










Mount with your Google Drive
from google.colab import drive
drive.mount('/content/drive')
Mounted at /content/drive
下载中文字体
!wget -O /usr/share/fonts/truetype/liberation/simhei.ttf "https://www.wfonts.com/download/data/2014/06/01/simhei/chinese.simhei.ttf"
--2021-04-14 05:11:01-- https://www.wfonts.com/download/data/2014/06/01/simhei/chinese.simhei.ttf
Resolving www.wfonts.com (www.wfonts.com)... 104.225.219.210
Connecting to www.wfonts.com (www.wfonts.com)|104.225.219.210|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 10050870 (9.6M) [application/octetstream]
Saving to: ‘/usr/share/fonts/truetype/liberation/simhei.ttf’
/usr/share/fonts/tr 100%[===================>] 9.58M 2.48MB/s in 4.5s
2021-04-14 05:11:07 (2.11 MB/s) - ‘/usr/share/fonts/truetype/liberation/simhei.ttf’ saved [10050870/10050870]
import matplotlib.pyplot as plt
import matplotlib as mpl
zhfont = mpl.font_manager.FontProperties(fname='/usr/share/fonts/truetype/liberation/simhei.ttf')
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
添加依赖库
from keras.applications.densenet import DenseNet121
from keras.preprocessing import image
from keras.models import Model, load_model
from keras.layers import Dense, GlobalAveragePooling2D
from keras import backend as K
from keras.utils import np_utils
from sklearn.model_selection import train_test_split
import tensorflow as tf
from tensorflow import keras
from keras.optimizers import Adam, SGD, RMSprop
from keras.callbacks import Callback, EarlyStopping, TensorBoard, ModelCheckpoint, ReduceLROnPlateau
from keras.preprocessing.image import img_to_array
import os
import random
import numpy as np
import cv2
import matplotlib.pyplot as plt
import shutil
构建数据
解压数据
#shutil.rmtree('./Clip_sample/')
import os
if not os.path.exists('/content/drive/MyDrive/Rock_InceptionV3/Clip_sample.zip'):
!cp /content/drive/MyDrive/Rock_resnet101/Clip_sample.zip -r /content/drive/MyDrive/Rock_InceptionV3/Clip_sample.zip
if not os.path.exists('./Clip_sample/'):
!unzip /content/drive/MyDrive/Rock_InceptionV3/Clip_sample.zip
读取数据
filepath = './Clip_sample/'
def get_train_val(val_rate=0.25):
train_url = []
train_set = []
val_set = []
for pic in os.listdir(filepath):
train_url.append(pic)
random.shuffle(train_url)
total_num = len(train_url)
val_num = int(val_rate * total_num)
for i in range(len(train_url)):
if i < val_num:
val_set.append(train_url[i])
else:
train_set.append(train_url[i])
return train_set, val_set
train_set, val_set = get_train_val()
len(train_set), len(val_set)
(5222, 1740)
def load_img(path, grayscale=False):
if grayscale:
img = cv2.imread(path, cv2.IMREAD_GRAYSCALE)
else:
img = cv2.imread(path)
img = np.array(img, dtype="float") / 255.0
return img
# data for training
def generateData(batch_size, data=[]):
# print 'generateData...'
while True:
train_data = []
train_label = []
batch = 0
for i in (range(len(data))):
url = data[i]
batch += 1
img = load_img(filepath + url)
img = img_to_array(img)
train_data.append(img)
label = img_label(url)
train_label.append(label)
if batch % batch_size == 0:
# print 'get enough bacth!\n'
train_data = np.array(train_data)
train_label = np.array(train_label)
yield (train_data, train_label)
train_data = []
train_label = []
batch = 0
def generateValidData(batch_size, data=[]):
# print 'generateValidData...'
while True:
valid_data = []
valid_label = []
batch = 0
for i in (range(len(data))):
url = data[i]
batch += 1
img = load_img(filepath + url)
img = img_to_array(img)
valid_data.append(img)
label = img_label(url)
valid_label.append(label)
if batch % batch_size == 0:
valid_data = np.array(valid_data)
valid_label = np.array(valid_label)
yield (valid_data, valid_label)
valid_data = []
valid_label = []
batch = 0
def generateTestData(batch_size, data=[]):
# print 'generateTestData...'
while True:
Test_data = []
Test_label = []
batch = 0
for i in (range(len(data))):
url = data[i]
batch += 1
img = load_img(filepath + url)
img = img_to_array(img)
Test_data.append(img)
label = img_label(url)
Test_label.append(label)
if batch % batch_size == 0:
Test_data = np.array(Test_data)
Test_label = np.array(Test_label)
yield (Test_data, Test_label)
Test_data = []
Test_label = []
batch = 0
def img_label(filename):
num_classes = 7
if '1.jpg' in filename:
return np_utils.to_categorical(0, num_classes)
if '2.jpg' in filename:
return np_utils.to_categorical(1, num_classes)
if '3.jpg' in filename:
return np_utils.to_categorical(2, num_classes)
if '4.jpg' in filename:
return np_utils.to_categorical(3, num_classes)
if '5.jpg' in filename:
return np_utils.to_categorical(4, num_classes)
if '6.jpg' in filename:
return np_utils.to_categorical(5, num_classes)
if '7.jpg' in filename:
return np_utils.to_categorical(6, num_classes)
return None
构建预训练模型
# 构建不带分类器的预训练模型
base_model = DenseNet121(weights='imagenet', include_top=False)
## 打印模型结构
base_model.summary()
添加密集连接分类层
# 添加全局平均池化层
x = base_model.output
x = GlobalAveragePooling2D()(x)
# 添加一个全连接层
x = Dense(1024, activation='relu')(x)
# 添加一个分类器,假设我们有7个类
predictions = Dense(7, activation='softmax')(x)
# 构建我们需要训练的完整模型
model = Model(inputs=base_model.input, outputs=predictions)
训练模型
冻结卷积层,训练分类层
# 首先,我们只训练顶部的几层(随机初始化的层)
# 锁住所有 InceptionV3 的卷积层
for layer in base_model.layers:
layer.trainable = False
batch_size = 32 # 批大小
learning_rate = 1e-4 # 设置学习率为1e-4
optimizer = Adam(lr=learning_rate) # 优化器使用 Adam
objective = 'categorical_crossentropy' # loss 函数使用交叉熵
# 模型编译
model.compile(loss=objective, optimizer=optimizer, metrics=['accuracy'])
epochs = 100 # 训练轮数
model_path = './output/Densenet_1.h5'
if not os.path.exists('./output/'):
os.makedirs('./output/')
# 判断预训练权重文件是否存在
if os.path.exists(model_path):
# 载入预训练模型
model = load_model(model_path)
## callback策略
# 学习率衰减策略
reduce_lr = ReduceLROnPlateau(monitor='val_loss', factor=0.1, patience=2, verbose=1) # 学习率衰减策略
# 断点训练,有利于恢复和保存模型
checkpoint = ModelCheckpoint(model_path, monitor='val_accuracy', verbose=1, save_best_only=True, save_weights_only=False, mode='auto', period=1)
