







 论文提出了一种新的情感特征抽取结构Emoformer,用于从文本、音频和视觉模态中抽取情感向量。这些向量与句子向量结合形成情感胶囊,通过上下文分析模型进行情绪识别。在IEMOCAP和MELD数据集上,EmoCaps模型在多模态和文本模态情绪识别中表现出优越性能。
论文提出了一种新的情感特征抽取结构Emoformer,用于从文本、音频和视觉模态中抽取情感向量。这些向量与句子向量结合形成情感胶囊,通过上下文分析模型进行情绪识别。在IEMOCAP和MELD数据集上,EmoCaps模型在多模态和文本模态情绪识别中表现出优越性能。
EmoCaps:Emotion Capsule based Model for Conversationl Emotion Recognition(组会第三次分享论文)
基于情感胶囊的会话情绪识别模型:
发表刊物、作者和单位
Zaijing Li1, Fengxiao Tang1*, Ming Zhao1*, Yusen Zhu2
中南大学计算机科学与工程学院、湖南大学数学学院
findings of ACL 2022, pages 1610-1618
文章方法
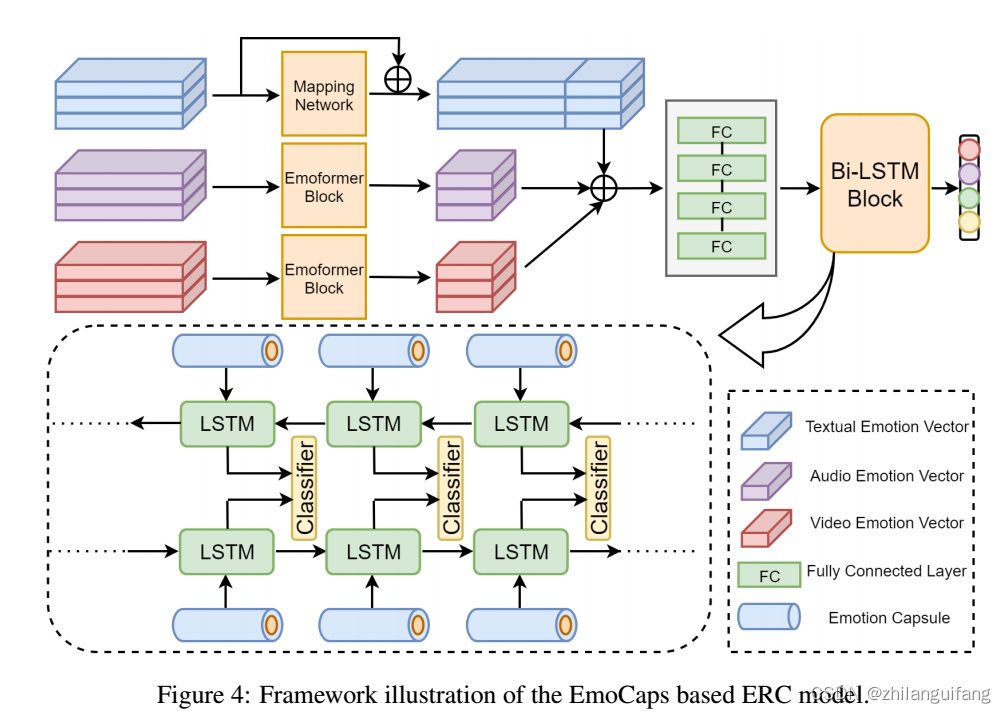
提出一个新的结构:Emoformer, 从不同模态提取情感多模态情感向量并与句子向量融合形成情感胶囊(情绪倾向抽取?)。设计了一个端到端ERC模型:EmoCaps,通过Emofromer结构抽取情感向量和从上下文分析模型中获取情感分类结果。
ERC领域现存方法讨论
现存方法集中于上下文信息建模,将transformer结构引入到话语特征抽取中去更好地抽取话语的语法与语义信息。
本文贡献
独创性的将情感向量的概念引入多模态情绪识别并提出一个新的情感特征抽取结构:Emoformer, 它用于联合抽取三个模态的情绪向量,并将他们与句子向量融合到情绪胶囊中;
基于Emoformer, 进一步提出一个叫做EmoCaps的端到端情绪识别模型来从多模态会话中识别情绪;
