






Project,Github
TeaCache(Timestep Embedding Aware Cache)是一种加速diffusion模型预测的方法。
摘要
Timestep Embedding Aware Cache(TeaCache)是一种无需训练的缓存方法,它能够估计并利用模型输出在不同时间步长之间的波动差异。TeaCache 并非直接使用耗时的模型输出,而是将重点放在与模型输出具有强相关性且计算成本可忽略不计的模型输入上。TeaCache 首先利用Timestep Embedding来调制带噪输入,以确保它们之间的差异能更好地近似于模型输出之间的差异。然后,TeaCache 引入了一种缩放策略来优化估计的差异,并利用这些差异来指示输出缓存操作。
动机
扩散模型在去噪过程中,相邻时间步的输出较为相似,此前的方法提出以均匀的方式缓存模型输出来减少冗余。然而,相邻时间步的输出差异是变化的。因此,这种均匀缓存策略缺乏灵活性,无法最大限度地提高缓存利用率。更好的缓存策略是,当缓存输出与当前输出之间的差异较小时,更频繁地复用缓存输出。遗憾的是,在计算出当前输出之前,这种差异是无法预测的。为了克服这一挑战,TeaCache利用了以下先验知识:模型的输入和输出之间存在很强的相关性。
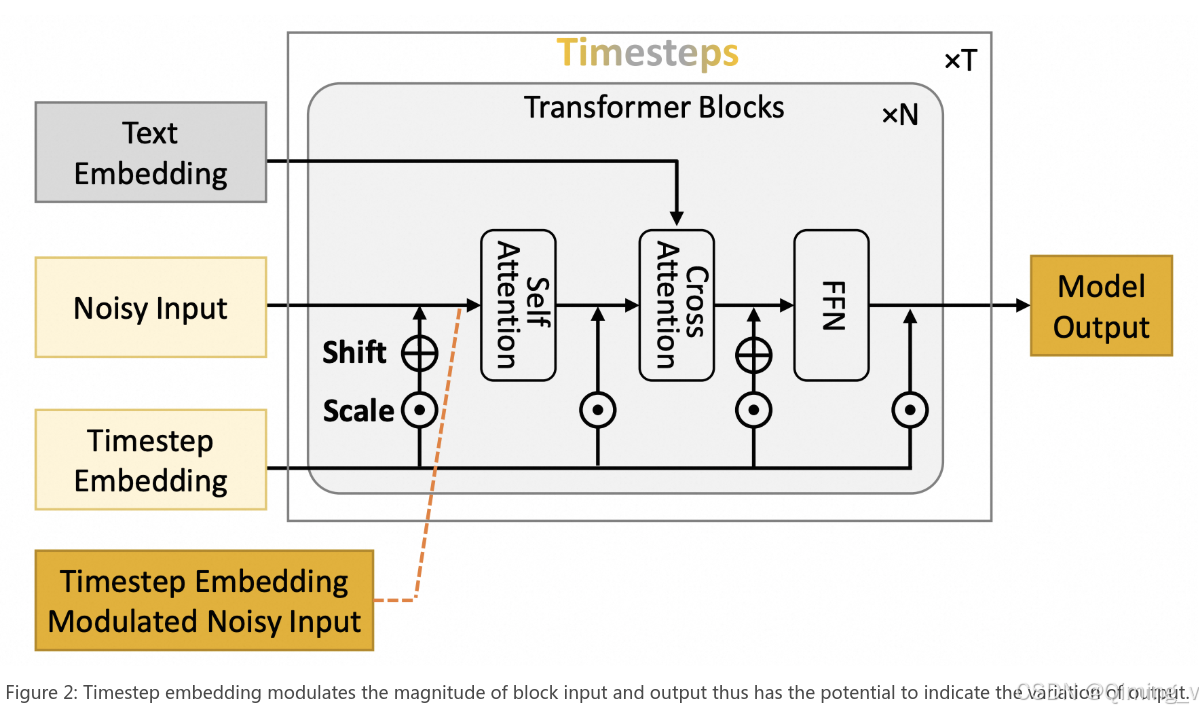
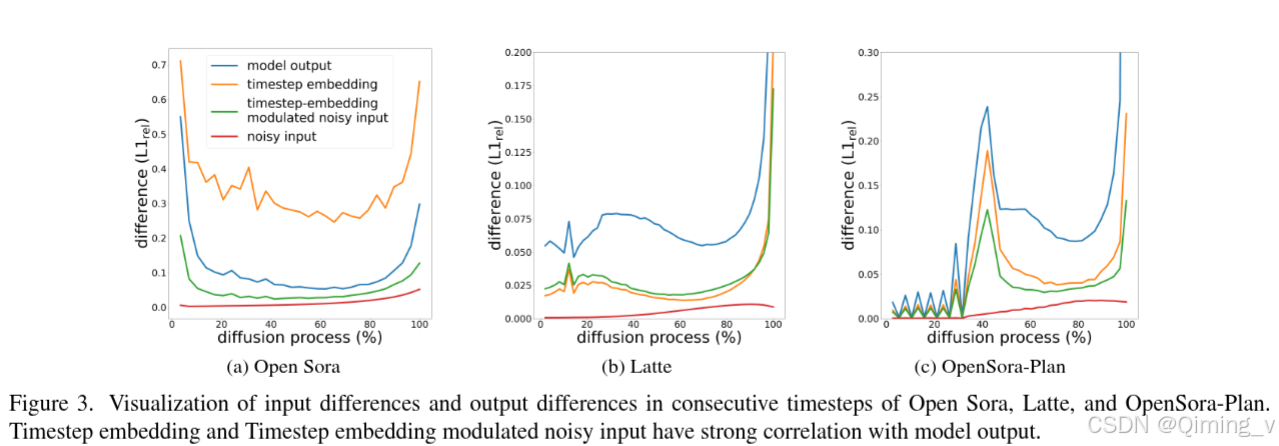
在图三中可以看到,Open Sora,Latte,OpenSora-Plan 在连续的timestep预测中,Timestep embedding 和 Timestep embedding modulated noisy 和模型输出强相关。

基于这些发现,我们提出了时间步嵌入感知缓存(TeaCache)方法。我们不再在每个时间步都计算新的输出,而是复用之前关键时间步的缓存输出。这些关键时间步是通过利用Timestep embedding 和 Timestep embedding modulated noisy之间的差异来选定的。此外,为了减少模型输出差异和时间步嵌入差异之间的估计误差,我们采用多项式拟合的方法对Timestep embedding差异进行缩放处理。