# early stopping策略
early_stopping = EarlyStopping(monitor='val_accuracy', patience=4, verbose=1, mode='auto')
train_set, val_set = get_train_val()
train_numb = len(train_set)
valid_numb = len(val_set)
# 开始训练
history = model.fit_generator(
generator=generateData(batch_size, train_set),
steps_per_epoch=train_numb // batch_size, epochs=epochs,verbose=1,
validation_data=generateValidData(batch_size, val_set),
validation_steps=valid_numb // batch_size,
callbacks=[checkpoint, early_stopping, reduce_lr],
max_queue_size=1
)
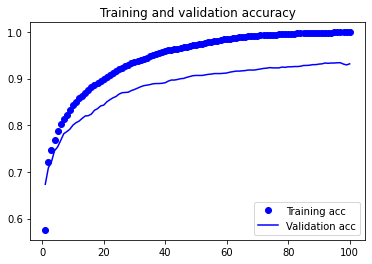
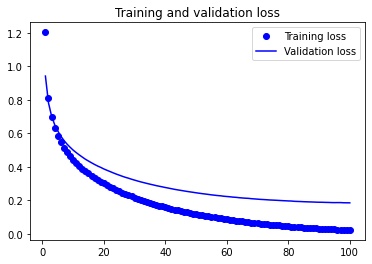
Epoch 1/100
163/163 [==============================] - 137s 592ms/step - loss: 1.4643 - accuracy: 0.4444 - val_loss: 0.9417 - val_accuracy: 0.6736
Epoch 00001: val_accuracy improved from -inf to 0.67361, saving model to ./output/Densenet_1.h5
Epoch 2/100
163/163 [==============================] - 95s 584ms/step - loss: 0.8585 - accuracy: 0.7076 - val_loss: 0.7818 - val_accuracy: 0.7089
Epoch 00002: val_accuracy improved from 0.67361 to 0.70891, saving model to ./output/Densenet_1.h5
Epoch 3/100
163/163 [==============================] - 95s 584ms/step - loss: 0.7232 - accuracy: 0.7365 - val_loss: 0.7035 - val_accuracy: 0.7216
Epoch 00003: val_accuracy improved from 0.70891 to 0.72164, saving model to ./output/Densenet_1.h5
Epoch 4/100
163/163 [==============================] - 95s 584ms/step - loss: 0.6497 - accuracy: 0.7574 - val_loss: 0.6526 - val_accuracy: 0.7454
Epoch 00004: val_accuracy improved from 0.72164 to 0.74537, saving model to ./output/Densenet_1.h5
Epoch 5/100
163/163 [==============================] - 95s 583ms/step - loss: 0.5992 - accuracy: 0.7787 - val_loss: 0.6154 - val_accuracy: 0.7535
Epoch 00005: val_accuracy improved from 0.74537 to 0.75347, saving model to ./output/Densenet_1.h5
Epoch 6/100
163/163 [==============================] - 95s 584ms/step - loss: 0.5597 - accuracy: 0.7970 - val_loss: 0.5839 - val_accuracy: 0.7674
Epoch 00006: val_accuracy improved from 0.75347 to 0.76736, saving model to ./output/Densenet_1.h5
Epoch 7/100
163/163 [==============================] - 95s 585ms/step - loss: 0.5271 - accuracy: 0.8098 - val_loss: 0.5586 - val_accuracy: 0.7818
Epoch 00007: val_accuracy improved from 0.76736 to 0.78183, saving model to ./output/Densenet_1.h5
Epoch 8/100
163/163 [==============================] - 95s 583ms/step - loss: 0.4994 - accuracy: 0.8187 - val_loss: 0.5368 - val_accuracy: 0.7865
Epoch 00008: val_accuracy improved from 0.78183 to 0.78646, saving model to ./output/Densenet_1.h5
Epoch 9/100
163/163 [==============================] - 95s 585ms/step - loss: 0.4751 - accuracy: 0.8276 - val_loss: 0.5179 - val_accuracy: 0.7917
Epoch 00009: val_accuracy improved from 0.78646 to 0.79167, saving model to ./output/Densenet_1.h5
Epoch 10/100
163/163 [==============================] - 95s 584ms/step - loss: 0.4532 - accuracy: 0.8385 - val_loss: 0.5007 - val_accuracy: 0.8003
Epoch 00010: val_accuracy improved from 0.79167 to 0.80035, saving model to ./output/Densenet_1.h5
Epoch 11/100
163/163 [==============================] - 95s 583ms/step - loss: 0.4333 - accuracy: 0.8464 - val_loss: 0.4857 - val_accuracy: 0.8056
Epoch 00011: val_accuracy improved from 0.80035 to 0.80556, saving model to ./output/Densenet_1.h5
Epoch 12/100
163/163 [==============================] - 95s 585ms/step - loss: 0.4152 - accuracy: 0.8554 - val_loss: 0.4719 - val_accuracy: 0.8090
Epoch 00012: val_accuracy improved from 0.80556 to 0.80903, saving model to ./output/Densenet_1.h5
Epoch 13/100
163/163 [==============================] - 95s 583ms/step - loss: 0.3987 - accuracy: 0.8593 - val_loss: 0.4588 - val_accuracy: 0.8148
Epoch 00013: val_accuracy improved from 0.80903 to 0.81481, saving model to ./output/Densenet_1.h5
Epoch 14/100
163/163 [==============================] - 95s 585ms/step - loss: 0.3831 - accuracy: 0.8645 - val_loss: 0.4460 - val_accuracy: 0.8200
Epoch 00014: val_accuracy improved from 0.81481 to 0.82002, saving model to ./output/Densenet_1.h5
Epoch 15/100
163/163 [==============================] - 95s 583ms/step - loss: 0.3689 - accuracy: 0.8708 - val_loss: 0.4352 - val_accuracy: 0.8206
Epoch 00015: val_accuracy improved from 0.82002 to 0.82060, saving model to ./output/Densenet_1.h5
Epoch 16/100
163/163 [==============================] - 95s 584ms/step - loss: 0.3554 - accuracy: 0.8766 - val_loss: 0.4248 - val_accuracy: 0.8241
Epoch 00016: val_accuracy improved from 0.82060 to 0.82407, saving model to ./output/Densenet_1.h5
Epoch 17/100
163/163 [==============================] - 95s 583ms/step - loss: 0.3425 - accuracy: 0.8845 - val_loss: 0.4147 - val_accuracy: 0.8322
Epoch 00017: val_accuracy improved from 0.82407 to 0.83218, saving model to ./output/Densenet_1.h5
Epoch 18/100
163/163 [==============================] - 95s 583ms/step - loss: 0.3303 - accuracy: 0.8861 - val_loss: 0.4053 - val_accuracy: 0.8356
Epoch 00018: val_accuracy improved from 0.83218 to 0.83565, saving model to ./output/Densenet_1.h5
Epoch 19/100
163/163 [==============================] - 95s 583ms/step - loss: 0.3186 - accuracy: 0.8911 - val_loss: 0.3972 - val_accuracy: 0.8414
Epoch 00019: val_accuracy improved from 0.83565 to 0.84144, saving model to ./output/Densenet_1.h5
Epoch 20/100
163/163 [==============================] - 95s 582ms/step - loss: 0.3077 - accuracy: 0.8965 - val_loss: 0.3880 - val_accuracy: 0.8432
Epoch 00020: val_accuracy improved from 0.84144 to 0.84317, saving model to ./output/Densenet_1.h5
Epoch 21/100
163/163 [==============================] - 95s 583ms/step - loss: 0.2973 - accuracy: 0.9013 - val_loss: 0.3803 - val_accuracy: 0.8501
Epoch 00021: val_accuracy improved from 0.84317 to 0.85012, saving model to ./output/Densenet_1.h5
Epoch 22/100
163/163 [==============================] - 95s 585ms/step - loss: 0.2872 - accuracy: 0.9042 - val_loss: 0.3728 - val_accuracy: 0.8547
