









目录
简介
在图像处理中,经常会用到3DLUT来做颜色增强或者色域映射,3DLUT插值部分基本都是硬件处理,但难点在于如何生成对应的3DLUT表。目前,工程上基本上都是静态表,就是固定几张3DLUT,然后根据某些变量来选表,选邻近表进行插值,得到需要的3DLUT,然后配置到硬件,比如ISP通路里,一般是根据色温或者光源类型,照度等信息,配置不同的3DLUT,然后插值得到需要3DLUT。显示通路里,一般就是配置某些色域转换的3DLUT,当输入不同色域图片时,都转到屏幕对应的色域,这个过程基本上选固定表即可,一般不用插值,除非两种情况过渡时。
3DLUT相关介绍这里就不展开讲,可以参考 三维查找表3DLUT_图像算法菜鸟的博客-CSDN博客_3dlut三维查找表简称3DLUT,是一个对应数值的列表,可以通过它查询任何输入值及其所对应的输出值,是色彩转换技术中常用的一种技术。其核心思想是,将源色彩空间进行分割,划分为一个个规则的立方体,每个立方体的八个顶点的数据是己知的,将所有源空间的已知点构成一张三维查找表。一般就是把RGB三个通道分别等分为N个顶点,组成NxNxN个节点,在使用时,其他节点就直接插值得到,常用的有9x9x9,17x17x17,33x33x33,65x65x65等。在ISP算法和显示算法里,一般都是用17x17x17。...https://blog.csdn.net/zhognsc08/article/details/122788033?spm=1001.2014.3001.5502 而近几年,随着AI技术的应用,出现了不少基于AI的3DLUT生成算法,基本上都是图像自适应的,而不是静态的了,下面就分享几篇3DLUT相关的论文,主要是用来做图像增强,包括颜色和亮度。
AI3DLUT
论文名称:Learning Image-adaptive 3D Lookup Tables for High Performance Photo Enhancement in Real-time
论文地址:https://arxiv.org/pdf/2009.14468v1.pdf
代码地址:https://github.com/HuiZeng/Image-Adaptive-3DLUT
这篇论文是2020年发表在IEEE上,算是比较早的用AI来做3DLUT的。
论文的思想是,学出N个Basis 3DLUTs, 网络每次只要输出对应的N个权重,对N个3DLUTs进行加权求和,得到一个3DLUT,这样就可以做到图像自适应,最后进行3DLUT插值,得到输出图像,即按(5)式计算,而不是按(4)式那样通过3DLUTs插值之后的图像进行加权,那样计算量较大。 由于网络前向时,只需要输出N个权重,网络可以做得很轻量,参数量不多600K,3DLUT插值也很快,对4K图,只需要2ms。 论文还支持paired数据和unpaired数据,unpaired数据时,使用了GAN loss,也不算创新,估计效果也一般,主要还是paired数据的情况。