本模型和现存的最先进的模型在MELD和IEMOCAP数据集上进行了测试,结果表明我们的方法无论是在多模态还是文本模态上都具有最好的效果。
methodology
1 问题定义
给定对话: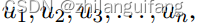
n是话语的数量,会话情绪识别的目标是输入一段对话识别出情绪标签集中对应对话中每个句子的正确情绪分类,情绪标签已经预先设定:
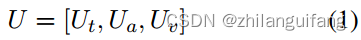
Ut:文本特征
Ua:音频特征
Uv:视觉特征
文本特征抽取:
用预训练语言模型BERT抽取文本特征向量。
步骤:
将对话分成单独的话语;
用transformer编码器编码话语得到512维句子向量;
音频特征抽取:
使用OpenSMILE(并不知道这是啥)来抽取声学特征。具体的:我没看懂,使用IS13 ComParE配置文件,该文件为每个话语视频提取了6373个特征,然后使用全连接层将维度降低到512个维度。
视觉特征抽取:
使用3d-cnn抽取视频特征,特别是说话者的面部表达特征,使用全连接层将维度调整到512维。
3 我们的方法
我们假定对话中话语的情绪取决于三个因素:
话语本身的情感倾向;
不同模态的话语包含的情绪信息;
上下文信息;
Emoformer Block
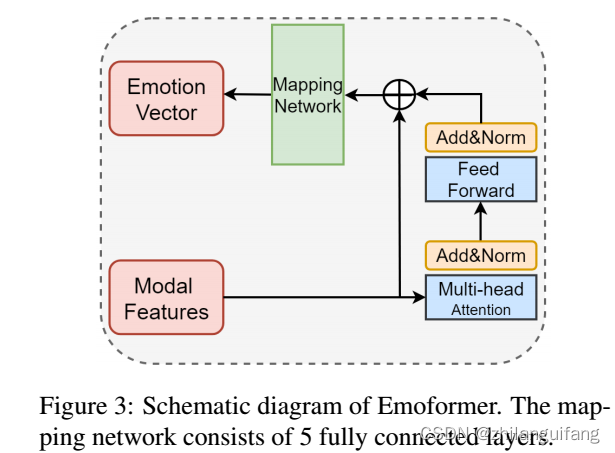
详细计算过程:
同transformer相同,给定输入特征U, 通过线性变换计算Q、K、V三个矩阵,
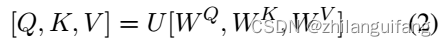
自注意力层公式表示:
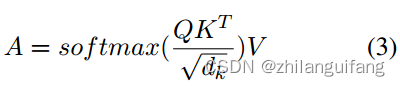
其中A是值V的权重,dk等于u的维数。
多个自注意力层连接得到多头注意力层:
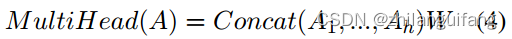