Epoch 00022: val_accuracy improved from 0.85012 to 0.85475, saving model to ./output/Densenet_1.h5
Epoch 23/100
163/163 [==============================] - 95s 584ms/step - loss: 0.2778 - accuracy: 0.9083 - val_loss: 0.3651 - val_accuracy: 0.8588
Epoch 00023: val_accuracy improved from 0.85475 to 0.85880, saving model to ./output/Densenet_1.h5
Epoch 24/100
163/163 [==============================] - 95s 583ms/step - loss: 0.2688 - accuracy: 0.9134 - val_loss: 0.3578 - val_accuracy: 0.8617
Epoch 00024: val_accuracy improved from 0.85880 to 0.86169, saving model to ./output/Densenet_1.h5
Epoch 25/100
163/163 [==============================] - 95s 584ms/step - loss: 0.2601 - accuracy: 0.9169 - val_loss: 0.3512 - val_accuracy: 0.8669
Epoch 00025: val_accuracy improved from 0.86169 to 0.86690, saving model to ./output/Densenet_1.h5
Epoch 26/100
163/163 [==============================] - 95s 584ms/step - loss: 0.2520 - accuracy: 0.9210 - val_loss: 0.3445 - val_accuracy: 0.8698
Epoch 00026: val_accuracy improved from 0.86690 to 0.86979, saving model to ./output/Densenet_1.h5
Epoch 27/100
163/163 [==============================] - 95s 584ms/step - loss: 0.2439 - accuracy: 0.9252 - val_loss: 0.3383 - val_accuracy: 0.8704
Epoch 00027: val_accuracy improved from 0.86979 to 0.87037, saving model to ./output/Densenet_1.h5
Epoch 28/100
163/163 [==============================] - 95s 583ms/step - loss: 0.2364 - accuracy: 0.9267 - val_loss: 0.3330 - val_accuracy: 0.8709
Epoch 00028: val_accuracy improved from 0.87037 to 0.87095, saving model to ./output/Densenet_1.h5
Epoch 29/100
163/163 [==============================] - 95s 581ms/step - loss: 0.2290 - accuracy: 0.9300 - val_loss: 0.3269 - val_accuracy: 0.8744
Epoch 00029: val_accuracy improved from 0.87095 to 0.87442, saving model to ./output/Densenet_1.h5
Epoch 30/100
163/163 [==============================] - 95s 584ms/step - loss: 0.2220 - accuracy: 0.9336 - val_loss: 0.3215 - val_accuracy: 0.8767
Epoch 00030: val_accuracy improved from 0.87442 to 0.87674, saving model to ./output/Densenet_1.h5
Epoch 31/100
163/163 [==============================] - 95s 584ms/step - loss: 0.2152 - accuracy: 0.9357 - val_loss: 0.3162 - val_accuracy: 0.8796
Epoch 00031: val_accuracy improved from 0.87674 to 0.87963, saving model to ./output/Densenet_1.h5
Epoch 32/100
163/163 [==============================] - 95s 583ms/step - loss: 0.2087 - accuracy: 0.9373 - val_loss: 0.3110 - val_accuracy: 0.8825
Epoch 00032: val_accuracy improved from 0.87963 to 0.88252, saving model to ./output/Densenet_1.h5
Epoch 33/100
163/163 [==============================] - 95s 583ms/step - loss: 0.2024 - accuracy: 0.9400 - val_loss: 0.3064 - val_accuracy: 0.8848
Epoch 00033: val_accuracy improved from 0.88252 to 0.88484, saving model to ./output/Densenet_1.h5
Epoch 34/100
163/163 [==============================] - 95s 584ms/step - loss: 0.1964 - accuracy: 0.9421 - val_loss: 0.3018 - val_accuracy: 0.8860
Epoch 00034: val_accuracy improved from 0.88484 to 0.88600, saving model to ./output/Densenet_1.h5
Epoch 35/100
163/163 [==============================] - 95s 583ms/step - loss: 0.1905 - accuracy: 0.9446 - val_loss: 0.2974 - val_accuracy: 0.8872
Epoch 00035: val_accuracy improved from 0.88600 to 0.88715, saving model to ./output/Densenet_1.h5
Epoch 36/100
163/163 [==============================] - 95s 583ms/step - loss: 0.1848 - accuracy: 0.9474 - val_loss: 0.2932 - val_accuracy: 0.8889
Epoch 00036: val_accuracy improved from 0.88715 to 0.88889, saving model to ./output/Densenet_1.h5
Epoch 37/100
163/163 [==============================] - 95s 583ms/step - loss: 0.1793 - accuracy: 0.9497 - val_loss: 0.2889 - val_accuracy: 0.8895
Epoch 00037: val_accuracy improved from 0.88889 to 0.88947, saving model to ./output/Densenet_1.h5
Epoch 38/100
163/163 [==============================] - 95s 583ms/step - loss: 0.1741 - accuracy: 0.9532 - val_loss: 0.2850 - val_accuracy: 0.8895
Epoch 00038: val_accuracy did not improve from 0.88947
Epoch 39/100
163/163 [==============================] - 95s 584ms/step - loss: 0.1689 - accuracy: 0.9549 - val_loss: 0.2813 - val_accuracy: 0.8900
Epoch 00039: val_accuracy improved from 0.88947 to 0.89005, saving model to ./output/Densenet_1.h5
Epoch 40/100
163/163 [==============================] - 95s 584ms/step - loss: 0.1639 - accuracy: 0.9562 - val_loss: 0.2774 - val_accuracy: 0.8912
Epoch 00040: val_accuracy improved from 0.89005 to 0.89120, saving model to ./output/Densenet_1.h5
Epoch 41/100
163/163 [==============================] - 95s 584ms/step - loss: 0.1590 - accuracy: 0.9576 - val_loss: 0.2740 - val_accuracy: 0.8947
Epoch 00041: val_accuracy improved from 0.89120 to 0.89468, saving model to ./output/Densenet_1.h5
Epoch 42/100
163/163 [==============================] - 95s 583ms/step - loss: 0.1545 - accuracy: 0.9590 - val_loss: 0.2702 - val_accuracy: 0.8970
Epoch 00042: val_accuracy improved from 0.89468 to 0.89699, saving model to ./output/Densenet_1.h5
Epoch 43/100
163/163 [==============================] - 95s 582ms/step - loss: 0.1499 - accuracy: 0.9612 - val_loss: 0.2666 - val_accuracy: 0.8970
Epoch 00043: val_accuracy did not improve from 0.89699
Epoch 44/100
163/163 [==============================] - 95s 584ms/step - loss: 0.1454 - accuracy: 0.9622 - val_loss: 0.2633 - val_accuracy: 0.8981
Epoch 00044: val_accuracy improved from 0.89699 to 0.89815, saving model to ./output/Densenet_1.h5
Epoch 45/100
163/163 [==============================] - 95s 582ms/step - loss: 0.1412 - accuracy: 0.9635 - val_loss: 0.2604 - val_accuracy: 0.8999
Epoch 00045: val_accuracy improved from 0.89815 to 0.89988, saving model to ./output/Densenet_1.h5
Epoch 46/100
163/163 [==============================] - 95s 583ms/step - loss: 0.1370 - accuracy: 0.9643 - val_loss: 0.2573 - val_accuracy: 0.9005
Epoch 00046: val_accuracy improved from 0.89988 to 0.90046, saving model to ./output/Densenet_1.h5
