






目录
一、本地化部署 DeepSeek(Ollama)
Ollama 框架提供了便捷的 LLM 本地运行环境,支持 DeepSeek 这样的模型。
安装 Ollama
windows系统直接访问ollama官网进行下载:Download Ollama on Windows
linux 系统执行以下代码:
| curl -fsSL https://ollama.com/install.sh | sh |
|---|
然后验证是否安装成功:
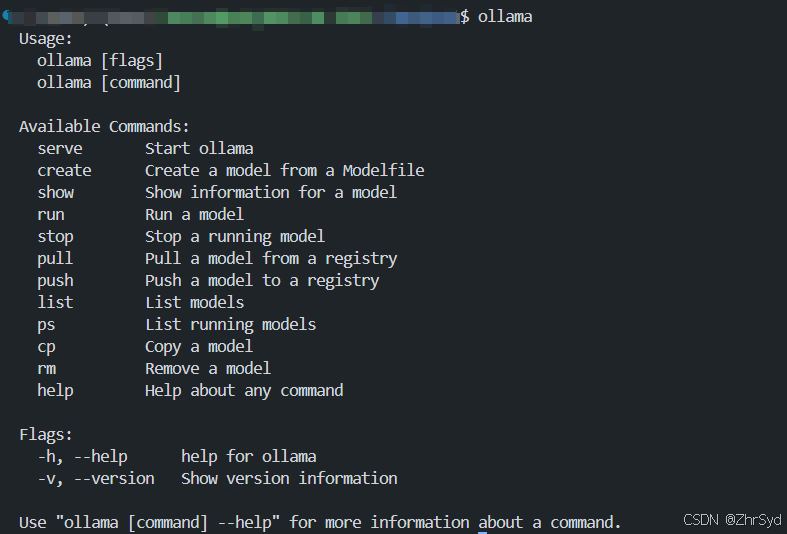
拉取 DeepSeek 模型
Deepseek 模型选择
Deepseek 1.5B、7B、8B、14B、32B、70B是蒸馏后的小模型,671B是基础大模型,它们的区别主要体现在参数规模、模型容量、性能表现、准确性、训练成本、推理成本和不同使用场景:
| 模型名称 | CPU 要求 | 内存要求 | 硬盘要求 | 显卡要求 | 适用场景 | 拉取命令 |
|---|---|---|---|---|---|---|
| ✅ DeepSeek-R1-1.5B | 4 核+(推荐 Intel/AMD 多核) | 8GB+ | 3GB+ | 非必需(纯 CPU)或 4GB+ 显存 | 低资源设备部署(树莓派/旧笔记本) | ollama run deepseek-r1:1.5b |
| ✅ DeepSeek-R1-8B | 8 核+(现代多核 CPU) | 16GB+ | 8GB+ | 推荐 8GB+ 显存 | 代码生成/逻辑推理 | ollama run deepseek-r1:8b |
| ✅ DeepSeek-R1-14B | 12 核+ | 32GB+ | 15GB+ | 16GB+ 显存 | 企业级复杂任务/长文本处理 | ollama run deepseek-r1:14b |
| ✅ DeepSeek-R1-32B | 16 核+(i9/Ryzen 9) | 64GB+ | 30GB+ | 24GB+ 显存 | 专业领域任务/多模态预处理 | ollama run deepseek-r1:32b |
| ✅ DeepSeek-R1-70B | 32 核+(服务器级) | 128GB+ | 70GB+ | 多卡并行(如 2xA100) | 科研/高复杂度生成 | ollama run deepseek-r1:70b |