总结
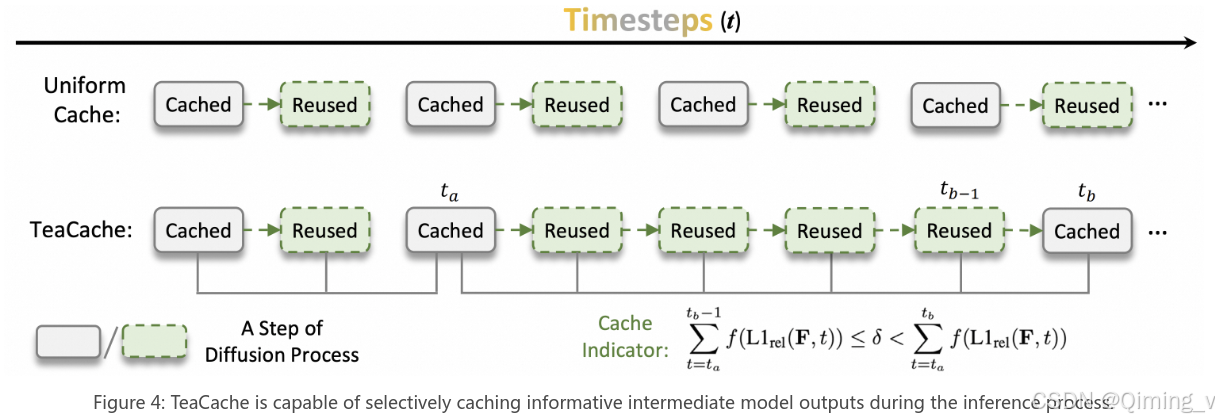
在diffusion模型去噪的过程中,相邻timestep的输出较为相似。本文发现Timestep embedding 和 Timestep embedding modulated noisy 和模型输出强相关,所以使用输入差异来代替输出差异作为判断方法。使用了多项式来拟合相邻步之间的Timestep embedding modulated noisy L1 distance作为误差判断标准,如果小于阈值,那么就用缓存的输出,如果大于阈值,就计算新的输出。
代码
TeaCache/TeaCache4FLUX/teacache_flux.py 中代码中TeaCache部分。
if self.enable_teacache:
inp = hidden_states.clone()
temb_ = temb.clone()
modulated_inp, gate_msa, shift_mlp, scale_mlp, gate_mlp = self.transformer_blocks[0].norm1(inp, emb=temb_)
if self.cnt == 0 or self.cnt == self.num_steps-1:
should_calc = True
self.accumulated_rel_l1_distance = 0
else:
coefficients = [4.98651651e+02, -2.83781631e+02, 5.58554382e+01, -3.82021401e+00, 2.64230861e-01]
rescale_func = np.poly1d(coefficients)
#图4公式