Epoch 47/100
163/163 [==============================] - 95s 582ms/step - loss: 0.1330 - accuracy: 0.9654 - val_loss: 0.2543 - val_accuracy: 0.9028
Epoch 00047: val_accuracy improved from 0.90046 to 0.90278, saving model to ./output/Densenet_1.h5
Epoch 48/100
163/163 [==============================] - 95s 583ms/step - loss: 0.1290 - accuracy: 0.9673 - val_loss: 0.2515 - val_accuracy: 0.9045
Epoch 00048: val_accuracy improved from 0.90278 to 0.90451, saving model to ./output/Densenet_1.h5
Epoch 49/100
163/163 [==============================] - 95s 584ms/step - loss: 0.1253 - accuracy: 0.9683 - val_loss: 0.2488 - val_accuracy: 0.9062
Epoch 00049: val_accuracy improved from 0.90451 to 0.90625, saving model to ./output/Densenet_1.h5
Epoch 50/100
163/163 [==============================] - 95s 584ms/step - loss: 0.1215 - accuracy: 0.9693 - val_loss: 0.2459 - val_accuracy: 0.9068
Epoch 00050: val_accuracy improved from 0.90625 to 0.90683, saving model to ./output/Densenet_1.h5
Epoch 51/100
163/163 [==============================] - 95s 583ms/step - loss: 0.1179 - accuracy: 0.9702 - val_loss: 0.2434 - val_accuracy: 0.9068
Epoch 00051: val_accuracy did not improve from 0.90683
Epoch 52/100
163/163 [==============================] - 95s 583ms/step - loss: 0.1145 - accuracy: 0.9716 - val_loss: 0.2408 - val_accuracy: 0.9068
Epoch 00052: val_accuracy did not improve from 0.90683
Epoch 53/100
163/163 [==============================] - 95s 583ms/step - loss: 0.1112 - accuracy: 0.9724 - val_loss: 0.2386 - val_accuracy: 0.9080
Epoch 00053: val_accuracy improved from 0.90683 to 0.90799, saving model to ./output/Densenet_1.h5
Epoch 54/100
163/163 [==============================] - 95s 584ms/step - loss: 0.1078 - accuracy: 0.9748 - val_loss: 0.2362 - val_accuracy: 0.9091
Epoch 00054: val_accuracy improved from 0.90799 to 0.90914, saving model to ./output/Densenet_1.h5
Epoch 55/100
163/163 [==============================] - 95s 584ms/step - loss: 0.1047 - accuracy: 0.9756 - val_loss: 0.2336 - val_accuracy: 0.9097
Epoch 00055: val_accuracy improved from 0.90914 to 0.90972, saving model to ./output/Densenet_1.h5
Epoch 56/100
163/163 [==============================] - 95s 585ms/step - loss: 0.1016 - accuracy: 0.9778 - val_loss: 0.2316 - val_accuracy: 0.9109
Epoch 00056: val_accuracy improved from 0.90972 to 0.91088, saving model to ./output/Densenet_1.h5
Epoch 57/100
163/163 [==============================] - 95s 585ms/step - loss: 0.0985 - accuracy: 0.9799 - val_loss: 0.2295 - val_accuracy: 0.9109
Epoch 00057: val_accuracy did not improve from 0.91088
Epoch 58/100
163/163 [==============================] - 95s 584ms/step - loss: 0.0956 - accuracy: 0.9812 - val_loss: 0.2279 - val_accuracy: 0.9109
Epoch 00058: val_accuracy did not improve from 0.91088
Epoch 59/100
163/163 [==============================] - 95s 585ms/step - loss: 0.0928 - accuracy: 0.9819 - val_loss: 0.2253 - val_accuracy: 0.9115
Epoch 00059: val_accuracy improved from 0.91088 to 0.91146, saving model to ./output/Densenet_1.h5
Epoch 60/100
163/163 [==============================] - 95s 583ms/step - loss: 0.0899 - accuracy: 0.9828 - val_loss: 0.2238 - val_accuracy: 0.9120
Epoch 00060: val_accuracy improved from 0.91146 to 0.91204, saving model to ./output/Densenet_1.h5
Epoch 61/100
163/163 [==============================] - 95s 583ms/step - loss: 0.0873 - accuracy: 0.9830 - val_loss: 0.2222 - val_accuracy: 0.9138
Epoch 00061: val_accuracy improved from 0.91204 to 0.91377, saving model to ./output/Densenet_1.h5
Epoch 62/100
163/163 [==============================] - 95s 584ms/step - loss: 0.0845 - accuracy: 0.9839 - val_loss: 0.2202 - val_accuracy: 0.9149
Epoch 00062: val_accuracy improved from 0.91377 to 0.91493, saving model to ./output/Densenet_1.h5
Epoch 63/100
163/163 [==============================] - 95s 585ms/step - loss: 0.0820 - accuracy: 0.9844 - val_loss: 0.2188 - val_accuracy: 0.9161
Epoch 00063: val_accuracy improved from 0.91493 to 0.91609, saving model to ./output/Densenet_1.h5
Epoch 64/100
163/163 [==============================] - 95s 585ms/step - loss: 0.0795 - accuracy: 0.9853 - val_loss: 0.2167 - val_accuracy: 0.9161
Epoch 00064: val_accuracy did not improve from 0.91609
Epoch 65/100
163/163 [==============================] - 95s 585ms/step - loss: 0.0771 - accuracy: 0.9865 - val_loss: 0.2152 - val_accuracy: 0.9167
Epoch 00065: val_accuracy improved from 0.91609 to 0.91667, saving model to ./output/Densenet_1.h5
Epoch 66/100
163/163 [==============================] - 95s 584ms/step - loss: 0.0747 - accuracy: 0.9874 - val_loss: 0.2137 - val_accuracy: 0.9172
Epoch 00066: val_accuracy improved from 0.91667 to 0.91725, saving model to ./output/Densenet_1.h5
Epoch 67/100
163/163 [==============================] - 95s 583ms/step - loss: 0.0723 - accuracy: 0.9875 - val_loss: 0.2128 - val_accuracy: 0.9184
Epoch 00067: val_accuracy improved from 0.91725 to 0.91840, saving model to ./output/Densenet_1.h5
Epoch 68/100
163/163 [==============================] - 95s 583ms/step - loss: 0.0701 - accuracy: 0.9892 - val_loss: 0.2108 - val_accuracy: 0.9184
Epoch 00068: val_accuracy did not improve from 0.91840
Epoch 69/100
163/163 [==============================] - 95s 583ms/step - loss: 0.0679 - accuracy: 0.9895 - val_loss: 0.2094 - val_accuracy: 0.9184
Epoch 00069: val_accuracy did not improve from 0.91840
Epoch 70/100
163/163 [==============================] - 95s 584ms/step - loss: 0.0659 - accuracy: 0.9896 - val_loss: 0.2080 - val_accuracy: 0.9196
Epoch 00070: val_accuracy improved from 0.91840 to 0.91956, saving model to ./output/Densenet_1.h5
Epoch 71/100
163/163 [==============================] - 95s 583ms/step - loss: 0.0637 - accuracy: 0.9907 - val_loss: 0.2066 - val_accuracy: 0.9207
Epoch 00071: val_accuracy improved from 0.91956 to 0.92072, saving model to ./output/Densenet_1.h5
Epoch 72/100