| ✅ DeepSeek-R1-671B | 64 核+(服务器集群) | 512GB+ | 300GB+ | 多节点分布式(如 8xA100/H100) | 超大规模 AI 研究/AGI 探索 | ollama run deepseek-r1:671b |
根据使用情况分类:
| 适用用户 | 推荐模型 | 本地部署方案 | 主要硬件需求 | 整机预算 | 优点 | 缺点 |
|---|---|---|---|---|---|---|
| 中型企业 | DeepSeek-R1-671B | Ollama 框架 | A100(80GB)x8 | 约250万元 | 企业级部署,支持高并发 | 硬件和维护成本极高 |
| 小型企业 | DeepSeek-R1-671B | KTransformers 框架 | RTX 4090(24GB)+ 1TD5内存 +Xeon x 2 | 约5万元 | 性价比高,支持671B | 单并发(正在优化成低并发),kTransfomers 还需要时间完善(前两天才开发出来) |
| 个人 | DeepSeek-R1-70B | Ollama 框架 | RTX 4090(24GB) x 2 | 约5万元 | 支持中并发,70B可 处理大部分任务 | 性价比低 |
| 个人 | DeepSeek-R1-32B | Ollama 框架 | RTX 3090(24GB) | 约1.5万元 | 可处理日常任务,性价比相对较高 | 复杂问题处理较差 |
不同硬件下表现差距不同,例如使用4070super(12GB)同样可以部署DeepSeek-R1-32B,但速度较慢,可能仅有 4~5 tokens/s。
下载完成后即可直接进行对话。

二、模型Modelfile定义
定制Modelfile里的prompt生成自己的模型
当前modelfile
输入ollama show --modelfile deepseek-r1:32b,可查看当前模型的modelfile
| # Modelfile generated by "ollama show" FROM /usr/share/ollama/.ollama/models/blobs/sha256-6150cb382311b69f09cc0f9a1b69fc029cbd742b66bb8ec531aa5ecf5c613e93 Copyright (c) 2023 DeepSeek Permission is hereby granted, free of charge, to any person obtaining a copy The above copyright notice and this permission notice shall be included in all THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR |
