






以往的研究主要集中在通过增加检索文档的数量或长度来扩展检索增强生成(RAG)中检索到的知识。然而,仅增加知识量而不提供进一步的指导存在一定的局限性。
为此,Google DeepMind研究了RAG在**推理计算扩展(Inference Scaling)情况下的性能,特别是当上下文很长时。通过应用最优配置,在长上下文LLMs上扩展推理计算可以实现高达58.9%**的性能提升。

用于RAG的推理扩展策略
为了衡量推理计算,定义了有效上下文长度,即在LLM生成最终答案之前所有迭代中的输入token总数。对于大多数只调用LLM一次的方法,有效上下文长度等同于提示中的输入token数量,并受到LLM的上下文窗口限制。对于迭代调用LLM的方法,有效上下文长度可以通过策略无限扩展。
目标是理解RAG性能如何随着推理计算的扩展而变化。为此,引入了两种扩展策略:示范基础RAG(DRAG)和迭代示范基础RAG(IterDRAG)。
DRAG与IterDRAG的对比。IterDRAG将输入查询分解为子查询并回答它们,以提高最终答案的准确性。在测试时,IterDRAG通过多个推理步骤来扩展计算,分解复杂查询并检索文档。
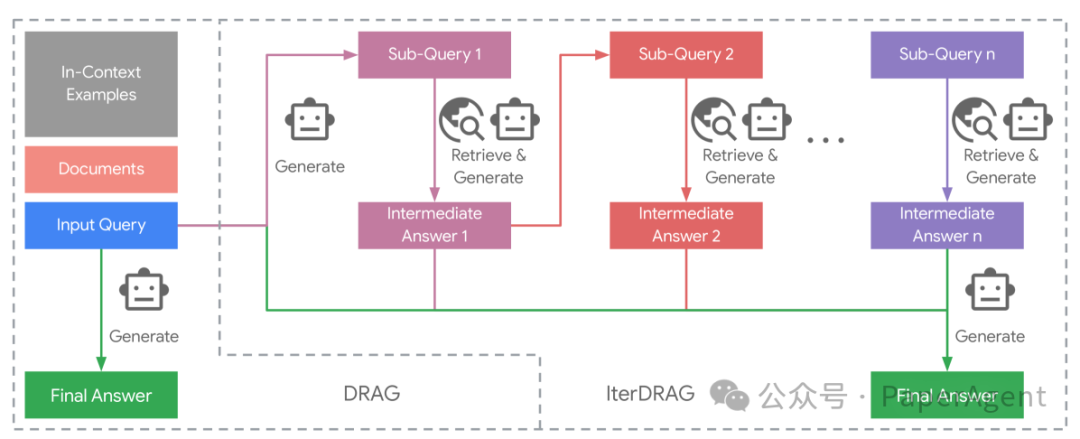
- 示范基础RAG(DRAG):DRAG利用上下文学习,通过直接从扩展的输入上下文中生成答案来利用LLMs的长上下文能力。DRAG在输入提示中整合了文档和上下文示例,使得模型能够在单次推理请求中生成对输入查询的答案。