self.accumulated_rel_l1_distance += rescale_func(((modulated_inp-self.previous_modulated_input).abs().mean() / self.previous_modulated_input.abs().mean()).cpu().item())
if self.accumulated_rel_l1_distance < self.rel_l1_thresh:
should_calc = False
else:
should_calc = True
self.accumulated_rel_l1_distance = 0
self.previous_modulated_input = modulated_inp
self.cnt += 1
if self.cnt == self.num_steps:
self.cnt = 0
if self.enable_teacache:
if not should_calc:#如果不需要重新计算,新的输出就等于输出加上差值
hidden_states += self.previous_residual
else:#计算输出
ori_hidden_states = hidden_states.clone()
### diffusion unet 预测过程
hidden_states = UNet(ori_hidden_states) ###unet
#两步之间的差值
self.previous_residual = hidden_states - ori_hidden_states
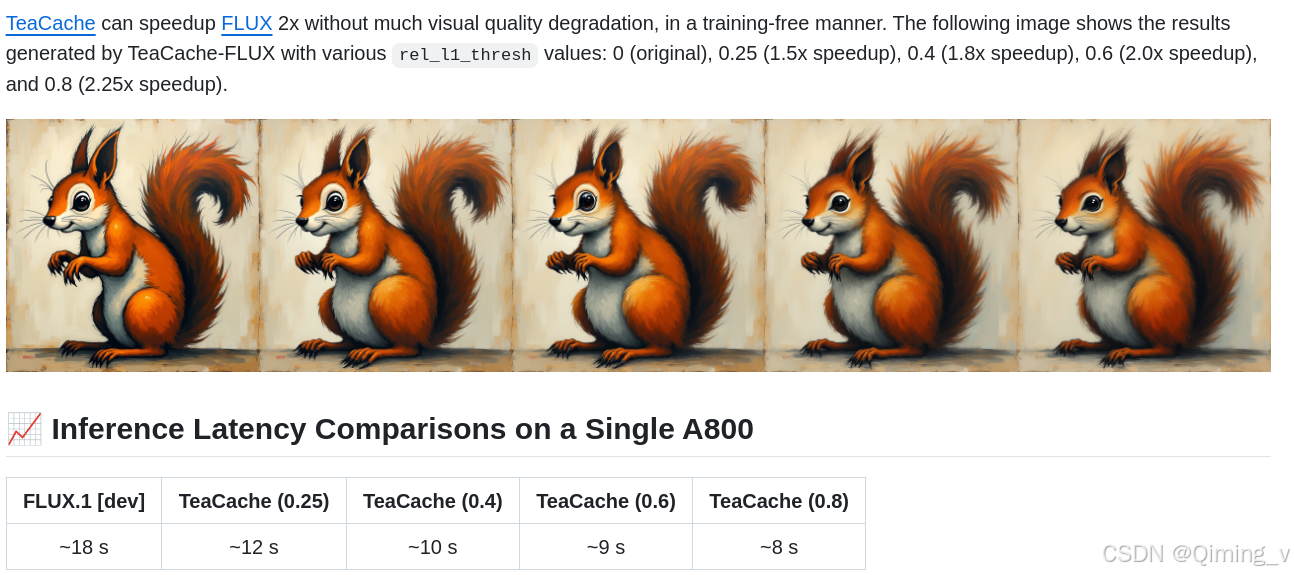
对于Flux.1 dev模型,阈值0.25加速1.5倍,阈值0.4加速1.8倍,0.6加速2倍,0.8加速2.25倍。
阈值越大,中间省略的步骤越多。

















 89
89

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