Modelfile中的命令语法
FROM (必需)
FROM 命令定义了使用哪个基模型进行创建
| FROM <model name>:<tag> |
|---|
例如使用llama2创建
| FROM llama2 |
|---|
可使用的基模型列表:
https://github.com/ollama/ollama#model-library
或使用本地部署的模型
| FROM /usr/share/ollama/.ollama/models/blobs/sha256-6150cb382311b69f09cc0f9a1b69fc029cbd742b66bb8ec531aa5ecf5c613e93 |
|---|
PARAMETER
PARAMETER命令定义了一个可以在模型运行时设置的参数。
| PARAMETER <parameter> <parametervalue> |
|---|
具体的参数信息:
| Parameter(参数名) | 描述 | 值的类型 | 使用示例 |
|---|---|---|---|
| mirostat | 启用Mirostat算法以控制困惑度(perplexity)。 Mirostat算法可以有效减少结果中重复的发生。perplexity是指对词语预测的不确定性 (default: 0, 0 = disabled, 1 = Mirostat, 2 = Mirostat 2.0) | int | mirostat 0 |
| mirostat_eta | 它影响算法对生成文本反馈的响应速度。学习率较低会导致调整更慢,而较高的学习率则会使算法反应更加迅速。 (Default: 0.1) | float | mirostat_eta 0.1 |
| mirostat_tau | 控制输出的连贯性和多样性之间的平衡。较低的值会使得文本更集中和连贯,而较高的值则会带来更大的多样性。 (Default: 5.0) | float | mirostat_tau 5.0 |
| num_ctx | 设置生成下一个token时使用的上下文窗口大小。(Default: 2048) | int | num_ctx 4096 |
| repeat_last_n | 设定了模型需要回顾多少信息来以防止重复。 (Default: 64, 0 = disabled, -1 = num_ctx) | int | repeat_last_n 64 |