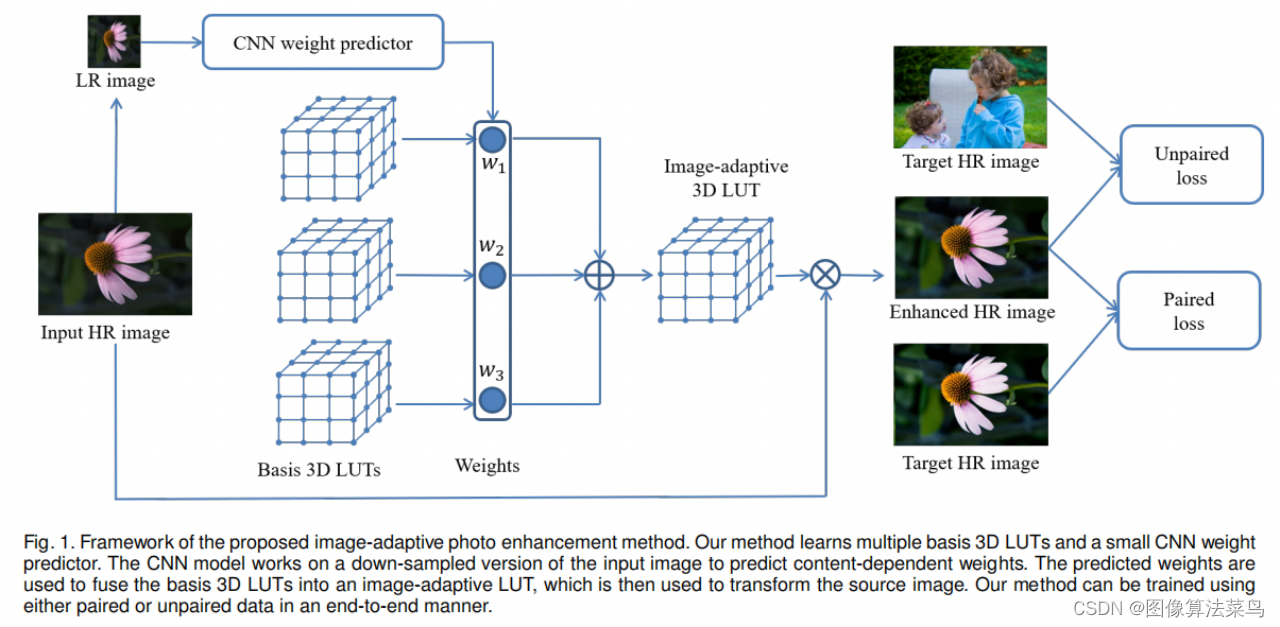
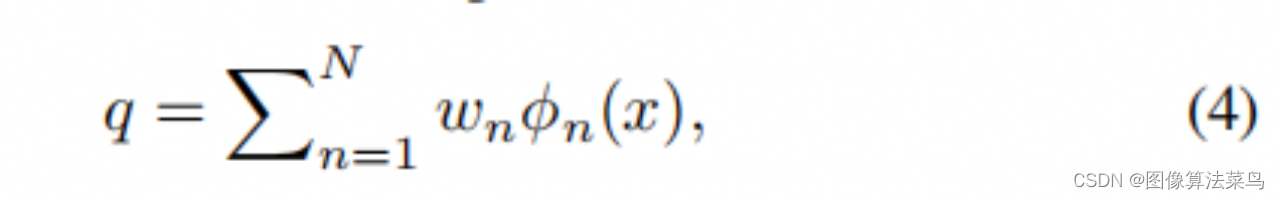
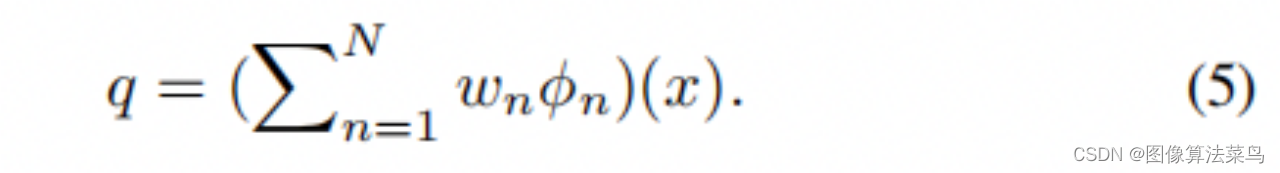
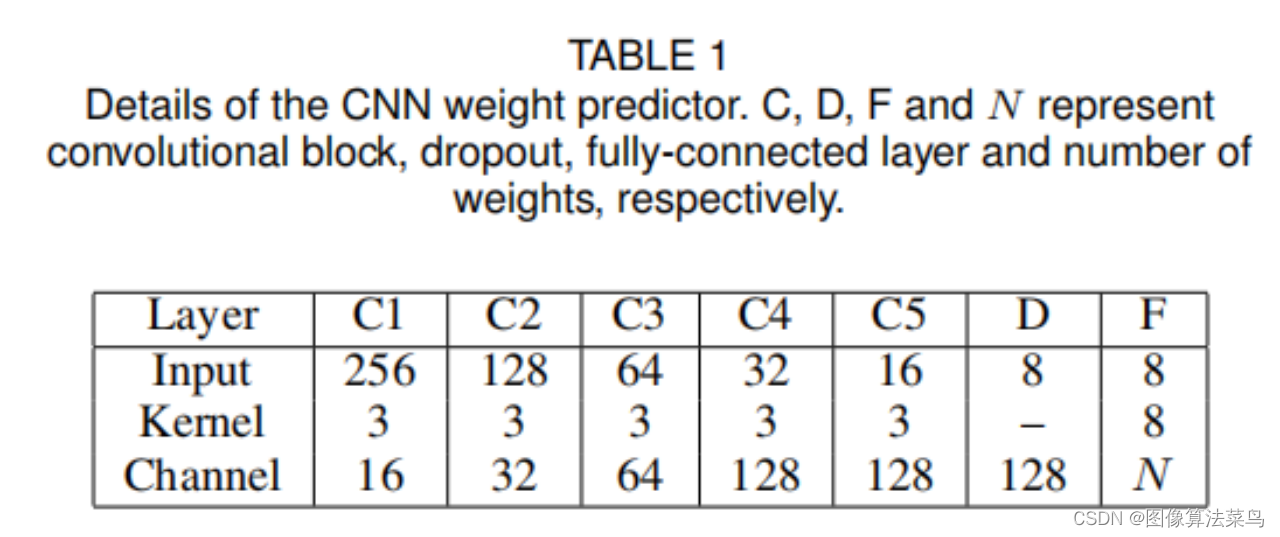
网络很轻量,结构如下图所示。
文章的loss如下,除了使用L2作为准确性loss,还加入了正则项loss,其中
(11)式是平滑性loss,主要保证3DLUT邻近节点之间是平滑的,不存在突兀的情况。
(12)式主要是为了限制权重不能太大
(13)式是为了保证LUT的单调性
其中(12)式要重点注意下,网络输出的是一组权重,对basis 3DLUT进行加权,但论文也没说这些权重和为1,实际上就是不为1,如果强制限制权重和为1,则可能出现两种情况,一种就是选择了某一张表,即其他权重为0,一个权重为1,另一种情况就是所有权重接近平均,取了所有3DLUT的平均。(12)式(代码里实际是可以单独控制权重和loss的权重,(11)式的loss单独控制,而不是包含在(12)式)的权重加大,则会出现第二种情况,权重较小就会出现第一种情况。
由于权重和不为1,其实学出来的basis 3DLUTs也不标准,这里的判断3DLUT是否标准的原则是,把3DLUT作用到图像上,看图像是否正常,一般手调的3DLUT是标准的。学出来的N个3DLUT中,可能就1个接近标准,而其他都是不标准的,标准的那个权重一般会比较大,而不标准的,权重会小一些,这些不标准的就相当于delta 3DLUT,是用来微调的。
当然,上述结论是在我自己的数据集上训练出来的,不是用的论文里说的数据,但好像也说的过去。
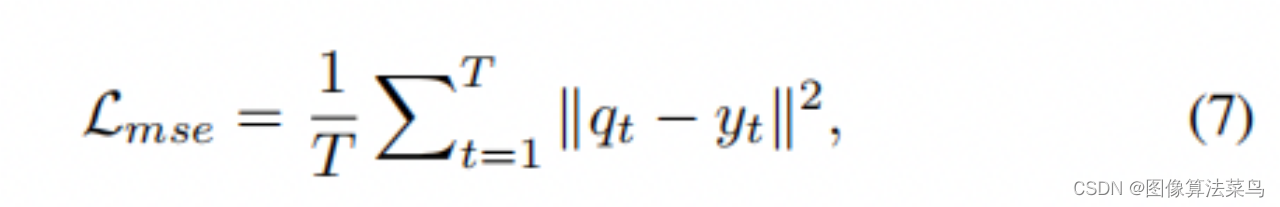
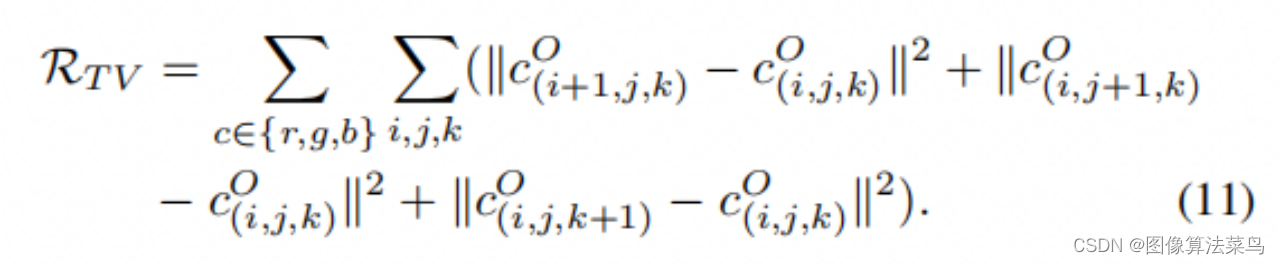
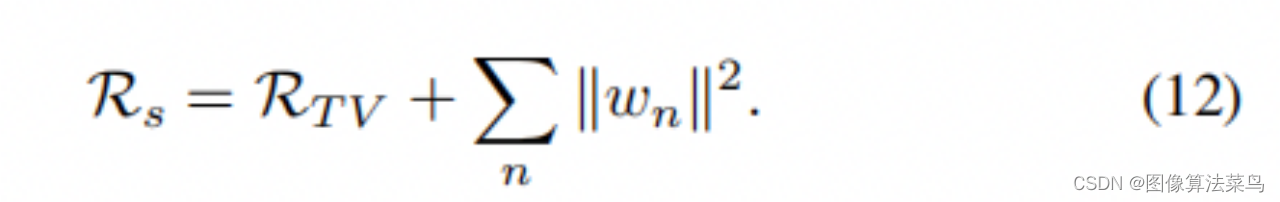
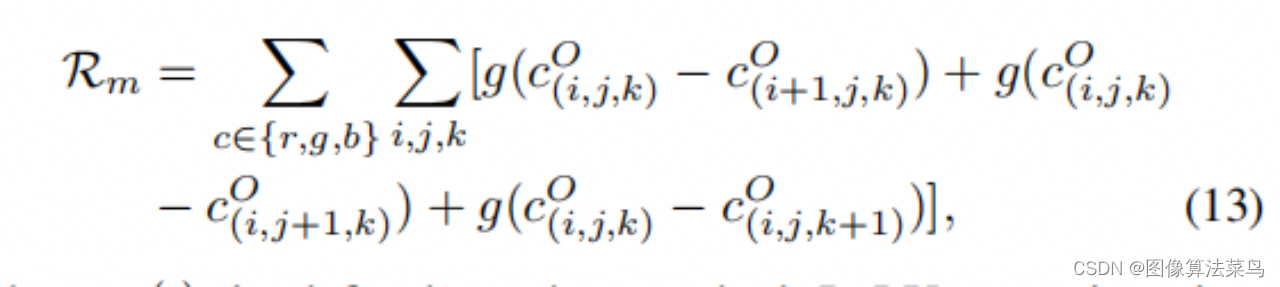
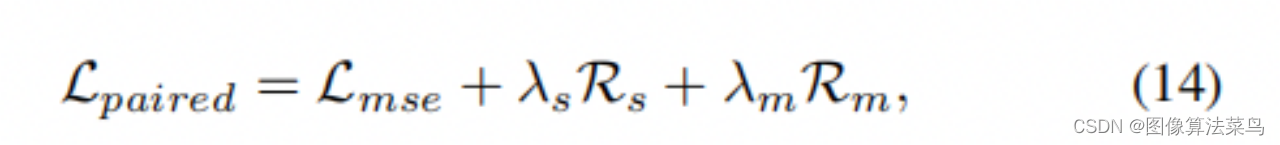
作者提供了3DLUT插值部分的代码是C++ cuda代码,但3DLUT插值可以用系统自带的grid_sample函数实现,具体实现如下,其中align_corners=True是必须的。
class Apply3DLUT(nn.Module):
def __init__(self):