A1…,Ah是自注意层的输出,h是层数,
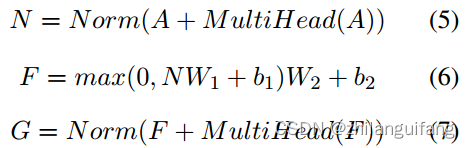
最后:
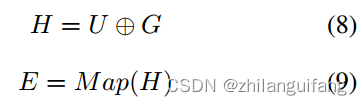
得到不同模态的情绪向量:
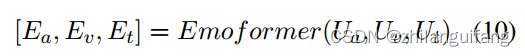
情绪胶囊:
认为文本特征包含话语语法和语义特征,情绪向量代表话语情感倾向,都是对话情绪识别的重要来源。文本特征表示了话语的意义、情感、特点等;视觉和音频特征起到补充作用。因此,将句子向量与三个模态的情绪向量连接起来成为情绪胶囊–情绪向量被句子向量包裹,之后又被上下文分析模型吸收来决定说话者的情绪。O为情绪胶囊

上下文建模
上下文信息被分为当前话语之前的信息和之后的信息。
利用一个双向LSTM模型作为上下文分析模型来抽取上下文信息。
最后连接一个全连接层,得到每个话语对应每个标签的值。
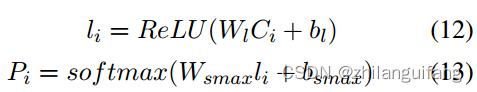
选择值最大的作为情绪标签。
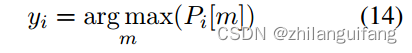
实验
1 数据集
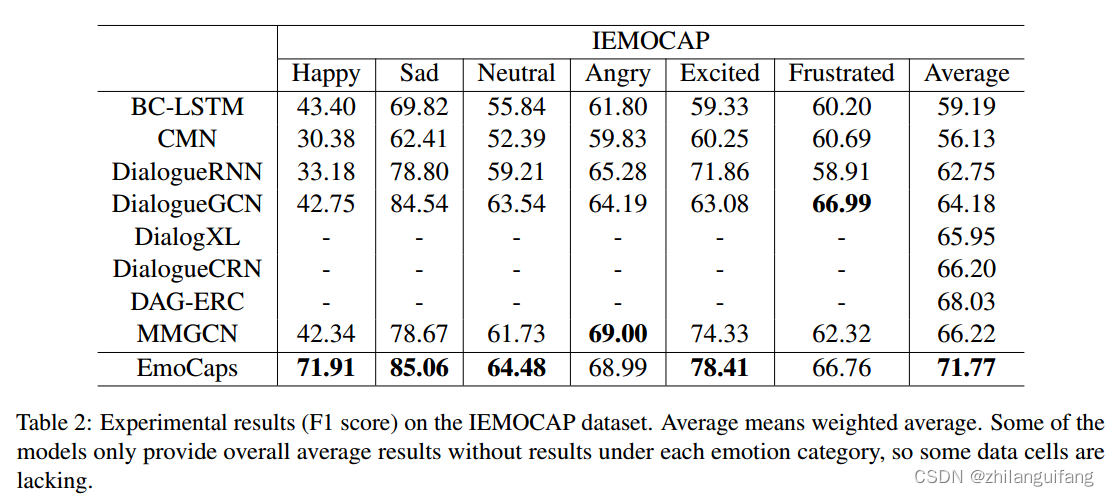
数据集:IEMOCAP:包含10位演员的即兴表演或者脚本表演的视频数据,也包含音频和文本转录数据,多位评论员设置了话语情绪标签,包含六类:happy、sad、neutral、angry、excited、frustrated。
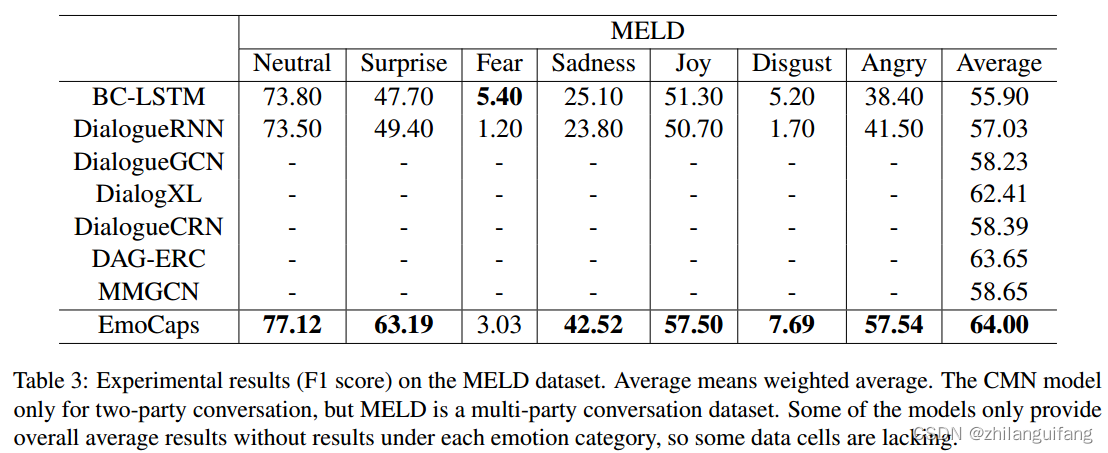
MELD:来自老友记的1433段对话,包含视频、音频和文本形式的数据,多位评论员将单词的情感标签分为七类:包括中性、惊讶、恐惧、悲伤、喜悦、厌恶和愤怒。
2 对比模型
BC-LSTM
CMN
DialogueRNN
DialogueGCN
DialogXL