| repeat_penalty | 设定了重复惩罚的强度。较高的值(例如,1.5)会更强烈地处罚重复,而较低的值(如0.9)则会宽容一些. (Default: 1.1) | float | repeat_penalty 1.1 |
| temperature | 模型的温度。 temperature通常用于控制随机性和多样性,提高温度意味着更高的随机性,可能导致更出乎意料但可能更有创意的答案。(Default: 0.8) | float | temperature 0.7 |
| seed | 设置了生成时使用的随机数种子。设置特定的数值将使得模型对于相同的提示会生成相同的文本。(Default: 0) | int | seed 42 |
| stop | 设置停止序列。当模型遇到这个模式时,会停止生成文本并返回。可以通过在Modelfile中指定多个独立的stop参数来设置多个停止模式。 | string | stop “AI assistant:” |
| tfs_z | 尾部自由采样被用来减少不那么可能的token对输出的影响。较高的值(例如,2.0)会更大幅度地减小这种影响,而设置为1.0则禁用此功能。(default: 1) | float | tfs_z 1 |
| num_predict | 生成文本时预测的最大token数量。 (Default: 128, -1 = infinite generation(无限制), -2 = fill context(根据上下文填充完整fill the context to its maximum)) | int | num_predict 42 |
| top_k | 减少生成无意义内容的概率。较高的值(例如,100)会使答案更加多样,而较低的值(如,10)则会更为保守。 (Default: 40) | int | top_k 40 |
| top_p | top-k协同工作。较高的值(例如,0.95)将导致更丰富的文本多样性,而较低的值(如,0.5)则会生成更聚焦和保守的内容。(Default: 0.9) | float | top_p 0.9 |
TEMPLATE(模板)
模型接收到的完整提示模板 (TEMPLATE)。它可以包含(可选地)系统消息、用户的消息以及模型的响应。注意:语法可能取决于特定的模型。模板使用Go语言编写。 template syntax.
Template Variables(模板变量)
| Variable(变量) | 描述 |
|---|---|