super(Apply3DLUT, self).__init__()
def forward(self, lutRGB, imgRGB):
N, C, H, W = imgRGB.size()
guide = imgRGB.permute(0, 2, 3, 1)
guide = guide.view(N, 1, H, W, C)
guide = guide[:, :, :, :, (2, 1, 0)] # RGB2BGR
guide = guide * 2 - 1
bins = lutRGB.size(2)
grid = lutRGB.view(-1, 3, bins, bins, bins)
out = F.grid_sample(grid, guide, padding_mode='border', align_corners=True)
out = out.squeeze(2)
return out正则项loss的实现作者也提供了,我认为写得不准确,很简单的判断方法就是,给定一个没有任何效果的3DLUT,这个肯定是满足平滑性和单调性的,那么对应的loss就应该为0,但作者提供的代码并不为0,我写得如下所示。
class Loss3DLUT(nn.Module):
def __init__(self, dim=17):
super(Loss3DLUT, self).__init__()
self.l2 = nn.MSELoss()
self.weight_r = torch.ones(1, 3, dim, dim, dim - 1, dtype=torch.float)
self.weight_r[:, :, :, :, (0, dim - 2)] *= 2.0
self.weight_g = torch.ones(1, 3, dim, dim - 1, dim, dtype=torch.float)
self.weight_g[:, :, :, (0, dim - 2), :] *= 2.0
self.weight_b = torch.ones(1, 3, dim - 1, dim, dim, dtype=torch.float)
self.weight_b[:, :, (0, dim - 2), :, :] *= 2.0
self.relu = torch.nn.ReLU()
self.nodeLen = 1 / (dim - 1)
self.dim = dim
def forward(self, lut):
# LUT 1 3(rgb) dimR dimG dimB
dif_b = lut[:, :, :, :, :-1] - lut[:, :, :, :, 1:]
dif_g = lut[:, :, :, :-1, :] - lut[:, :, :, 1:, :]