- 迭代示范基础RAG(IterDRAG):为了处理复杂的多跳查询,IterDRAG通过将查询分解为更简单的子查询来处理。对于每个子查询,执行检索以收集额外的上下文信息,然后用于生成中间答案。在所有子查询解决后,检索到的上下文、子查询及其答案被组合以合成最终答案。
RAG性能和推理计算扩摸
接下来重点研究揭示RAG性能与推理计算规模之间的关系,并尝试预测在不同计算约束下达到最佳性能的推理参数配置。
固定预算下的最佳性能:
对于固定的有效上下文长度预算,通过枚举不同的推理参数配置(如检索文档的数量、上下文示例的数量、生成迭代的次数)来找到最优平均指标。
最优配置的具体示例:
- 在某个特定的最大有效上下文长度限制下,选择一个特定的文档数量,比如100篇文档。 Lmax
- 确定在输入提示中使用多少个上下文示例,例如20个示例。
- 对于IterDRAG,可能决定在最终生成答案之前进行最多5次的迭代。
RAG性能随文档数量和上下文示例的变化而变化**。**(a)报告了跨数据集的平均指标值,而在(b)和(c)中,每条线代表在逐渐增加文档/示例的一致配置下的标准化性能。
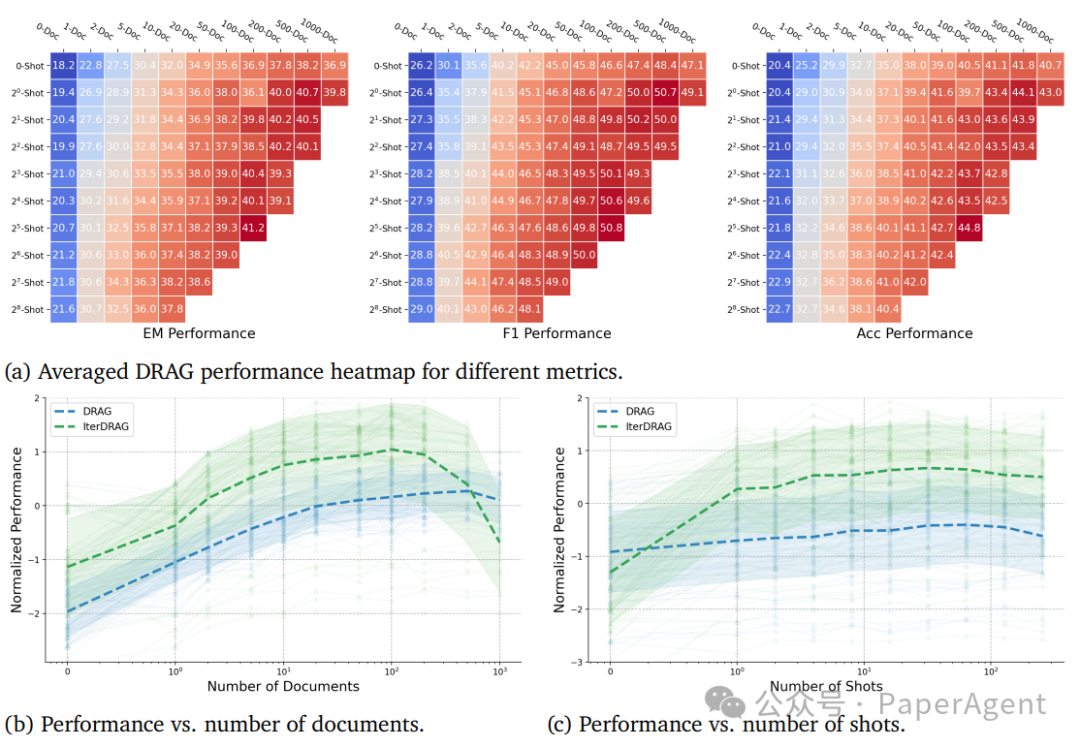
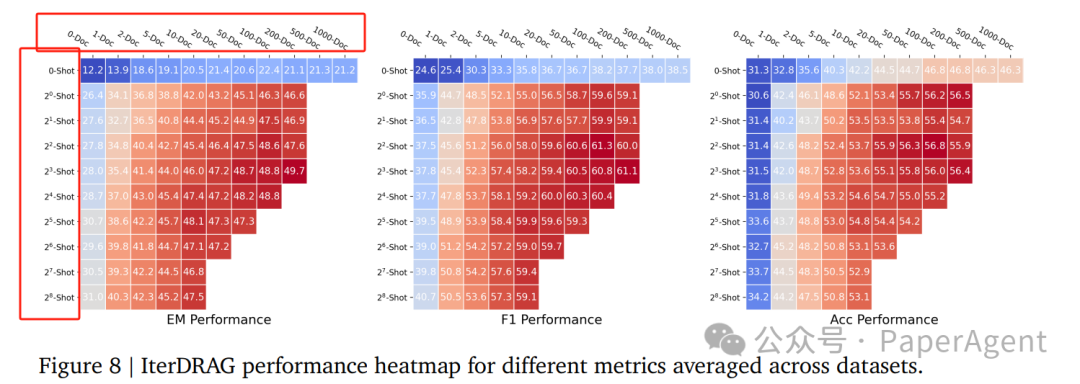
整体性能:
通过扩展最大有效上下文长度,DRAG和IterDRAG的性能一致地提升,表明增加计算预算对RAG性能是有益的。