163/163 [==============================] - 95s 583ms/step - loss: 0.0617 - accuracy: 0.9909 - val_loss: 0.2056 - val_accuracy: 0.9219
Epoch 00072: val_accuracy improved from 0.92072 to 0.92188, saving model to ./output/Densenet_1.h5
Epoch 73/100
163/163 [==============================] - 95s 586ms/step - loss: 0.0598 - accuracy: 0.9916 - val_loss: 0.2044 - val_accuracy: 0.9225
Epoch 00073: val_accuracy improved from 0.92188 to 0.92245, saving model to ./output/Densenet_1.h5
Epoch 74/100
163/163 [==============================] - 95s 584ms/step - loss: 0.0579 - accuracy: 0.9916 - val_loss: 0.2031 - val_accuracy: 0.9236
Epoch 00074: val_accuracy improved from 0.92245 to 0.92361, saving model to ./output/Densenet_1.h5
Epoch 75/100
163/163 [==============================] - 95s 585ms/step - loss: 0.0560 - accuracy: 0.9917 - val_loss: 0.2023 - val_accuracy: 0.9230
Epoch 00075: val_accuracy did not improve from 0.92361
Epoch 76/100
163/163 [==============================] - 95s 585ms/step - loss: 0.0542 - accuracy: 0.9919 - val_loss: 0.2013 - val_accuracy: 0.9230
Epoch 00076: val_accuracy did not improve from 0.92361
Epoch 77/100
163/163 [==============================] - 95s 583ms/step - loss: 0.0524 - accuracy: 0.9926 - val_loss: 0.2003 - val_accuracy: 0.9230
Epoch 00077: val_accuracy did not improve from 0.92361
Epoch 78/100
163/163 [==============================] - 95s 584ms/step - loss: 0.0508 - accuracy: 0.9931 - val_loss: 0.1992 - val_accuracy: 0.9248
Epoch 00078: val_accuracy improved from 0.92361 to 0.92477, saving model to ./output/Densenet_1.h5
Epoch 79/100
163/163 [==============================] - 95s 584ms/step - loss: 0.0491 - accuracy: 0.9932 - val_loss: 0.1984 - val_accuracy: 0.9242
Epoch 00079: val_accuracy did not improve from 0.92477
Epoch 80/100
163/163 [==============================] - 95s 586ms/step - loss: 0.0475 - accuracy: 0.9945 - val_loss: 0.1974 - val_accuracy: 0.9253
Epoch 00080: val_accuracy improved from 0.92477 to 0.92535, saving model to ./output/Densenet_1.h5
Epoch 81/100
163/163 [==============================] - 95s 584ms/step - loss: 0.0459 - accuracy: 0.9955 - val_loss: 0.1968 - val_accuracy: 0.9253
Epoch 00081: val_accuracy did not improve from 0.92535
Epoch 82/100
163/163 [==============================] - 95s 585ms/step - loss: 0.0444 - accuracy: 0.9955 - val_loss: 0.1951 - val_accuracy: 0.9259
Epoch 00082: val_accuracy improved from 0.92535 to 0.92593, saving model to ./output/Densenet_1.h5
Epoch 83/100
163/163 [==============================] - 95s 583ms/step - loss: 0.0428 - accuracy: 0.9956 - val_loss: 0.1944 - val_accuracy: 0.9259
Epoch 00083: val_accuracy did not improve from 0.92593
Epoch 84/100
163/163 [==============================] - 95s 584ms/step - loss: 0.0415 - accuracy: 0.9957 - val_loss: 0.1937 - val_accuracy: 0.9265
Epoch 00084: val_accuracy improved from 0.92593 to 0.92650, saving model to ./output/Densenet_1.h5
Epoch 85/100
163/163 [==============================] - 95s 584ms/step - loss: 0.0401 - accuracy: 0.9962 - val_loss: 0.1928 - val_accuracy: 0.9282
Epoch 00085: val_accuracy improved from 0.92650 to 0.92824, saving model to ./output/Densenet_1.h5
Epoch 86/100
163/163 [==============================] - 95s 584ms/step - loss: 0.0387 - accuracy: 0.9957 - val_loss: 0.1922 - val_accuracy: 0.9282
Epoch 00086: val_accuracy did not improve from 0.92824
Epoch 87/100
163/163 [==============================] - 95s 585ms/step - loss: 0.0373 - accuracy: 0.9962 - val_loss: 0.1915 - val_accuracy: 0.9288
Epoch 00087: val_accuracy improved from 0.92824 to 0.92882, saving model to ./output/Densenet_1.h5
Epoch 88/100
163/163 [==============================] - 95s 582ms/step - loss: 0.0361 - accuracy: 0.9964 - val_loss: 0.1909 - val_accuracy: 0.9300
Epoch 00088: val_accuracy improved from 0.92882 to 0.92998, saving model to ./output/Densenet_1.h5
Epoch 89/100
163/163 [==============================] - 95s 583ms/step - loss: 0.0349 - accuracy: 0.9966 - val_loss: 0.1902 - val_accuracy: 0.9300
Epoch 00089: val_accuracy did not improve from 0.92998
Epoch 90/100
163/163 [==============================] - 95s 584ms/step - loss: 0.0336 - accuracy: 0.9981 - val_loss: 0.1895 - val_accuracy: 0.9311
Epoch 00090: val_accuracy improved from 0.92998 to 0.93113, saving model to ./output/Densenet_1.h5
Epoch 91/100
163/163 [==============================] - 95s 584ms/step - loss: 0.0325 - accuracy: 0.9981 - val_loss: 0.1894 - val_accuracy: 0.9317
Epoch 00091: val_accuracy improved from 0.93113 to 0.93171, saving model to ./output/Densenet_1.h5
Epoch 92/100
163/163 [==============================] - 95s 583ms/step - loss: 0.0313 - accuracy: 0.9985 - val_loss: 0.1887 - val_accuracy: 0.9334
Epoch 00092: val_accuracy improved from 0.93171 to 0.93345, saving model to ./output/Densenet_1.h5
Epoch 93/100
163/163 [==============================] - 95s 583ms/step - loss: 0.0302 - accuracy: 0.9985 - val_loss: 0.1884 - val_accuracy: 0.9329
Epoch 00093: val_accuracy did not improve from 0.93345
Epoch 94/100
163/163 [==============================] - 95s 584ms/step - loss: 0.0291 - accuracy: 0.9985 - val_loss: 0.1877 - val_accuracy: 0.9334
Epoch 00094: val_accuracy did not improve from 0.93345
Epoch 95/100
163/163 [==============================] - 95s 584ms/step - loss: 0.0280 - accuracy: 0.9992 - val_loss: 0.1873 - val_accuracy: 0.9334
Epoch 00095: val_accuracy did not improve from 0.93345
Epoch 96/100
163/163 [==============================] - 95s 582ms/step - loss: 0.0271 - accuracy: 0.9992 - val_loss: 0.1875 - val_accuracy: 0.9340
Epoch 00096: val_accuracy improved from 0.93345 to 0.93403, saving model to ./output/Densenet_1.h5
Epoch 97/100
163/163 [==============================] - 95s 583ms/step - loss: 0.0261 - accuracy: 0.9992 - val_loss: 0.1875 - val_accuracy: 0.9340
Epoch 00097: val_accuracy did not improve from 0.93403
Epoch 00097: ReduceLROnPlateau reducing learning rate to 9.999999747378752e-06.