dif_r = lut[:, :, :-1, :, :] - lut[:, :, 1:, :, :]
dif_b[:, 2, :, :, :] += self.nodeLen
dif_g[:, 1, :, :, :] += self.nodeLen
dif_r[:, 0, :, :, :] += self.nodeLen
dif_b_mn = lut[:, 2, :, :, :-1] - lut[:, 2, :, :, 1:]
dif_g_mn = lut[:, 1, :, :-1, :] - lut[:, 1, :, 1:, :]
dif_r_mn = lut[:, 0, :-1, :, :] - lut[:, 0, 1:, :, :]
nn = lut.size(0)
weight_r = self.weight_r.repeat(nn, 1, 1, 1, 1)
weight_g = self.weight_g.repeat(nn, 1, 1, 1, 1)
weight_b = self.weight_b.repeat(nn, 1, 1, 1, 1)
weight_r = weight_r.to(lut)
weight_g = weight_g.to(lut)
weight_b = weight_b.to(lut)
tv = torch.mean(torch.mul((dif_r ** 2), weight_r)) + torch.mean(
torch.mul((dif_g ** 2), weight_g)) + torch.mean(torch.mul((dif_b ** 2), weight_b))
mn = torch.mean(self.relu(dif_r_mn)) + torch.mean(self.relu(dif_g_mn)) + torch.mean(self.relu(dif_b_mn))
return tv, mn3DLUT虽然做到了图像自适应,但是全局操作,不具有局部处理能力,工程上一般都是用来处理颜色,处理亮度用1DLUT更加合适。3DLUT的输入要求为0~1的范围,这样基本上只能放到后处理模块上,所以一般在ISP通路里,也是放到了亮度调节模块之后ToneMapping,这个之后的数据基本上是0~1了,而再往前,多帧融合的结果基本上都是超过1的。论文是学出来一组权重,但权重和并不为1,这个就和实际工程中使用的有点差异,可调性和可解释性没那么强。
在工程上,有时不希望3DLUT改变AWB的效果,因为如果改变了,二者就耦合了,调试时就分不清到底是谁不准确。3DLUT如果不动AWB,可以考虑再加入AWBloss,就是保证灰色点尽量还是灰色,大致代码如下。
awbloss = 0