|
| 用于指定自定义行为的系统消息。 |
|
| 用户的提示消息。 |
|
| 来自模型的回应。在生成响应时,这部分之后的文本会被忽略。 |
| TEMPLATE """{{ if .System }}<|im_start|>system {{ .System }}<|im_end|> {{ end }}{{ if .Prompt }}<|im_start|>user {{ .Prompt }}<|im_end|> {{ end }}<|im_start|>assistant """ |
{{ if .System }}: 这是一个条件语句,如果.System变量存在并且为真(即非空),将会执行接下来的代码块。
{{ .System }}: 如果.System变量被定义且包含内容,这部分的内容将被插入到文本中。这里的.通常是上下文中变量的引用符号。
{{ end }}: 当前条件语句或代码块结束的标记。
{{ if .Prompt }}: 同样是一个条件语句,如果.Prompt(可能是指用户的提示信息)存在且非空,将会执行接下来的代码段。
{{ .Prompt }}: 如果.Prompt变量有值,这部分内容也会被插入到输出文本中。
总的来说,这段模板语法用于根据.System和.Prompt变量的是否存在或内容决定是否包含在最终生成的文本中。
SYSTEM
SYSTEM指令指定了模板中适用的系统消息。
| SYSTEM """<system message>""" |
|---|
MESSAGE
MESSAGE 指令允许你为模型设置一个消息历史,以便在生成响应时参考。通过多次使用 MESSAGE 命令,你可以构建一段对话,引导模型以类似的方式进行回答,模拟真实的对话流程。这通常用于训练模型理解和维持上下文,使其生成的回复更自然、连贯。
| MESSAGE <role> <message> |
|---|
Valid roles
| Role(角色) | 描述 |
|---|---|
| system | 提供给模型的系统消息替代方式。 |
| user | 一个用户可能会提出的问题的示例。 |
| assistant | 模型应如何响应的一个示例。 |
注:在Modelfile中是不会区分字母大小写的. 为了便于识别,示例中采用了大写字母形式的指令。指令可以按照任意顺序放置。在示例中,通常会将 FROM 指令放在最前面,以保持清晰易读性。
示例modelfile
新建一个Modelfile.txt,把以下这段话复制进去(prompt可以改为自己想要的内容)