Epoch 98/100
163/163 [==============================] - 95s 583ms/step - loss: 0.0261 - accuracy: 0.9997 - val_loss: 0.1865 - val_accuracy: 0.9311
Epoch 00098: val_accuracy did not improve from 0.93403
Epoch 99/100
163/163 [==============================] - 95s 584ms/step - loss: 0.0279 - accuracy: 0.9988 - val_loss: 0.1862 - val_accuracy: 0.9294
Epoch 00099: val_accuracy did not improve from 0.93403
Epoch 100/100
163/163 [==============================] - 95s 584ms/step - loss: 0.0276 - accuracy: 0.9988 - val_loss: 0.1860 - val_accuracy: 0.9317
Epoch 00100: val_accuracy did not improve from 0.93403
Epoch 00100: early stopping
!cp ./output/Densenet_1.h5 -r /content/drive/MyDrive/models/pre_model/Densenet_1.h5
训练可视化
loss = history.history['loss']
val_loss = history.history['val_loss']
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
epochs = range(1, len(acc) + 1)
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
lr = history.history['lr']
plt.plot(epochs, lr, 'b', label='learning rate')
联合训练卷积层
现在顶层应该训练好了,让我们开始微调 Inception V3 的卷积层。
我们锁住底下的几层,然后训练其余的顶层。
# 让我们看看每一层的名字和层号,看看我们应该锁多少层呢:
for i, layer in enumerate(base_model.layers):
print(i, layer.name)
!cp /content/drive/MyDrive/models/pre_model/Densenet_1.h5 -r ./output/Densenet_1.h5
锁住前249层,开放后面的层
model = load_model('./output/Densenet_1.h5')
# 我们选择训练最上面的两个 Inception block
# 也就是说锁住前面312层,然后放开之后的层。
for layer in model.layers[:312]:
layer.trainable = False
for layer in model.layers[312:]:
layer.trainable = True
重新编译模型,并使用SGD优化器进行微调
# 设置一个很低的学习率,使用SGD来微调
from keras.optimizers import SGD
batch_size = 32 # 批大小
learning_rate = 1e-5 # 设置学习率为1e-4
optimizer = Adam(lr=learning_rate) # 优化器使用 Adam
objective = 'categorical_crossentropy' # loss 函数使用交叉熵
# 模型编译
model.compile(loss=objective, optimizer=optimizer, metrics=['accuracy'])
# if os.path.exists(model_path):
# model = load_model(model_path)
epochs = 100 # 训练轮数
model_path = './output/Inception_2.h5'
## callback策略
# 学习率衰减策略
reduce_lr = ReduceLROnPlateau(monitor='val_loss', factor=0.1, patience=3, verbose=1) # 学习率衰减策略
# 断点训练,有利于恢复和保存模型
checkpoint = ModelCheckpoint(model_path, monitor='val_accuracy', verbose=1, save_best_only=True, save_weights_only=False, mode='auto', period=1)
# early stopping策略
early_stopping = EarlyStopping(monitor='val_accuracy', patience=5, verbose=1, mode='auto')
# 判断预训练权重文件是否存在
if os.path.exists('./output/Inception_2.h5'):
# 载入预训练模型
model = load_model('./output/Inception_2.h5')
train_numb = len(train_set)
valid_numb = len(val_set)
# 开始训练
history = model.fit_generator(
generator=generateData(batch_size, train_set),
steps_per_epoch=train_numb // batch_size, epochs=epochs,verbose=1,
validation_data=generateValidData(batch_size, val_set),
validation_steps=valid_numb // batch_size,
callbacks=[checkpoint, early_stopping, reduce_lr],
max_queue_size=1
)
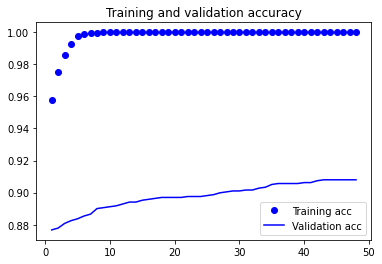
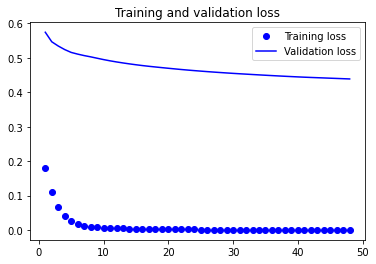
Epoch 1/100
163/163 [==============================] - 119s 708ms/step - loss: 0.1795 - accuracy: 0.9578 - val_loss: 0.5743 - val_accuracy: 0.8767
Epoch 00001: val_accuracy improved from -inf to 0.87674, saving model to ./output/Inception_2.h5
Epoch 2/100
163/163 [==============================] - 117s 720ms/step - loss: 0.1089 - accuracy: 0.9751 - val_loss: 0.5466 - val_accuracy: 0.8779
Epoch 00002: val_accuracy improved from 0.87674 to 0.87789, saving model to ./output/Inception_2.h5
Epoch 3/100
163/163 [==============================] - 117s 721ms/step - loss: 0.0656 - accuracy: 0.9856 - val_loss: 0.5343 - val_accuracy: 0.8808
Epoch 00003: val_accuracy improved from 0.87789 to 0.88079, saving model to ./output/Inception_2.h5
Epoch 4/100
163/163 [==============================] - 117s 721ms/step - loss: 0.0398 - accuracy: 0.9929 - val_loss: 0.5240 - val_accuracy: 0.8825
Epoch 00004: val_accuracy improved from 0.88079 to 0.88252, saving model to ./output/Inception_2.h5
Epoch 5/100
163/163 [==============================] - 117s 721ms/step - loss: 0.0254 - accuracy: 0.9979 - val_loss: 0.5157 - val_accuracy: 0.8837
Epoch 00005: val_accuracy improved from 0.88252 to 0.88368, saving model to ./output/Inception_2.h5
Epoch 6/100
163/163 [==============================] - 117s 719ms/step - loss: 0.0177 - accuracy: 0.9990 - val_loss: 0.5108 - val_accuracy: 0.8854
Epoch 00006: val_accuracy improved from 0.88368 to 0.88542, saving model to ./output/Inception_2.h5
Epoch 7/100
163/163 [==============================] - 117s 718ms/step - loss: 0.0129 - accuracy: 0.9996 - val_loss: 0.5065 - val_accuracy: 0.8866
Epoch 00007: val_accuracy improved from 0.88542 to 0.88657, saving model to ./output/Inception_2.h5
Epoch 8/100
163/163 [==============================] - 117s 717ms/step - loss: 0.0098 - accuracy: 0.9998 - val_loss: 0.5029 - val_accuracy: 0.8900
Epoch 00008: val_accuracy improved from 0.88657 to 0.89005, saving model to ./output/Inception_2.h5
Epoch 9/100
163/163 [==============================] - 116s 713ms/step - loss: 0.0080 - accuracy: 1.0000 - val_loss: 0.4988 - val_accuracy: 0.8906
Epoch 00009: val_accuracy improved from 0.89005 to 0.89062, saving model to ./output/Inception_2.h5
Epoch 10/100
163/163 [==============================] - 115s 708ms/step - loss: 0.0068 - accuracy: 1.0000 - val_loss: 0.4949 - val_accuracy: 0.8912
Epoch 00010: val_accuracy improved from 0.89062 to 0.89120, saving model to ./output/Inception_2.h5
Epoch 11/100