for i in range(self.dim):
rdiff = self.l2(lut[:, 0, i, i, i], lut[:, 1, i, i, i])
bdiff = self.l2(lut[:, 2, i, i, i], lut[:, 1, i, i, i])
awbloss += (rdiff + bdiff)AdaInt
论文题目:AdaInt: Learning Adaptive Intervals for 3D Lookup Tables on Real-time Image Enhancement
论文地址:https://arxiv.org/pdf/2204.13983.pdf
代码地址:https://github.com/ImCharlesY/AdaInt
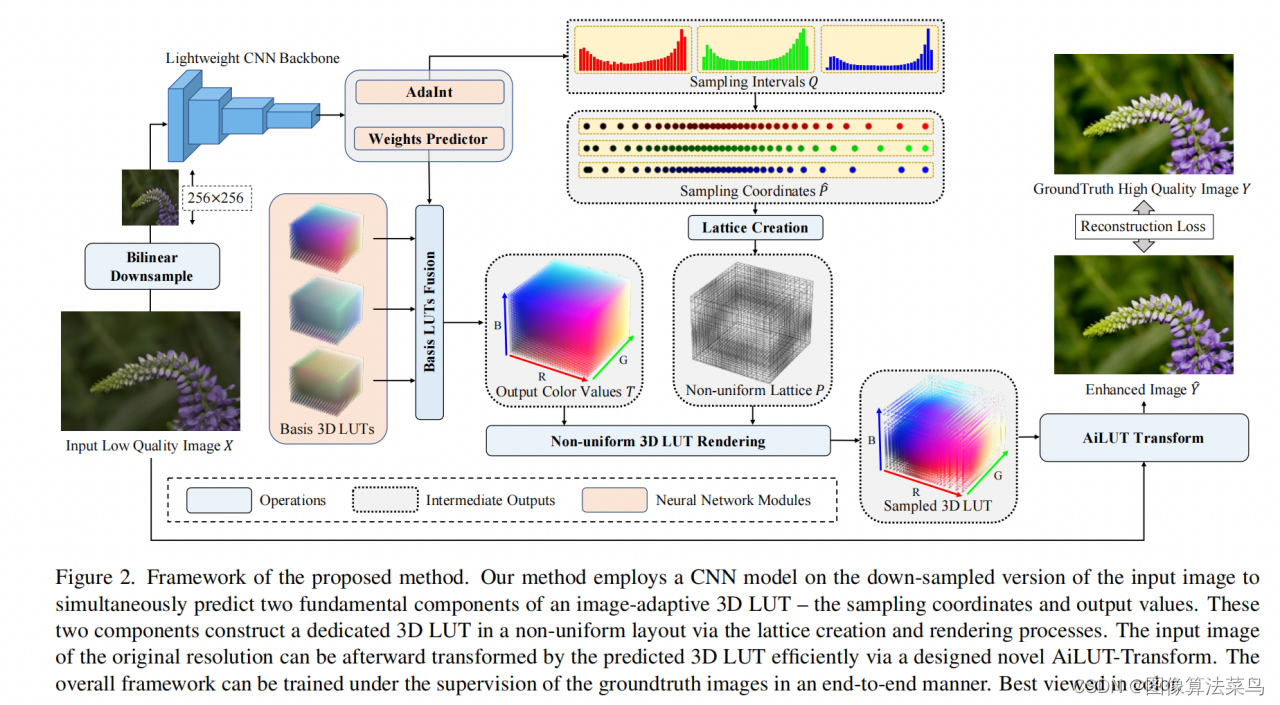
这是CVPR2022的一篇论文。
普通的3DLUT都是均匀间隔采样的,文章提出使用非均匀间隔采样的3DLUT,这样可以控制的更加精确,可以在感兴趣的区域划分的更细,控制的更加精准,比如人脸区域,在肤色范围,更多的节点来控制肤色,这样可以更加精准。
相比AI3DLUT,网络除了输出权重,还需要输出3个1DLUT,用来控制非均匀的间隔采样。 由于3DLUT插值部分是非均匀间隔采样,不能调用系统函数,需要自己写3DLUT插值的代码,作者提供了C++ cuda代码,可以实现非均匀间隔采样的3DLUT
文章中3DLUT使用的33个节点,1DLUT是32个节点,补了一个0。
loss上,和AI3DLUT的基本类似。
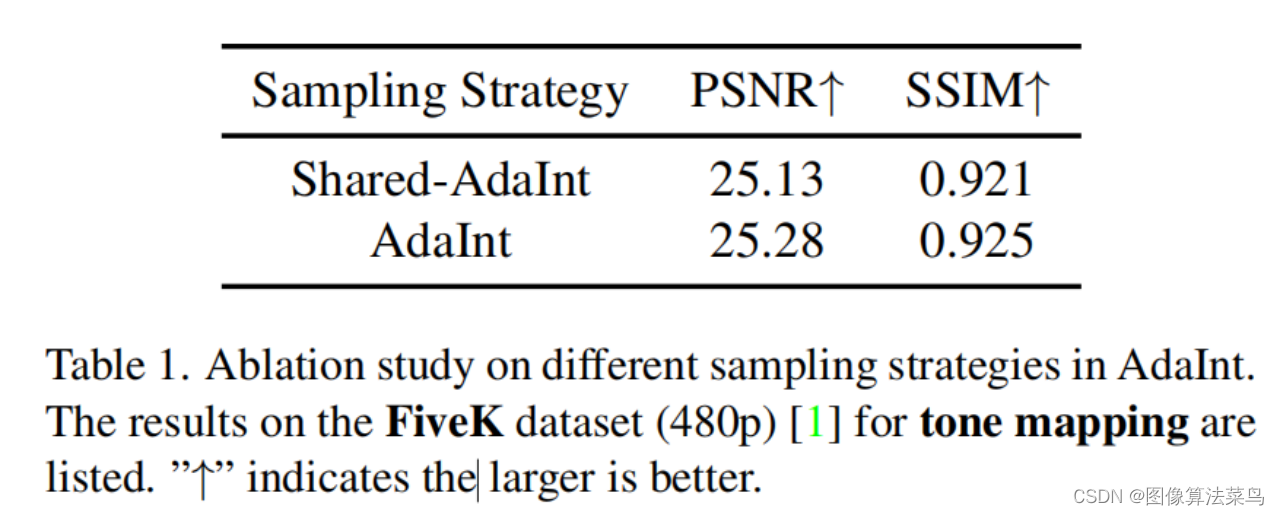
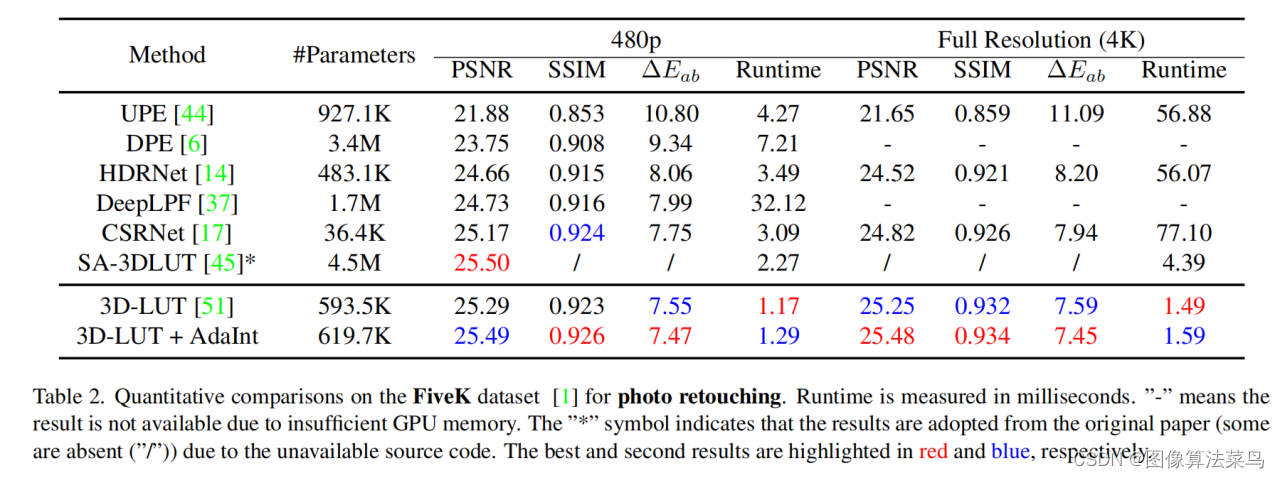
效果上,对比AI3DLUT,效果提升了大概0.2db左右。
RGB三个轴的采样也可以一样,不过文章分析了,三个一样的话,称之为shared-AdaInt,不相同的称为AdaInt。
非均匀间隔采样和先经过3个1DLUT,再经过均匀的3DLUT插值,对于节点上的点来说,是可以做到一样的,完全等价的,但对于插值的点,二者还是有差别的。不过,如果先过3个1DLUT,再做3DLUT,应该也能达到类似的效果。
由于是非均匀间隔采样,AdaInt可以适当处理超过0~1的输入图像,相当于把0~max的范围,映射到0~1的范围内,因为不是均匀采样,所以不是线性压缩,要比AI3DLUT有优势。
SeqLUT
论文题目:SepLUT: Separable Image-adaptive Lookup Tables for Real-time Image
Enhancement
论文地址:https://arxiv.org/pdf/2207.08351.pdf