DialogueCRN
DAG-ERC
MMGCN
结论和分析
1 对比实验
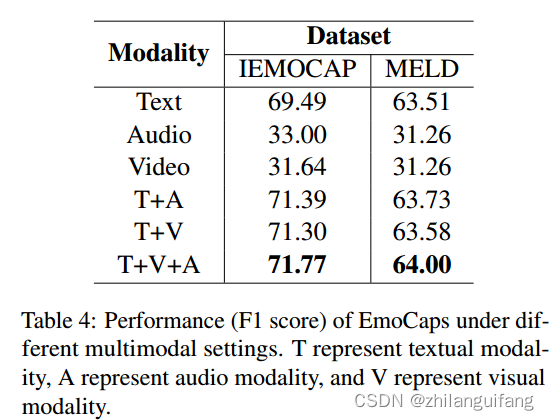
2 不同模态数据的对比
文本模态在对话情绪识别中占据主要作用。单独根据音频或者视觉特征进行情绪识别都是不理想的。但能够改善识别的效果。
3 说话者建模的影响
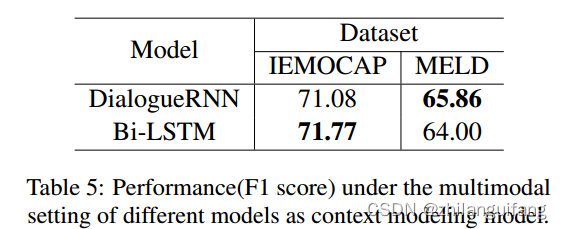
分析说话者建模对于对话情绪识别的影响,使用DialogueRNN的变体作为上下文建模模型来测试其表现。
DialogueRNN在MELD上表现更好:因为该数据集多数数据属于多人对话情景,所以说话者建模模型更有效。
在IEMOCAP数据集上说话者建模模型不再有效,这是双人对话数据集。
同时对说话者建模将消耗更多计算资源和时间。
4 案例研究
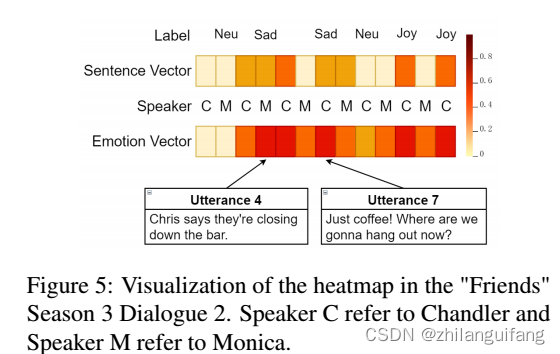
刚开始,双方都是中性情感,第4句的时候说话者的情绪变成吃惊和难过,句子向量不是很理解情绪转换的原因,但是情绪向量包含负面情绪的倾向,使得获得正确的情绪标签更加容易。
在第7句,真实标签为sad,句子向量为中性情感,情绪向量偏向sad这个正确标签,证明了情绪向量在ERC中的有效性。
结论
这篇论文基于transformer 结构提出了一个新的多模态特征抽取结构Emoformer, 进一步,设计了一个新的会话情绪识别模型EmoCaps。
首先利用Emoformer抽取文本、音频和视觉特征的情绪向量;
然后将这三个模态的情绪向量与句子向量融合成情绪胶囊;
最后利用一个上下文分析模型来得到最终的情绪识别结果。
在两个数据集上做了大量的实验,证明了我们的模型比现存的最先进模型表现更好,也证明了我们的假设的合理性。

















 7941
7941

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