163/163 [==============================] - 115s 708ms/step - loss: 0.0059 - accuracy: 1.0000 - val_loss: 0.4913 - val_accuracy: 0.8918
Epoch 00011: val_accuracy improved from 0.89120 to 0.89178, saving model to ./output/Inception_2.h5
Epoch 12/100
163/163 [==============================] - 115s 706ms/step - loss: 0.0051 - accuracy: 1.0000 - val_loss: 0.4881 - val_accuracy: 0.8929
Epoch 00012: val_accuracy improved from 0.89178 to 0.89294, saving model to ./output/Inception_2.h5
Epoch 13/100
163/163 [==============================] - 115s 706ms/step - loss: 0.0045 - accuracy: 1.0000 - val_loss: 0.4851 - val_accuracy: 0.8941
Epoch 00013: val_accuracy improved from 0.89294 to 0.89410, saving model to ./output/Inception_2.h5
Epoch 14/100
163/163 [==============================] - 115s 707ms/step - loss: 0.0040 - accuracy: 1.0000 - val_loss: 0.4824 - val_accuracy: 0.8941
Epoch 00014: val_accuracy did not improve from 0.89410
Epoch 15/100
163/163 [==============================] - 115s 706ms/step - loss: 0.0035 - accuracy: 1.0000 - val_loss: 0.4799 - val_accuracy: 0.8953
Epoch 00015: val_accuracy improved from 0.89410 to 0.89525, saving model to ./output/Inception_2.h5
Epoch 16/100
163/163 [==============================] - 115s 708ms/step - loss: 0.0031 - accuracy: 1.0000 - val_loss: 0.4775 - val_accuracy: 0.8958
Epoch 00016: val_accuracy improved from 0.89525 to 0.89583, saving model to ./output/Inception_2.h5
Epoch 17/100
163/163 [==============================] - 115s 707ms/step - loss: 0.0028 - accuracy: 1.0000 - val_loss: 0.4754 - val_accuracy: 0.8964
Epoch 00017: val_accuracy improved from 0.89583 to 0.89641, saving model to ./output/Inception_2.h5
Epoch 18/100
163/163 [==============================] - 115s 705ms/step - loss: 0.0025 - accuracy: 1.0000 - val_loss: 0.4734 - val_accuracy: 0.8970
Epoch 00018: val_accuracy improved from 0.89641 to 0.89699, saving model to ./output/Inception_2.h5
Epoch 19/100
163/163 [==============================] - 115s 704ms/step - loss: 0.0023 - accuracy: 1.0000 - val_loss: 0.4715 - val_accuracy: 0.8970
Epoch 00019: val_accuracy did not improve from 0.89699
Epoch 20/100
163/163 [==============================] - 115s 706ms/step - loss: 0.0021 - accuracy: 1.0000 - val_loss: 0.4697 - val_accuracy: 0.8970
Epoch 00020: val_accuracy did not improve from 0.89699
Epoch 21/100
163/163 [==============================] - 115s 707ms/step - loss: 0.0019 - accuracy: 1.0000 - val_loss: 0.4678 - val_accuracy: 0.8970
Epoch 00021: val_accuracy did not improve from 0.89699
Epoch 22/100
163/163 [==============================] - 115s 706ms/step - loss: 0.0017 - accuracy: 1.0000 - val_loss: 0.4661 - val_accuracy: 0.8976
Epoch 00022: val_accuracy improved from 0.89699 to 0.89757, saving model to ./output/Inception_2.h5
Epoch 23/100
163/163 [==============================] - 115s 704ms/step - loss: 0.0015 - accuracy: 1.0000 - val_loss: 0.4644 - val_accuracy: 0.8976
Epoch 00023: val_accuracy did not improve from 0.89757
Epoch 24/100
163/163 [==============================] - 115s 707ms/step - loss: 0.0014 - accuracy: 1.0000 - val_loss: 0.4629 - val_accuracy: 0.8976
Epoch 00024: val_accuracy did not improve from 0.89757
Epoch 25/100
163/163 [==============================] - 115s 707ms/step - loss: 0.0013 - accuracy: 1.0000 - val_loss: 0.4614 - val_accuracy: 0.8981
Epoch 00025: val_accuracy improved from 0.89757 to 0.89815, saving model to ./output/Inception_2.h5
Epoch 26/100
163/163 [==============================] - 115s 709ms/step - loss: 0.0012 - accuracy: 1.0000 - val_loss: 0.4600 - val_accuracy: 0.8987
Epoch 00026: val_accuracy improved from 0.89815 to 0.89873, saving model to ./output/Inception_2.h5
Epoch 27/100
163/163 [==============================] - 115s 708ms/step - loss: 0.0011 - accuracy: 1.0000 - val_loss: 0.4586 - val_accuracy: 0.8999
Epoch 00027: val_accuracy improved from 0.89873 to 0.89988, saving model to ./output/Inception_2.h5
Epoch 28/100
163/163 [==============================] - 115s 704ms/step - loss: 9.7575e-04 - accuracy: 1.0000 - val_loss: 0.4573 - val_accuracy: 0.9005
Epoch 00028: val_accuracy improved from 0.89988 to 0.90046, saving model to ./output/Inception_2.h5
Epoch 29/100
163/163 [==============================] - 115s 707ms/step - loss: 8.9348e-04 - accuracy: 1.0000 - val_loss: 0.4561 - val_accuracy: 0.9010
Epoch 00029: val_accuracy improved from 0.90046 to 0.90104, saving model to ./output/Inception_2.h5
Epoch 30/100
163/163 [==============================] - 115s 709ms/step - loss: 8.1851e-04 - accuracy: 1.0000 - val_loss: 0.4549 - val_accuracy: 0.9010
Epoch 00030: val_accuracy did not improve from 0.90104
Epoch 31/100
163/163 [==============================] - 116s 716ms/step - loss: 7.5017e-04 - accuracy: 1.0000 - val_loss: 0.4537 - val_accuracy: 0.9016
Epoch 00031: val_accuracy improved from 0.90104 to 0.90162, saving model to ./output/Inception_2.h5
Epoch 32/100
163/163 [==============================] - 115s 708ms/step - loss: 6.8786e-04 - accuracy: 1.0000 - val_loss: 0.4526 - val_accuracy: 0.9016
Epoch 00032: val_accuracy did not improve from 0.90162
Epoch 33/100
163/163 [==============================] - 117s 721ms/step - loss: 6.3090e-04 - accuracy: 1.0000 - val_loss: 0.4515 - val_accuracy: 0.9028
Epoch 00033: val_accuracy improved from 0.90162 to 0.90278, saving model to ./output/Inception_2.h5
Epoch 34/100
163/163 [==============================] - 117s 721ms/step - loss: 5.7888e-04 - accuracy: 1.0000 - val_loss: 0.4505 - val_accuracy: 0.9034