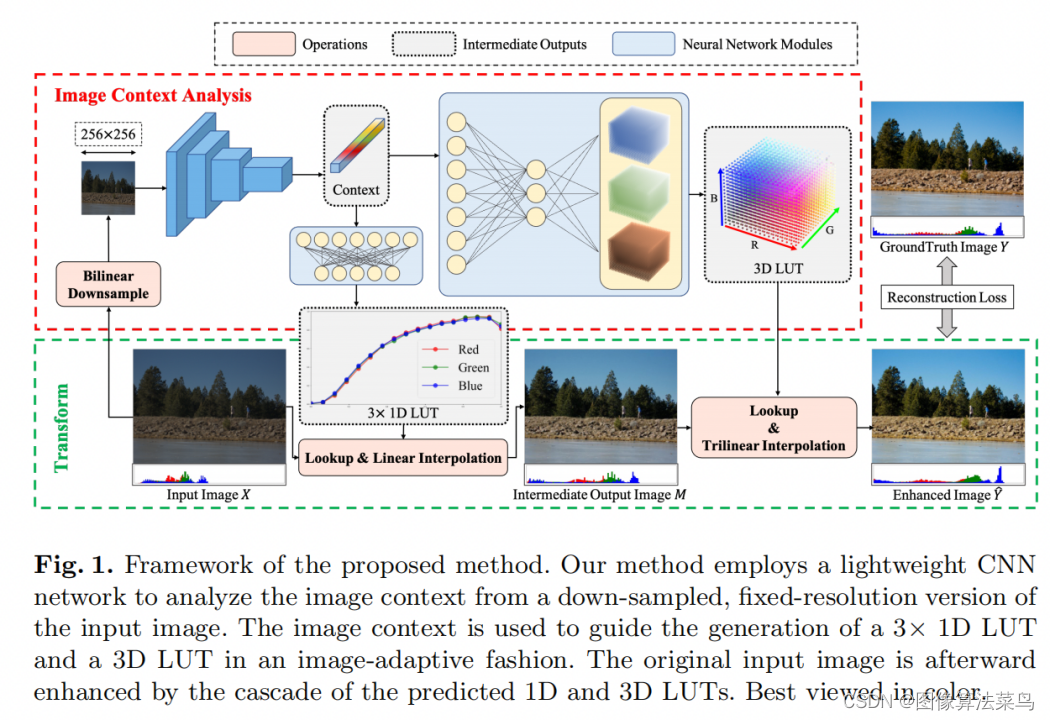
这是ECCV2022一篇论文。
SeqLUT使用3个1DLUT+1个3DLUT来做图像增强,图像先经过学出来的3个1DLUT,再经过一个均匀的3DLUT,相当于把AdaInt分两步来实现了。
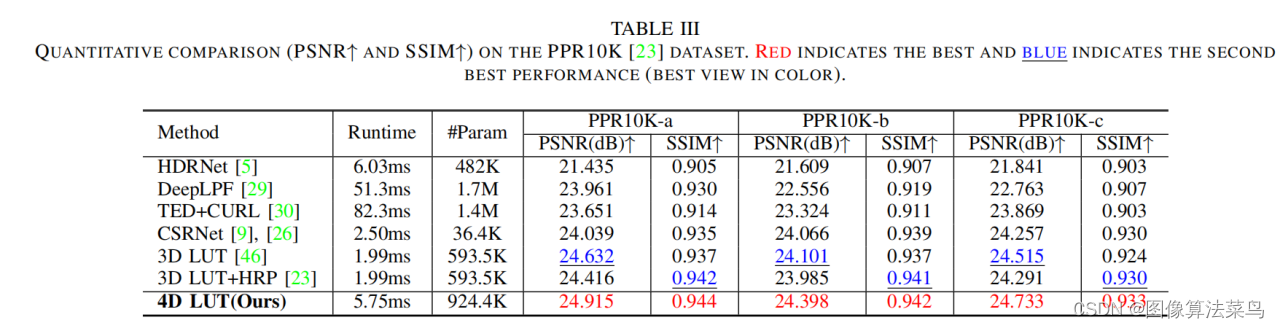
不同于AI3DLUT和AdaInt,SeqLUT是直接输出一个3DLUT,而不是学出一个权重。 backbone提取出图像特征,然后分两个分支,分别输出3个1DLUT和1个3DLUT,该过程是使用了全连接结构,参数量分别对应table 2和table 3,3DLUT分支,如果使用1层全连接结构,参数量为32m*3*St*St*St,参数量很大,作者为了做到参数量小一些,使用了2层结构,这样参数量变为K*(32m + 3*St*St*St),文章中取K取3或5,m=6或8,St取9或17,这样参数量只有50K(m=6, S0=St=9, ours-S)或者120K(m=8, S0=St=17, ours-S)左右,比AI3DLUT要少很多。



从客观指标上看,SeqLUT的效果比AI3DLUT要好,差不多也是高0.2db左右,和AdaInt效果差不多。
这里也证实了,虽然AdaInt和SeqLUT实现方式不一样,但都是3个1DLUT+1个3DLUT,达到的效果也是相当的,估计SeqLUT中,为了减少参数量,也牺牲了部分效果。
在工程上,比如ISP通路里,3个1DLUT就相当于gamma变换,只是一般情况下,调试上是不会取调整gamma,会使用标准的gamma,SeqLUT相当于把gamma和3DLUT部分联合起来,使用AI的方法做到了图像自适应,实用性比AdaInt高些。
论文里输出3DLUT是靠全连接实现的,这样参数量就会很大,作者想办法把参数量减下来了,也可以考虑不用全连接结构,可以把通道数变成St*St,即H*W*C,其中C=St*St,然后reshape成St*St*C’,其中C’=H*W,再经过卷积,把通道数降为3*St即可。
loss上没有使用正则项loss,加上正则项loss,效果应该更加稳定。
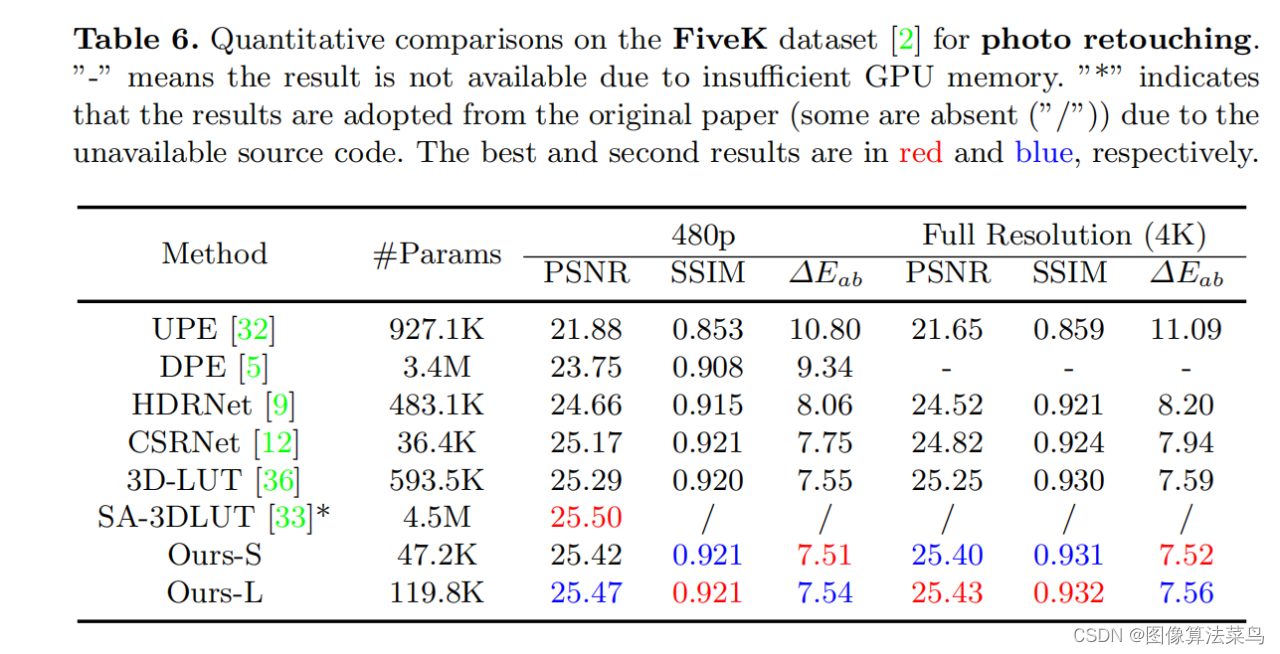
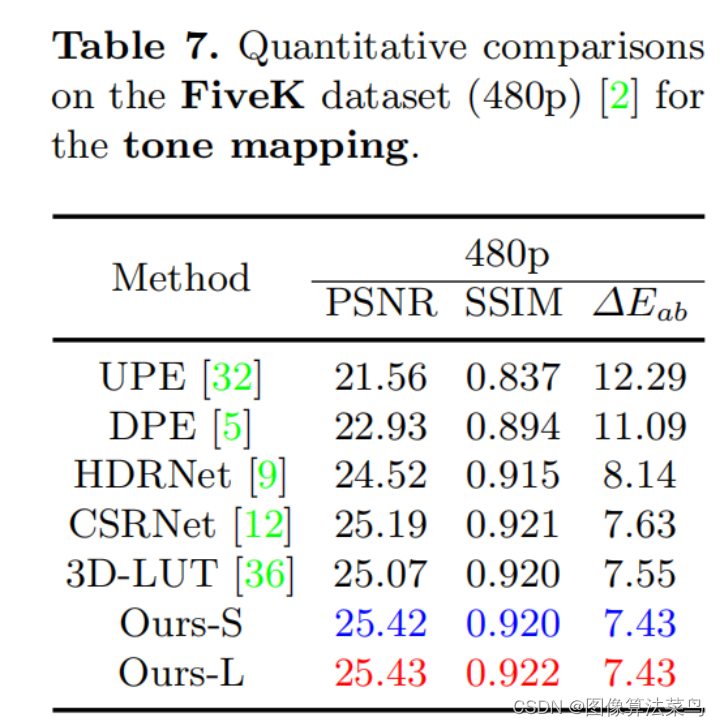
4D LUT
论文题目:4D LUT: Learnable Context-Aware 4D Lookup Table for Image Enhancement
论文地址:https://arxiv.org/pdf/2209.01749.pdf
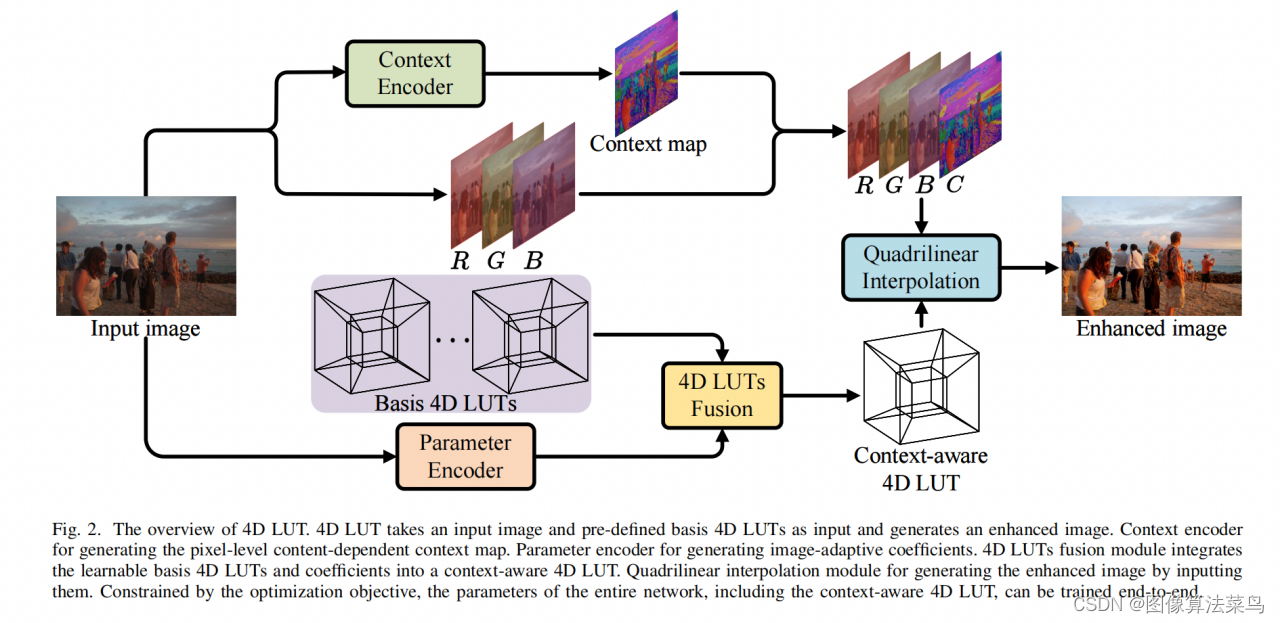