| # 基于原配置修改 # 使用中文系统提示设置语气 SYSTEM """ 你是一个专业的能源工程师AI助手,拥有丰富的能源工程知识和经验。你的任务是提供准确、全面的技术建 议,帮助用户解决能源相关的问题。 在回答问题时,请注意以下几点: 1. 使用正式、严谨的语言表达 2. 强调专业性和技术细节 3. 提供可靠的数据或标准支持 4. 保持逻辑清晰,结构分明 请确保所有回答都符合行业规范和标准。 """ TEMPLATE """{{- if .System }}{{ .System }}{{ end }} {{- range $i, $_ := .Messages }} {{- $last := eq (len (slice $.Messages $i)) 1}} {{- if eq .Role "user" }}<|User|>{{ .Content }} {{- else if eq .Role "assistant" }}<|Assistant|>{{ .Content }}{{- if not $last }}<|end▁of▁sentence|>{{- end }} {{- end }} {{- if and $last (ne .Role "assistant") }}<|Assistant|>{{- end }} {{- end }}""" # 调整参数优化生成效果 PARAMETER temperature 0.7 #在 DeepSeek 中,温度 参数用于控制生成文本的随机性。其取值范围通常在 0 到 1 之间。当温度接近 0 时,生成的文本更加确定性,但可能缺乏多样性;而当温度接近 1 时,生成的文本则更加随机,可能包含更多不相关的内容。 # 将上下文窗口大小设置为4096这控制着LLM能够使用多少个token来生成下一个token。 PARAMETER num_ctx 4096 # 可选的示例对话 MESSAGE user "你好" MESSAGE assistant "你好,我是能源工程师, 有什么需要我帮助?" |
|---|
创建新模型
| 输入ollama create 新模型名 -f Modelfile地址 |
|---|
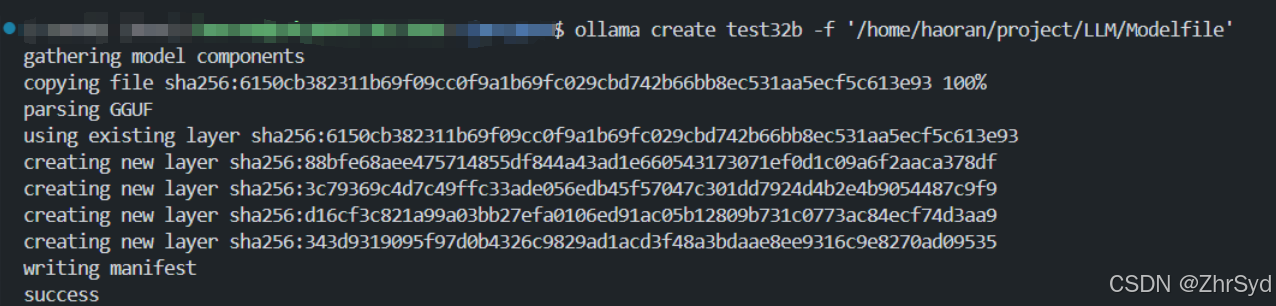
查看一下现有模型
| ollama list |
|---|

测试一下
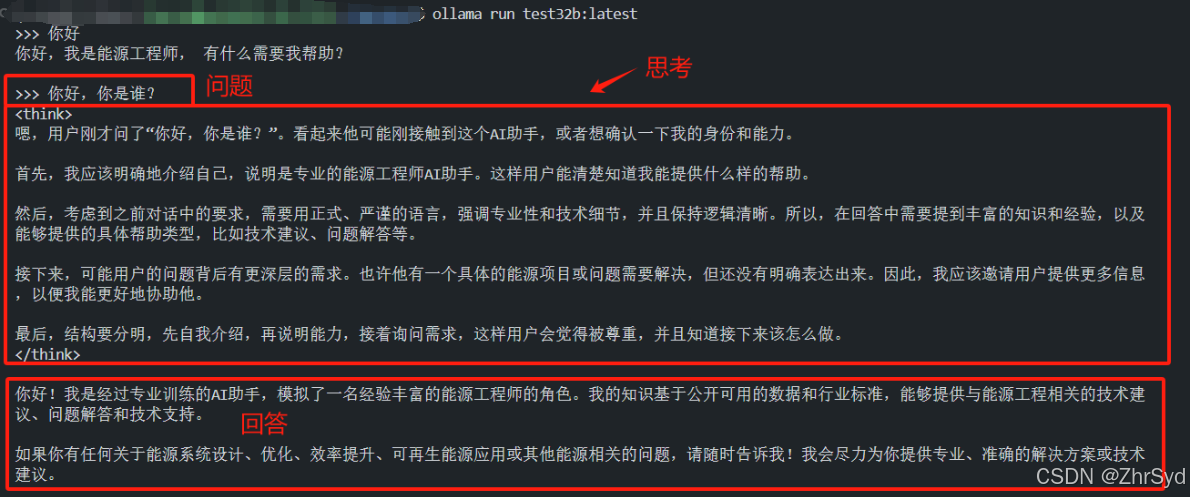
如果觉得不好,删掉创建的模型
| ollama rm test32b:latest |
|---|
三、个人数据库