Epoch 00034: val_accuracy improved from 0.90278 to 0.90336, saving model to ./output/Inception_2.h5
Epoch 35/100
163/163 [==============================] - 117s 720ms/step - loss: 5.3129e-04 - accuracy: 1.0000 - val_loss: 0.4494 - val_accuracy: 0.9051
Epoch 00035: val_accuracy improved from 0.90336 to 0.90509, saving model to ./output/Inception_2.h5
Epoch 36/100
163/163 [==============================] - 117s 721ms/step - loss: 4.8763e-04 - accuracy: 1.0000 - val_loss: 0.4484 - val_accuracy: 0.9057
Epoch 00036: val_accuracy improved from 0.90509 to 0.90567, saving model to ./output/Inception_2.h5
Epoch 37/100
163/163 [==============================] - 117s 722ms/step - loss: 4.4760e-04 - accuracy: 1.0000 - val_loss: 0.4474 - val_accuracy: 0.9057
Epoch 00037: val_accuracy did not improve from 0.90567
Epoch 38/100
163/163 [==============================] - 117s 721ms/step - loss: 4.1103e-04 - accuracy: 1.0000 - val_loss: 0.4464 - val_accuracy: 0.9057
Epoch 00038: val_accuracy did not improve from 0.90567
Epoch 39/100
163/163 [==============================] - 117s 720ms/step - loss: 3.7755e-04 - accuracy: 1.0000 - val_loss: 0.4455 - val_accuracy: 0.9057
Epoch 00039: val_accuracy did not improve from 0.90567
Epoch 40/100
163/163 [==============================] - 117s 721ms/step - loss: 3.4685e-04 - accuracy: 1.0000 - val_loss: 0.4446 - val_accuracy: 0.9062
Epoch 00040: val_accuracy improved from 0.90567 to 0.90625, saving model to ./output/Inception_2.h5
Epoch 41/100
163/163 [==============================] - 117s 719ms/step - loss: 3.1875e-04 - accuracy: 1.0000 - val_loss: 0.4438 - val_accuracy: 0.9062
Epoch 00041: val_accuracy did not improve from 0.90625
Epoch 42/100
163/163 [==============================] - 117s 722ms/step - loss: 2.9297e-04 - accuracy: 1.0000 - val_loss: 0.4430 - val_accuracy: 0.9074
Epoch 00042: val_accuracy improved from 0.90625 to 0.90741, saving model to ./output/Inception_2.h5
Epoch 43/100
163/163 [==============================] - 117s 720ms/step - loss: 2.6932e-04 - accuracy: 1.0000 - val_loss: 0.4423 - val_accuracy: 0.9080
Epoch 00043: val_accuracy improved from 0.90741 to 0.90799, saving model to ./output/Inception_2.h5
Epoch 44/100
163/163 [==============================] - 117s 720ms/step - loss: 2.4760e-04 - accuracy: 1.0000 - val_loss: 0.4416 - val_accuracy: 0.9080
Epoch 00044: val_accuracy did not improve from 0.90799
Epoch 45/100
163/163 [==============================] - 117s 721ms/step - loss: 2.2765e-04 - accuracy: 1.0000 - val_loss: 0.4408 - val_accuracy: 0.9080
Epoch 00045: val_accuracy did not improve from 0.90799
Epoch 46/100
163/163 [==============================] - 117s 720ms/step - loss: 2.0929e-04 - accuracy: 1.0000 - val_loss: 0.4401 - val_accuracy: 0.9080
Epoch 00046: val_accuracy did not improve from 0.90799
Epoch 47/100
163/163 [==============================] - 117s 720ms/step - loss: 1.9241e-04 - accuracy: 1.0000 - val_loss: 0.4394 - val_accuracy: 0.9080
Epoch 00047: val_accuracy did not improve from 0.90799
Epoch 48/100
163/163 [==============================] - 117s 717ms/step - loss: 1.7687e-04 - accuracy: 1.0000 - val_loss: 0.4387 - val_accuracy: 0.9080
Epoch 00048: val_accuracy did not improve from 0.90799
Epoch 00048: early stopping
训练可视化
loss = history.history['loss']
val_loss = history.history['val_loss']
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
epochs = range(1, len(acc) + 1)
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
单张图片做测试
from keras.preprocessing import image
img = image.load_img("./Clip_sample/126-73-type1.jpg", target_size=(512,512))
img = np.asarray(img)
plt.imshow(img)
img.shape
img = np.expand_dims(img, axis=0)
from keras.models import load_model
model = load_model("/content/drive/MyDrive/models/pre_model/Inception_1.h5")
output = model.predict(img)

predict = output[0]
print(np.max(predict))
index = np.where(predict==np.max(predict))[0][0]
print(index)
names = ['黑色煤', '灰黑色泥岩', '灰色泥质粉砂岩', '灰色细砂岩', '浅灰色细砂岩', '深灰色粉砂质泥岩', '深灰色泥岩']
print('我觉得这是一块' + names[index])
1.0
6
我觉得这是一块深灰色泥岩
!wget -O /usr/share/fonts/truetype/liberation/simhei.ttf "https://www.wfonts.com/download/data/2014/06/01/simhei/chinese.simhei.ttf"
import matplotlib.pyplot as plt
import matplotlib as mpl
zhfont = mpl.font_manager.FontProperties(fname='/usr/share/fonts/truetype/liberation/simhei.ttf')
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.figure(figsize=(12, 5), dpi=500)
plt.xlabel(u'岩石分类', fontproperties=zhfont)
plt.ylabel(u'预测置信度', fontproperties=zhfont)
plt.xticks(fontproperties=zhfont)
plt.bar(range(len(output[0])), output[0], tick_label=names)
plt.style.use('ggplot')

在测试集上进行评估
print("Evaluate on test data")
results = model.evaluate_generator(
generator=generateTestData(2, val_set),
max_queue_size=10
)
print("test loss, test acc:", results)
y_pred = np.argmax(predicts, axis=1)
y_true = np.argmax(test_label, axis=1)
len(y_pred), len(y_true)
打印混淆矩阵
# 打印混淆矩阵
from sklearn.metrics import confusion_matrix, classification_report
report = confusion_matrix(y_pred=y_pred, y_true=y_true)
plt.imshow(report, cmap=plt.cm.Blues)
plt.colorbar()
plt.xlabel('predict')
plt.ylabel('target')
for i in range(report.shape[0]):
for j in range(report.shape[1]):
plt.text(i, j, report[i][j])
















 512
512











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