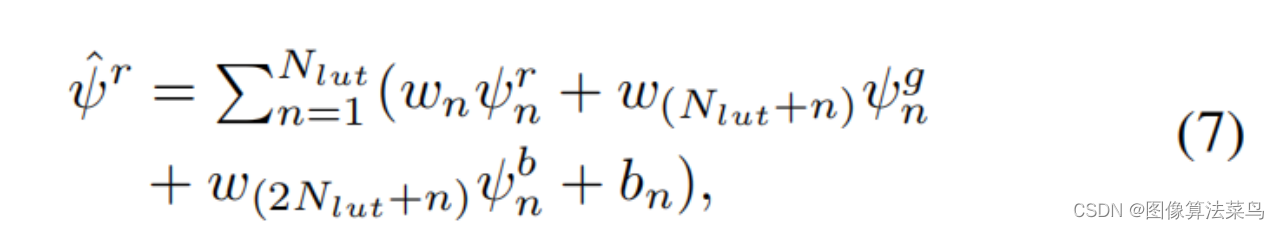
4DLUT不同于3DLUT,多加了一个context map通道,和RGB组合成4D,context map通道不完全等价于语言,并不需要监督,由网络自动学。同时,和AI3DLUT有点类似,有个Parameter Encoder分支,输出一组参数,训练时还会输出一组basis 4DLUTs,文章中取3个,即Nlut=3,但又不同于AI3DLUT,参数分为weight和bias,并不是只有weight,大小也不同,其中weight的大小为3N2lut,bias的大小为Nlut,然后按7式计算出4DLUT,再进行4DLUT插值,4DLUT的bin为33,4DLUT插值部分也是写c++ cuda代码实现。
Loss和AI3DLUT类似,也使用了平滑性loss,单调性loss,和权重限制loss,只是扩展到了4维 。
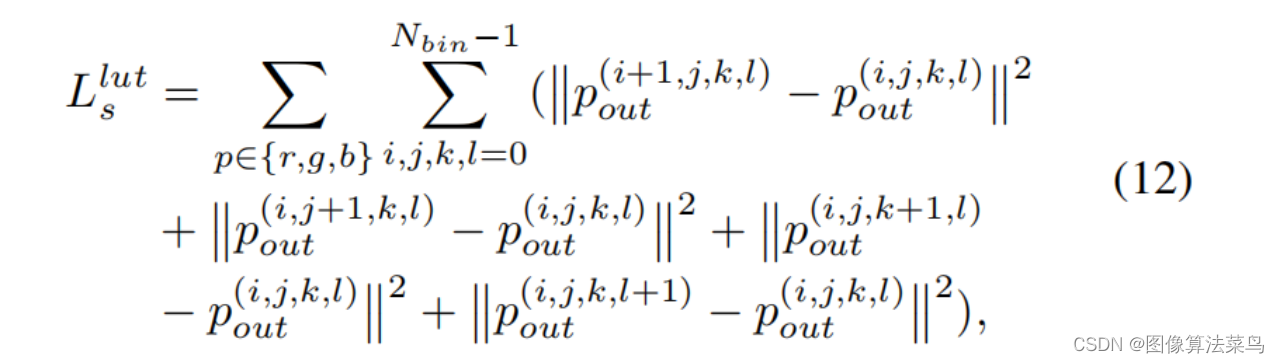
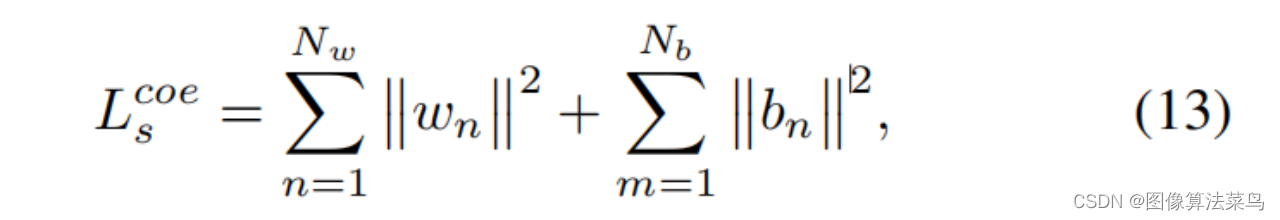
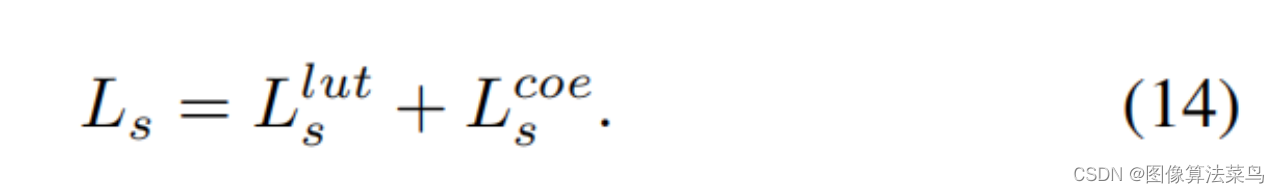
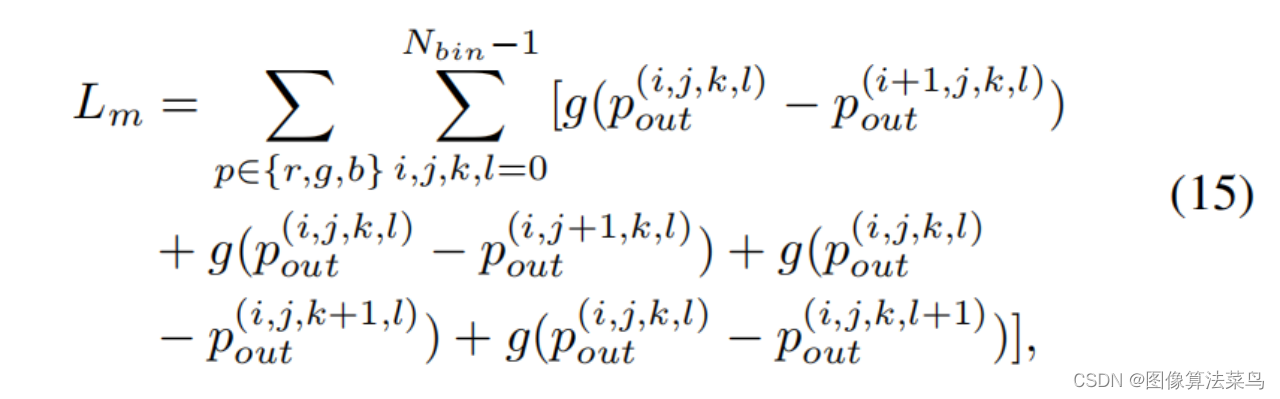
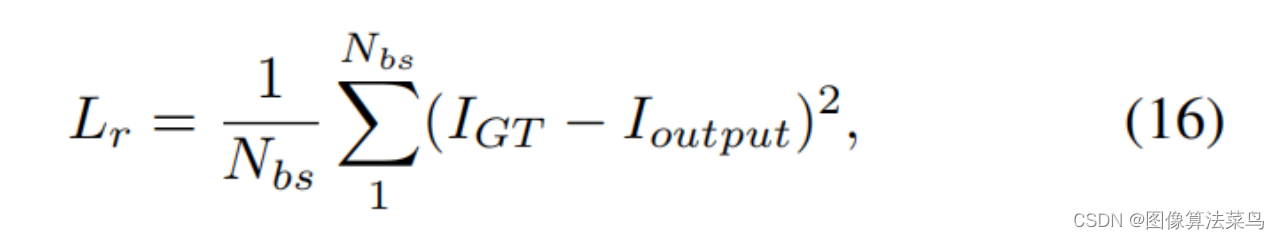
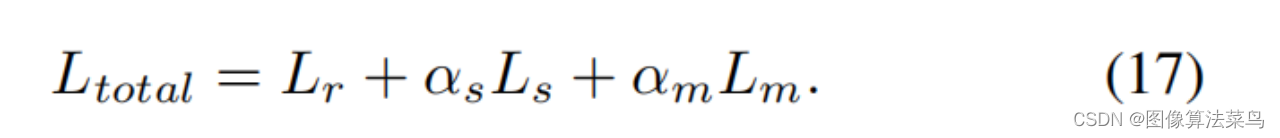
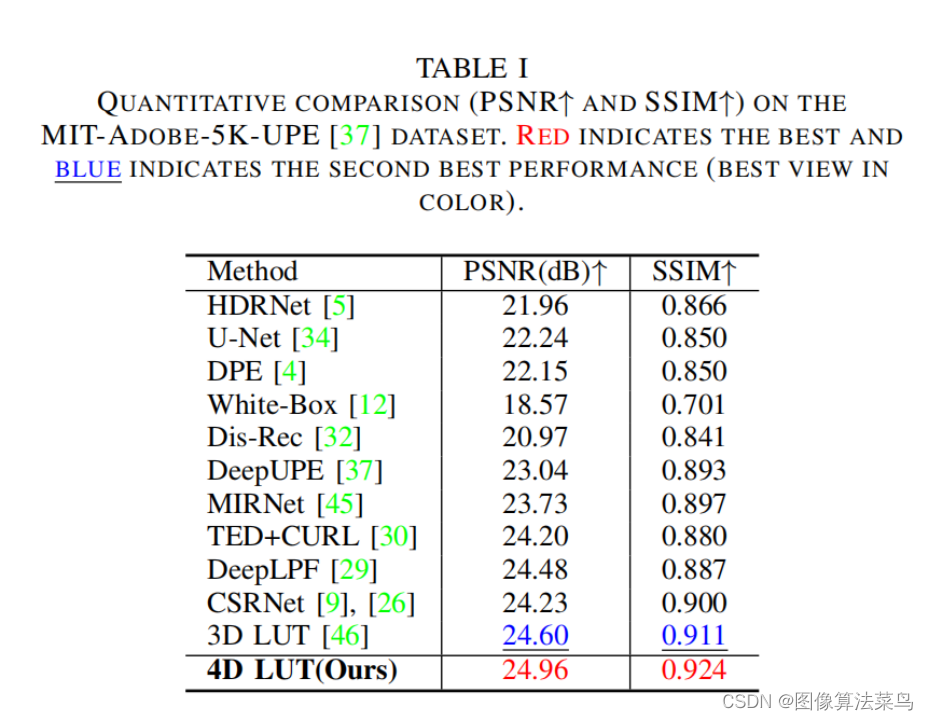
客观指标上,比AI3DLUT高0.3db左右,这里没有直接和SeqLUT和AdaInt对比,差不多比他们好一点点。
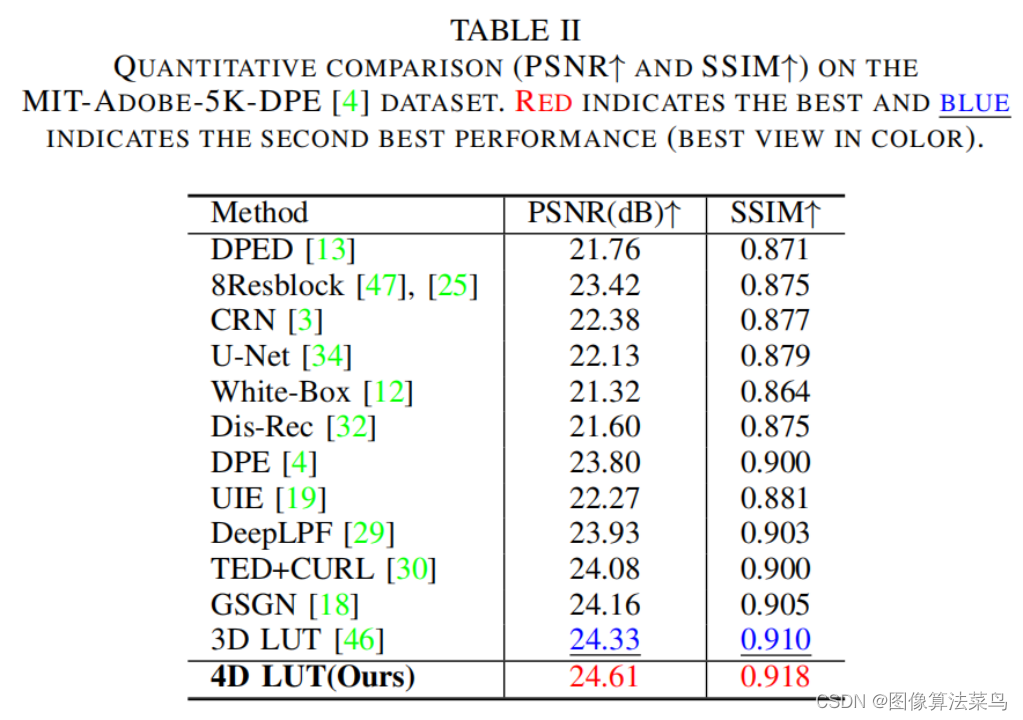
4DLUT由于多了空间上的一个维度,可以处理局部,空间上,不同区域,可以使用不同的3DLUT来做增强,比如蓝天和阴影下,有时阴影会偏蓝,如果把蓝天调的更蓝,那么阴影偏蓝就会加重,而4DLUT可以让蓝天更蓝,而阴影区域可以减蓝,相当于可以实现局部的AWB效果。
CLUT-Net
论文题目:CLUT-Net: Learning Adaptively Compressed Representations of 3DLUTs for Lightweight Image Enhancement
论文地址:https://cslinzhang.gitee.io/home/ACMMM2022/fengyi.pdf
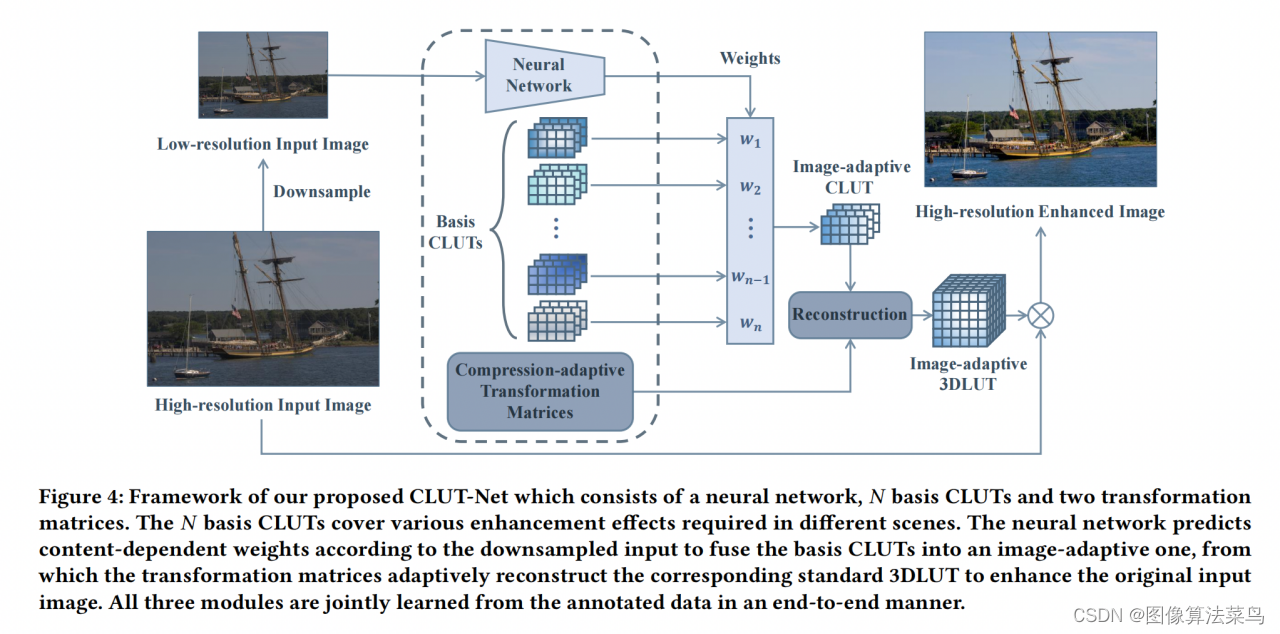
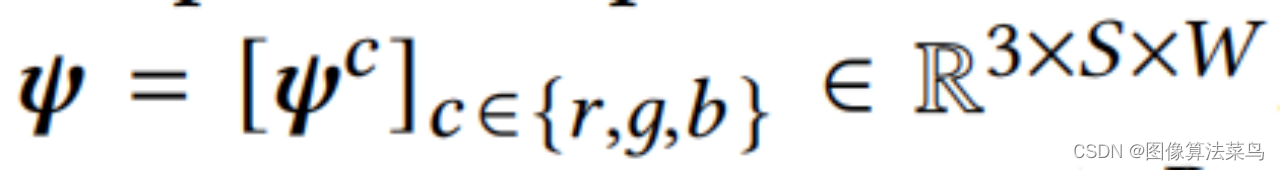