特别地,IterDRAG在更长的有效上下文长度下(例如超过128k tokens)展现了比DRAG更有效的扩展。
不同方法在不同最大有效上下文长度 LmaxLmax(即所有迭代中的输入token总数)下的最佳性能。ZS QA和MS QA分别指one shot QA和many shot QA。对于不随 LmaxLmax 增加而进一步扩展的方法。将每个 LmaxLmax 的最佳结果加粗显示。
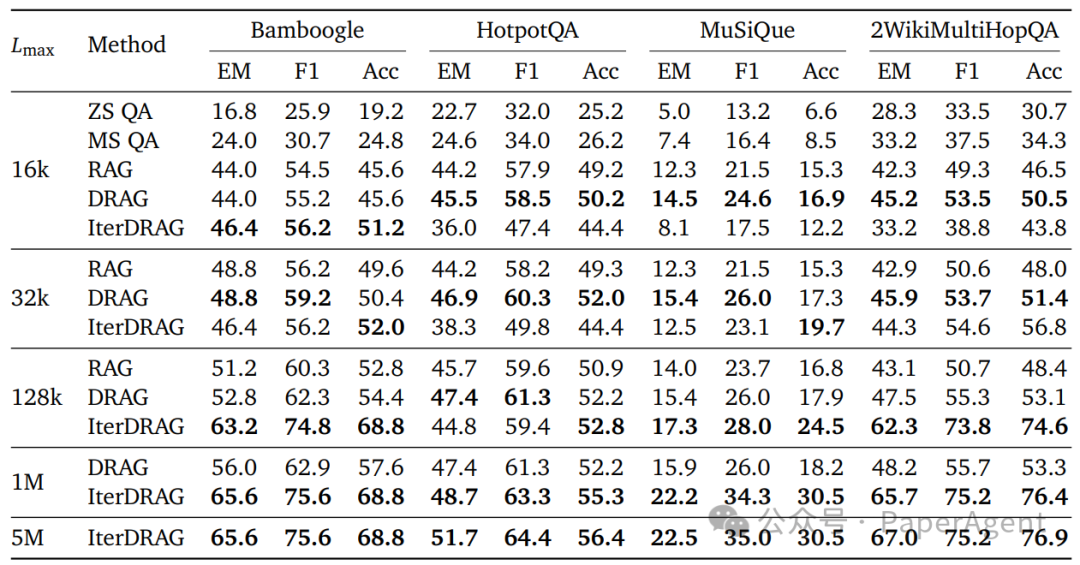
RAG的推理扩展法则:
通过分析不同有效上下文长度下的性能变化,提出了RAG性能随着推理计算规模的增加而近乎线性提升的观察结果,这被称为RAG的推理扩展法则。
- 线性关系: RAG性能随着推理计算规模的增加而近乎线性提升,这种关系被称为RAG的推理扩展法则。
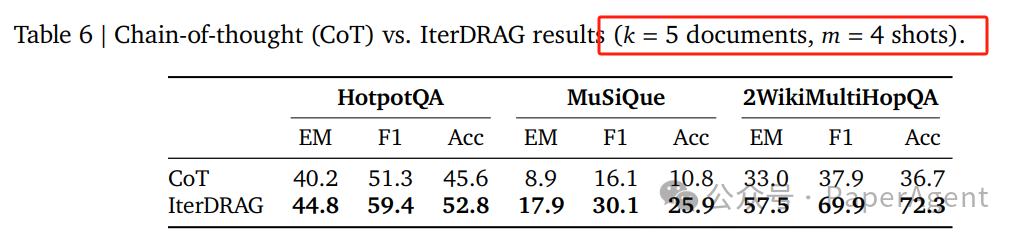
- IterDRAG的扩展性: 对于超过10^5个token的上下文长度,IterDRAG通过交替检索和迭代生成继续有效扩展。
- 性能增益递减: 当有效上下文长度超过1M个token时,最优性能的增益逐渐减少,这可能归因于长上下文建模的局限性。
跨数据集的标准化性能与有效上下文长度的对比。每条线代表一个固定的配置,通过改变文档数量来进行缩放。红点表示最优配置,虚线显示拟合结果。观察到的最优性能可以通过与有效上下文长度的线性关系来近似。