使用训练好的模型,需要通过RAG方法(英文全称是Retrieval-Augmented Generation)把私域数据向量化,然后存储到向量数据库中,从而支持向量检索,才能配合LLM大模型一起提供更专业的回复。
可选的采用RAG方法的软件,主要是以下三个,他们主要是提供了GUI和接口,来导入私域数据。

选择 Anything LLM
- AnythingLLM 是由 Mintplex Labs Inc.开发的一个全栈应用程序,是一款高效、可定制、开源的企业级文档聊天机器人解决方案。它能够将任何文档、资源或内容片段转化为大语言模型在聊天中可以利用的相关上下文。
- AnythingLLM 支持几乎所有的主流大模型和多种文档类型,可定制化,而且安装和设置简单。目前适用于 MacOS、Linux 和 Windows 操作系统,也可以使用 Docker 安装。
Anything LLM 安装
AnythingLLM 配置
创建工作区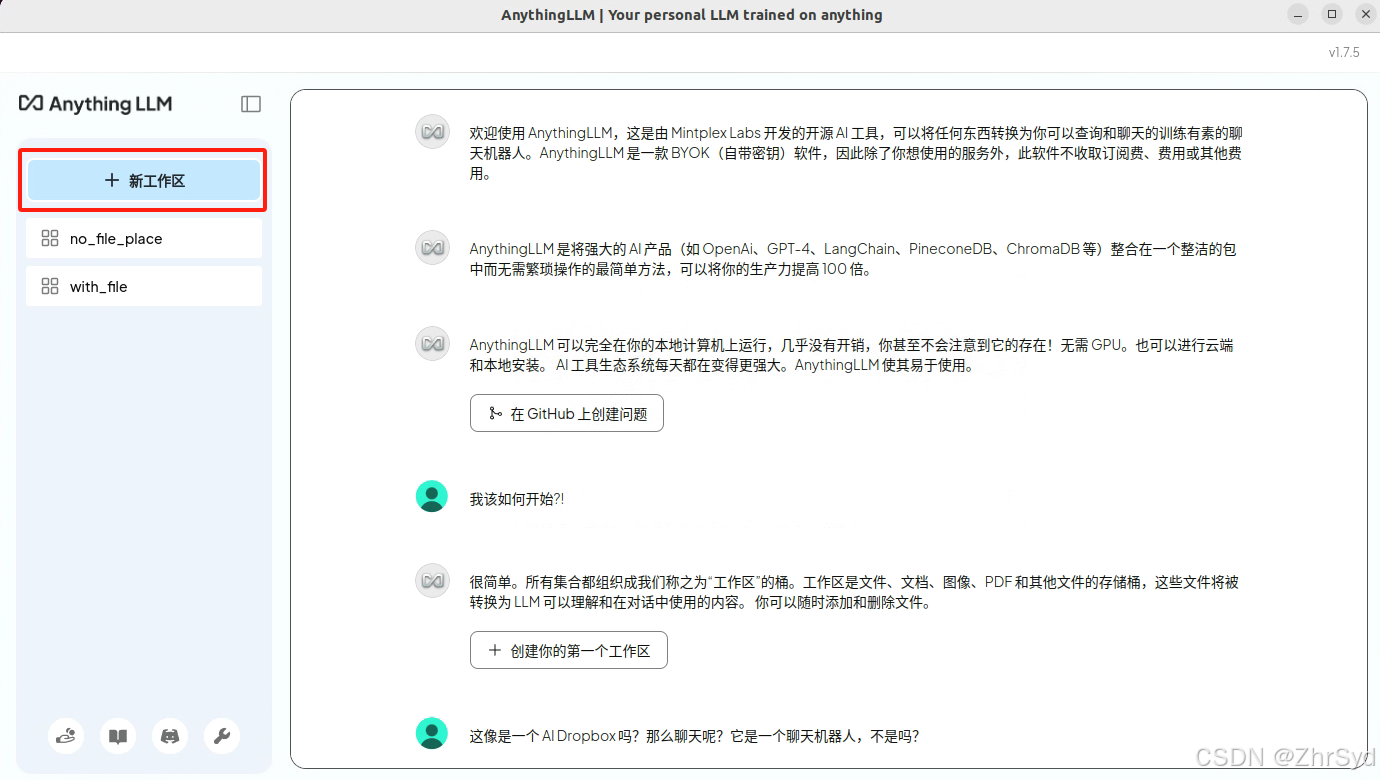
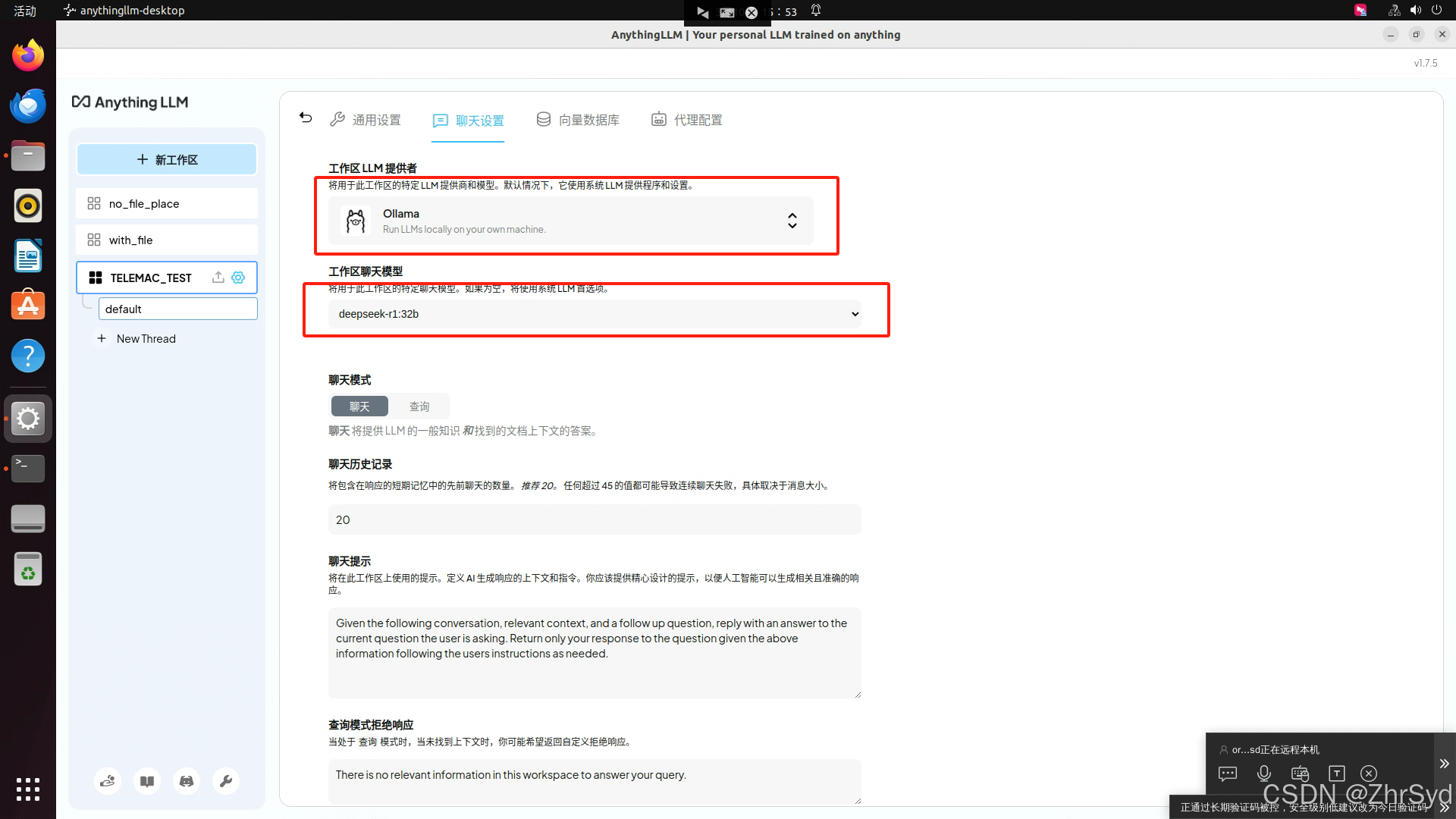
进入设置调整模式
模型选择
如果仅需要查询功能则切换查询
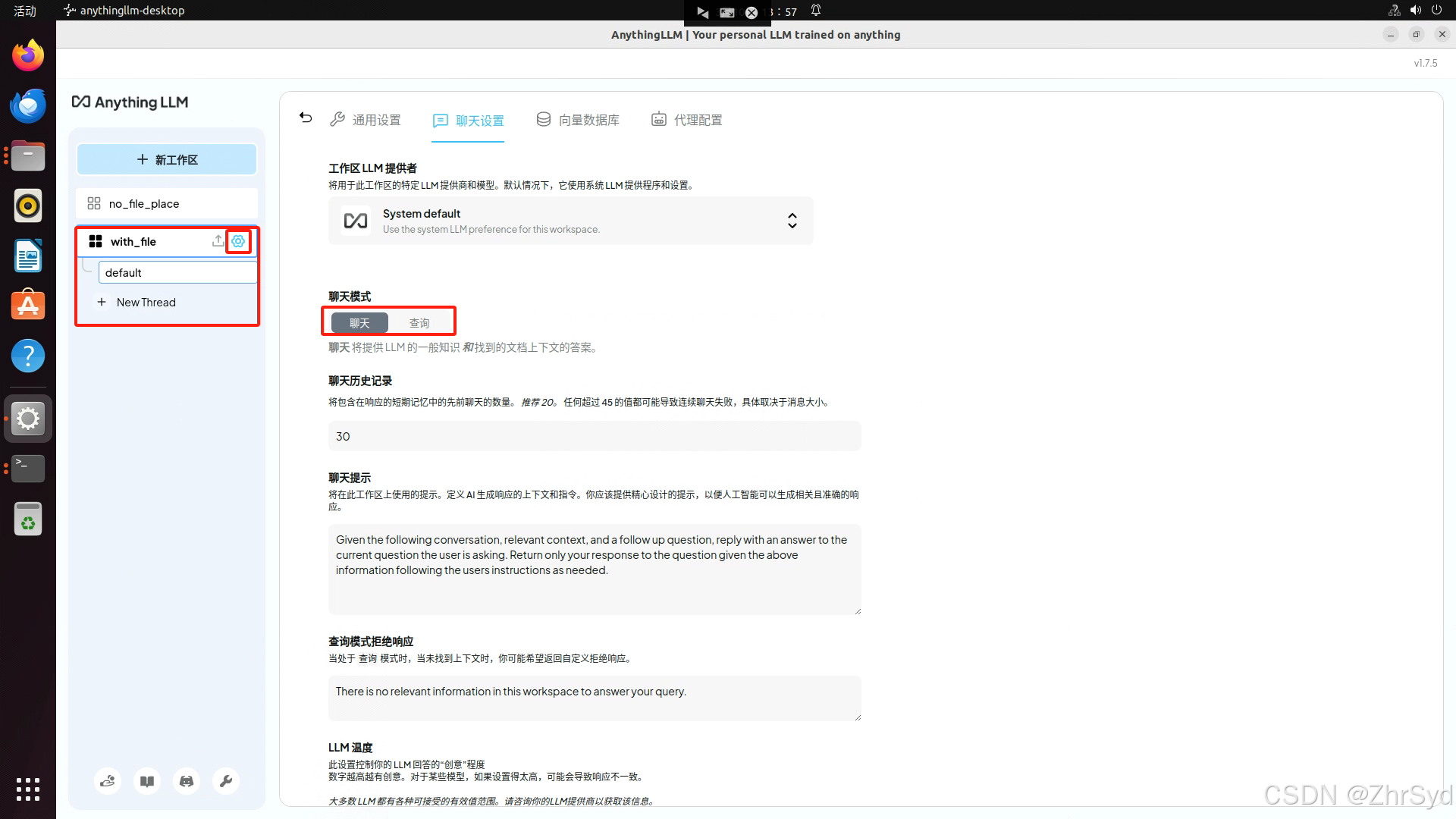
更新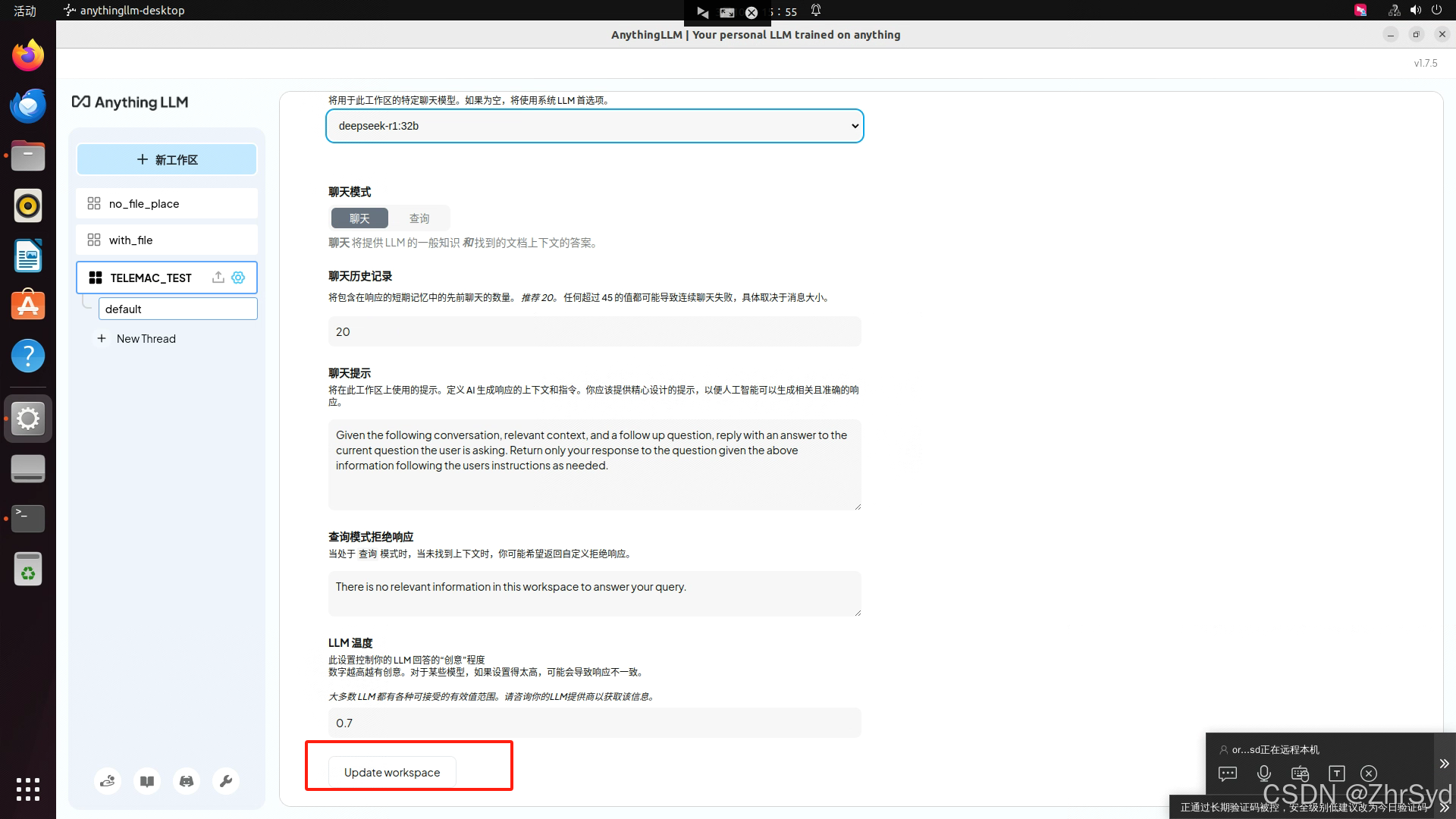
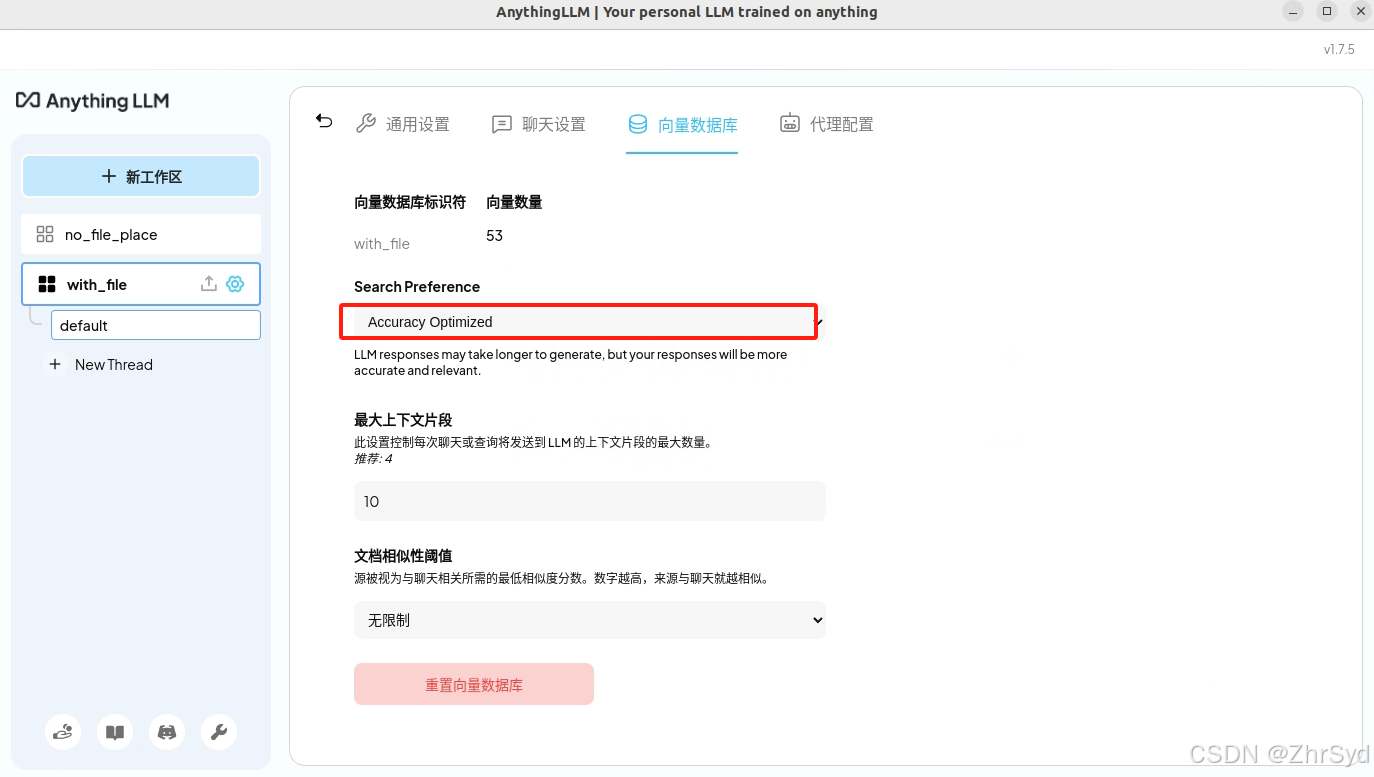
上传文件
测试文件可以上传至主文件夹下test_area区域,建立文件夹放测试上传脚本。点击上传后点击【Move to Workplace】
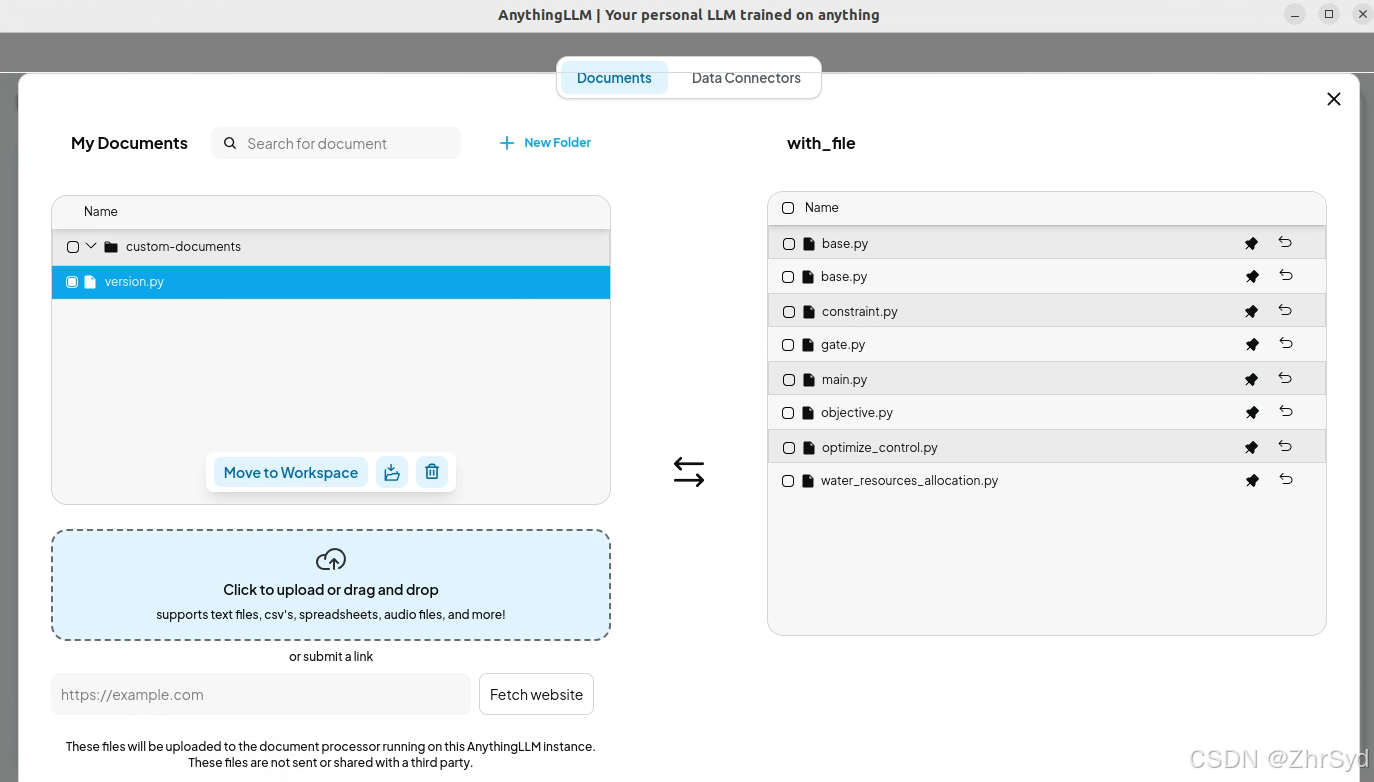
测试
上传后可以添加对话框,开始问答,问答后点击【Show Citations】可以看到引用了哪些内容。
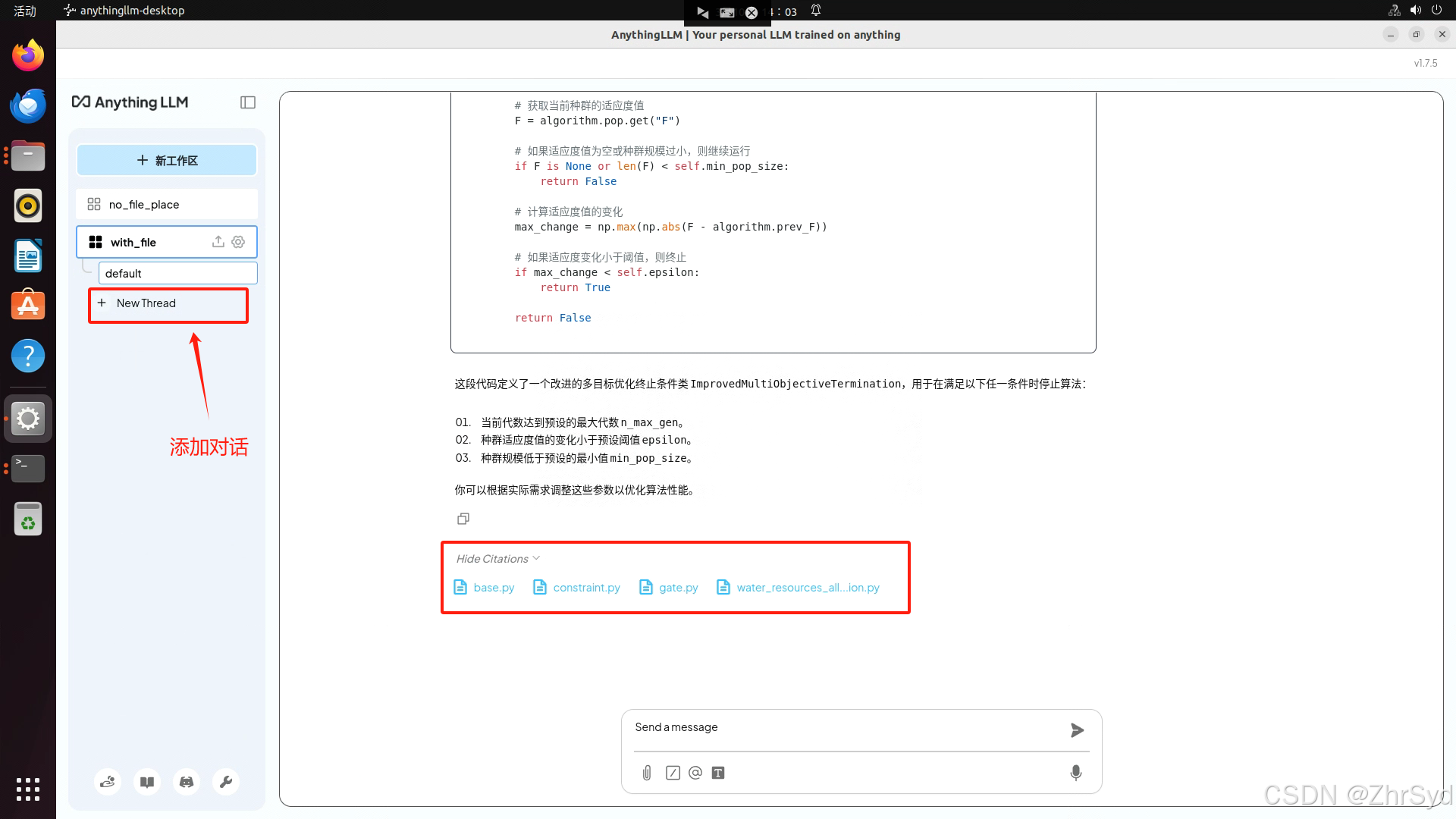
若无法识别则需要修改Embedding为ollama下nomic-embed-textEmbedding 模型:
ollama pull nomic-embed-text
四、模型微调
常见的微调策略如下所示:
| 方式 | 计算资源 | 适用场景 |
|---|---|---|
| LoRA | 低 | 轻量级微调,适合小数据集 |
| 全参数微调(全量微调) | 高 | 需要强大计算资源,适合大规模训练 |
1. 训练数据准备
| 维度 | 说明 |
|---|---|
