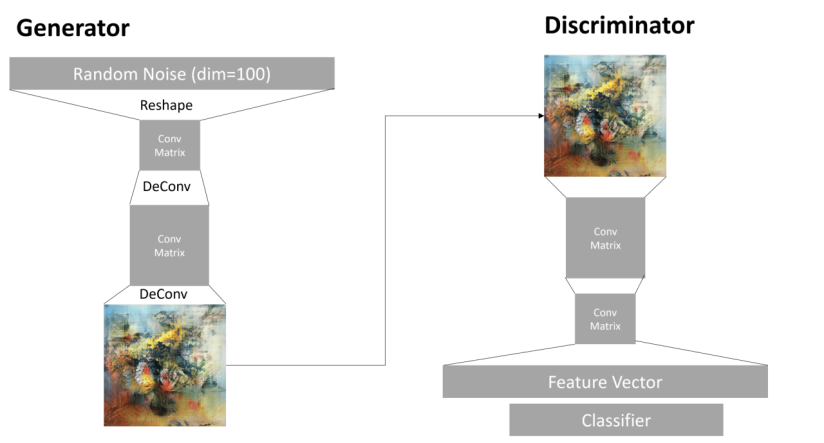
图像由Dmitry Soshnikov提供
训练GAN
GAN被称为对抗网络是因为在生成器和判别器之间存在持续的竞争。在竞争期间,生成器和判别器都会不断改进,从而网络能够通过学习,生成越来越好的图片。
训练过程分为两个阶段:
- 训练判别器:这个任务非常简单:我们使用生成器生成一批图像,把他们标记为0,作为虚假图片,从输入数据集中取一批图像,标记为1,作为真实图像。然后将这些混合图像输入判别器,并计算判别函数的损失函数的值,最后,通过反向传播算法更新判别器的参数。
- 训练生成器。这稍微复杂一些,因为我们不知道生成器期望的直接输出是什么。因此我们将整个GAN网络作为一个整体,输入一些随机向量,并期望判别器输出1,(表示真实图像).然后固定判别器的参数(因为我们不希望在这步训练它),并通过反向传播算法更新生成器的参数。
在这个过程中,生成器和判别器的损失值都不会大幅下降。在理想情况下,他们会振荡,表示两个网络都在提升自己的性能。
✍️ 练习: GAN
GAN训练中的问题
众所周知,GAN训练起来尤为困难。这是一些训练过程中存在的问题:
- 模式奔溃(Mode Collapse)。这(专业术语)指的是生成器会生成一个图像,成功的欺骗生成器,而不是各种个样的不同的图像。
- 对超参数的敏感(Sensitivity to hyperparameters)。通常您能够看到,GAN完全无法收敛,然后突然降低学习率,导致收敛。
- 在生成器和分类起之间保持平衡。在许多情况下,判别器损失值会非常迅速的降低到零,这将导致生成器无法进一步训练。为了克服这个问题,我们可以给生成器和判别器设置不同的学习率,或者当判别器损失值已经很低时,跳过判别器训练,
- 高分辨率训练。与自编码器类似,这个问题是由重构太多层卷积网络导致的伪影而引发的。这个问题通常通过渐进式增长(progressive growing)解决 ,即首先在低分辨率图像上训练少量的层,然后“解锁”或者增加层。另一个解决方法是,添加层间额外的连接,并一次训练多个分辨率--详情参阅这篇多尺度梯度GAN论文 (Multi-Scale Gradient GANs pape)。
风格迁移(Style Transfer)
GAN是一种生成艺术图像的很棒的方法。另一种有趣的技术叫做风格迁移,它使用一张内容图像,并应用风格图像的滤镜,以不同风格重新绘制它。
它的工作方式如下:
- 我们从一个随机噪声图像开始(或者从一张内容图像开始,但为了便于理解起见,从随机噪声开始更容易)
- 我们的目标是生成一张这样子的图像,它同时与内容图像和风格图像都相似。这将由两个损失函数确定:
- 内容损失是基于CNN的某些层从当前图像和内容图像提取的特征进行计算的。
- 风格损失使用格拉姆矩阵(Gram matrices,更多详细内容参阅示例笔记)以一种巧妙的方法在当前图像与风格图像之间计算。
- 为了使图像更平滑并去除噪声,我们还引入了总变分损失(Variation loss),它计算相邻像素之间的平均距离。
- 主要的优化循环使用梯度下降(或者其他优化算法)调整当前图像,以最小化总损失,总损失是所有三个损失值的加权和。
✍️ 示例:风格迁移
课后测试
总结
在这节课程中,您了解了GAN,以及如何训练它们。您也了解了这类神经网络面临的特殊挑战,以及克服这些挑战的策略。
挑战
使用您自己的图像运行风格迁移笔记。
复习与自学
参考以下资料,了解更多关于GAN的信息:
- 马尔科·帕西尼 (Marco Pasini),《一年训练GAN的10堂课》(10 Lessons I Learned Training GANs for one Year)
- StyleGAN,一个值得考虑的事实上的GAN架构。
- 在Azure ML上使用GAN创建生成式艺术
作业
重新访问与本课程相关的两个笔记之一,并使用您自己的图像重新训练GAN。您能创造出什么?
下一章:十一、目标检测
更多章节:人工智能入门课程















 195
195

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