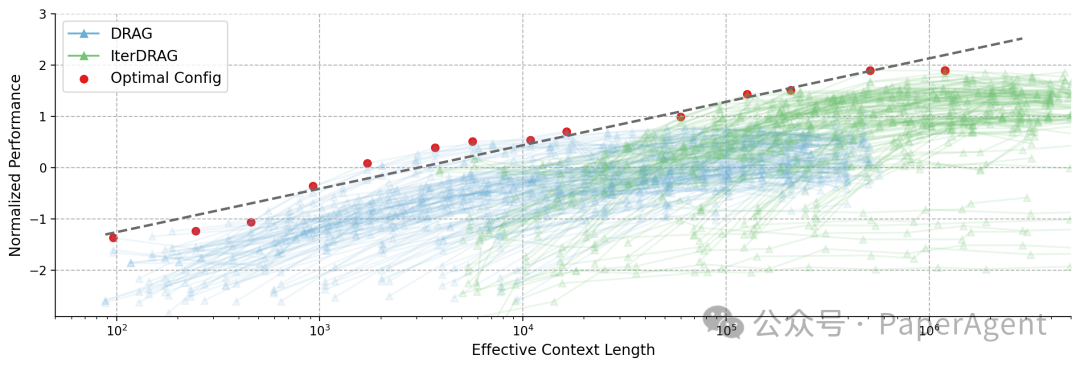
MuSiQue上标准化性能与有效上下文长度的对比。每条线代表一个固定的配置,通过调****整文档数量来进行缩放。红点和虚线代表最优配置及其拟合结果。标准RAG在104104个token时早早达到平稳状态,相比之下,DRAG和IterDRAG随着有效上下文长度的增长显示出近乎线性的提升。
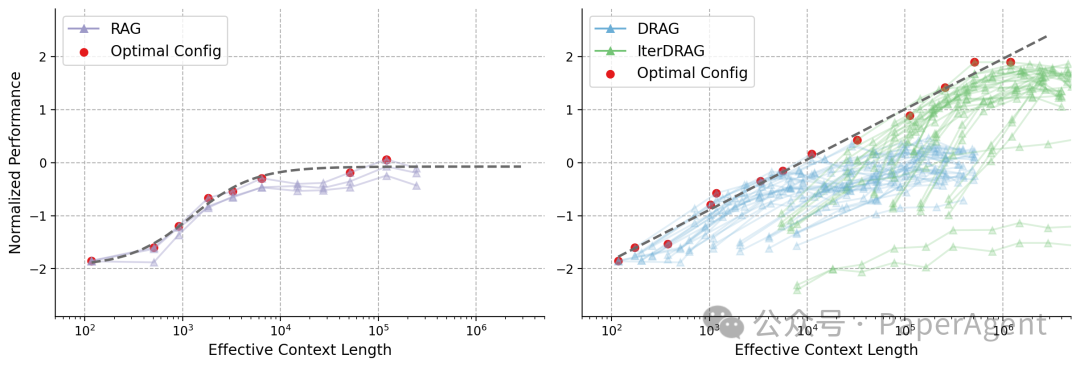
**使用不同方法评估Gemini 1.5 Flash的准确率:**零-shot QA、多-shot QA、RAG(带有最佳数量的文档)、DRAG和IterDRAG在基准QA数据集上的表现。通过扩展推理计算(最多5M个token),DRAG持续优于基线,而IterDRAG通过交错检索和迭代生成改进了DRAG。

如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
我已将重要的AI大模型资料包括市面上 AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享 出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。















 10万+
10万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









