








图片来自Coursera的 Machine Learning 课件。
相关资料:
这里是Andrew Ng的课程视频:https://www.coursera.org/learn/machine-learning/home/welcome
梯度下降是其中第十周的内容。
一份很好的梯度下降优化算法的资料:http://sebastianruder.com/optimizing-gradient-descent/ (有时间我会将它完整翻译)
1. Batch gradient descent 是将所有
m个样本全部用来计算gradient,取平均之后再迭代参数。该算法计算量随m的增大而迅速增大。
其中损失函数Loss function是系统输出误差的均方值,将它对参数求导就得到了第二行公式的最后一项,多出来的x一项是由h函数的具体形式决定的,这里h=\theta * x 所以只有x的一次项。

2. Stochastic gradient descent 一次只用一个样本来计算gradient,之后直接迭代参数。一次只用一个样本点会使得一次的descent方向不一定是最速下降的方向,但是计算速度快。



下面的动画是几种不同算法优化过程:
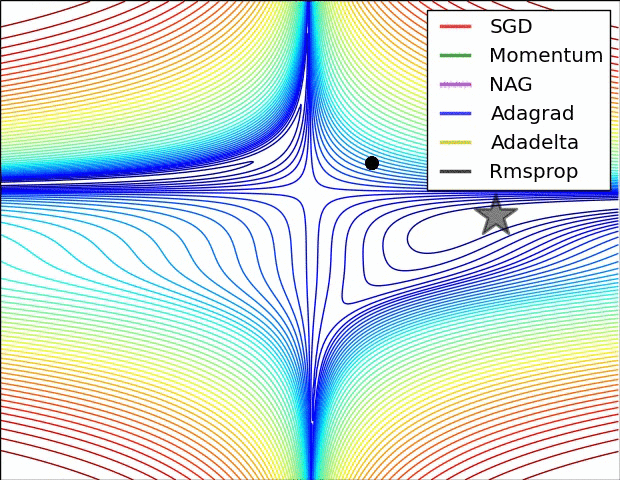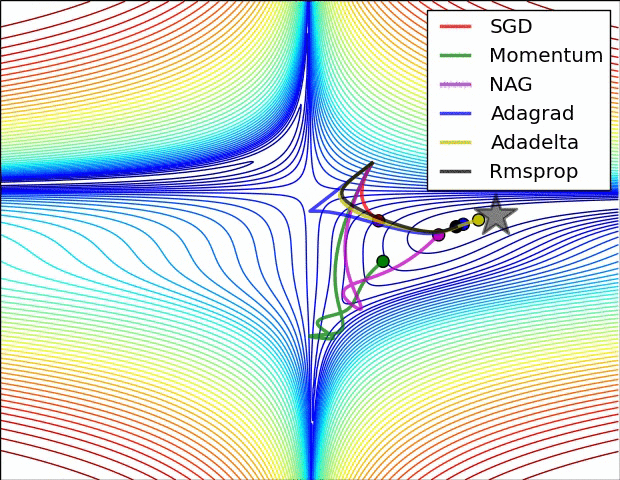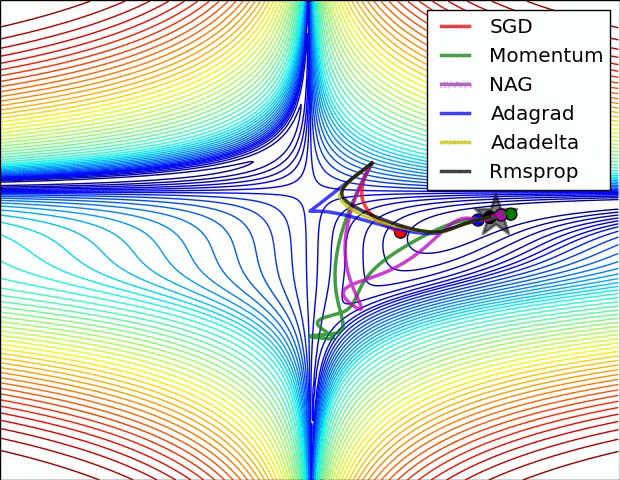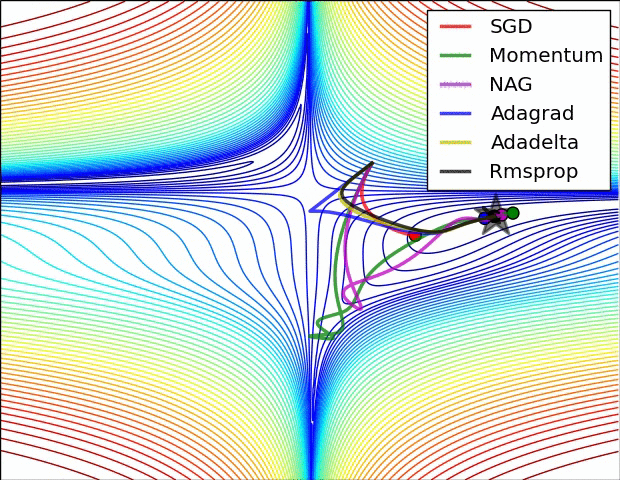















 1430
1430

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