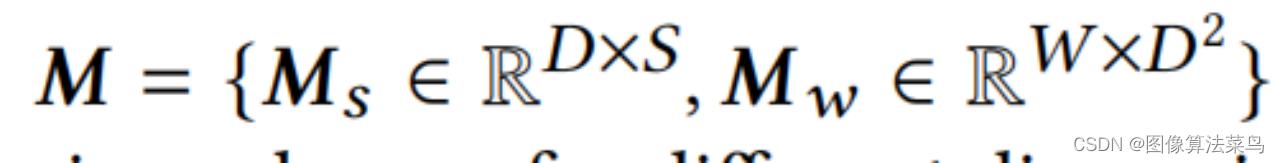
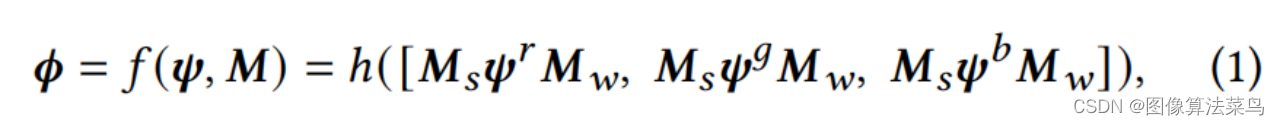
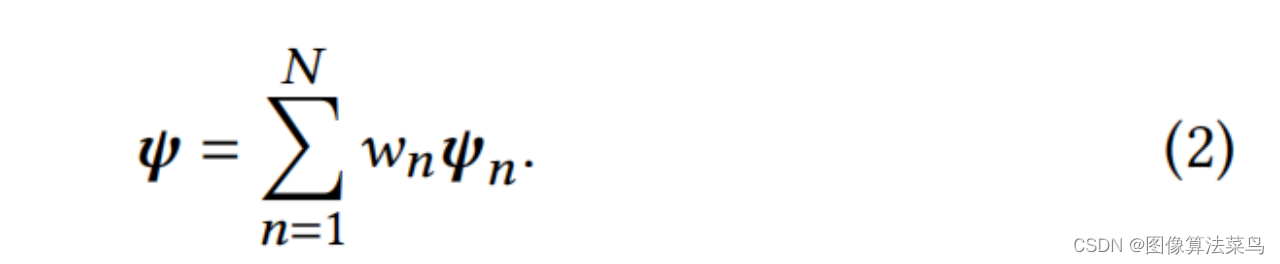
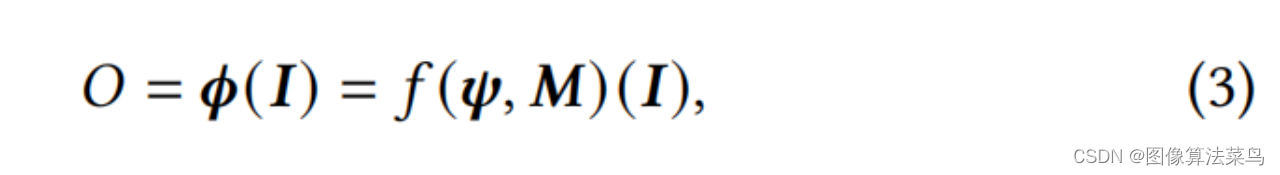
这是ACM-MM2022的一篇论文 。
CLUT-Net主要是针对AI3DLUT那篇论文,从图上也看的出来,二者很接近,主要是认为AI3DLUT网络输出的参数量太大了,只考虑3DLUT部分的参数量,AI3DLUT的参数量为N*3*D*D*D,其中N为basis 3DLUTs的数目,D为3DLUT的节点数目,文章把N个Basis CLUTs,大小为3*S*W,1个Ms矩阵,大小为D*S,1个Mw,大小为W*D*D,对应为Comprehension-adaptive Transformation Matrices模块,按(1)式,把三者乘起来,就可以得到N个3DLUT,对应为Reconstruction模块。可以看到,这样就把N*3*D*D*D的参数量变成了N*3*S*W+D*S+W*D*D大小的参数量,满足S<<D, W<<D*D,如果N很大时,AI3DLUT的参数量就很大,但CLUT-Net中,只有N*3*S*W这一项与N相关,且S和W都相对比较小,所以N越大时,参数减少的就越多。论文中取N=20,S=5,W=20,D=33。其他部分就和AI3DLUT基本一样了,Loss也是一样。另外加权部分是在3*S*W大小矩阵上处理的,运算量比AI3DLUT要小很多。
虽然论文确实用更少的参数实现了N个3DLUT,但文章缺乏严格的数学证明,能否把N个3DLUT,拆分乘N个3*S *W的矩阵+Ms矩阵+Mw矩阵,也没提供拆分的方法,拆分之后二者能否严格相等,如果拆不出来,或者不能严格相等,那么意义就没那么大了,如果能等价拆出来,那在工程上就有很大的意义。
实际工程中,3DLUT插值部分基本上都是硬化到了芯片,由硬件来处理,真正的瓶颈是把一个3DLUT灌给硬件时,参数量较大,一般3DLUT都是用的17个节点,如果33个节点,或者4DLUT,那就会很大,如果能够把3DLUT等价拆分成几个小矩阵,那么参数就可以减少很多,意义就很大,而AI3DLUT网络中,输出参数大,这些都是软件操作,参数量大应该不是瓶颈。
总结
这几篇论文在工程上还是具有较大的参考意义,正则项loss,非均匀间隔采样,以及4DLUT和参数压缩,在不同的具体工程上,应该有借鉴意义。论文之间也有一定的继承性和扩展性。















 9450
9450











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