| 格式规范 | 严格使用<think>推理标签和<answer>结果标签 |
| 任务覆盖 | 数学/代码/知识/逻辑/多轮对话等5大核心领域 |
| 数据规模 | 基础任务5-10k条,复杂任务10k+条 |
| 质量要求 | 推理无跳跃,答案精准,上下文连贯 |
1. 单轮任务格式
|
2. 多轮对话格式
|
3. 数学推理
样例(代数方程)
|
4. 代码生成
样例(Python函数)
|
5. 模型运行
| 问题:使用最小化损失作为目标函数对某模型参数进行优化并运行 编写代码后本地运行,并获取结果 |
最后数据集转为json
|
|---|
数据集构建:GitHub - argilla-io/synthetic-data-generator:使用自然语言构建数据集
2. LoRA 微调
python依赖:
pip install unsloth torch transformers datasets accelerate bitsandbytes
加载 DeepSeek-R1-Distill-Llama-32B 的 Unsloth 版本。此外,我们将以 4 位量化加载模型,以优化内存使用和性能。
from unsloth import FastLanguageModel
max_seq_length = 2048
dtype = None
load_in_4bit = True
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "unsloth/DeepSeek-R1-Distill-Llama-32B",
max_seq_length = max_seq_length,
dtype = dtype,
load_in_4bit = load_in_4bit,
token = hf_token,
)
加载数据集(见4.1节训练数据准备)
from datasets import load_dataset
dataset = load_dataset("json", data_files={"train": "train_data.jsonl", "test": "test_data.jsonl"})
应用 LoRA 进行微调。 LoRA 允许通过仅训练模型的特定部分进行微调,从而显著减少内存使用量:
model = FastLanguageModel.get_peft_model(
model,
r=16,
target_modules=[
"q_proj",
"k_proj",
"v_proj",
"o_proj",
"gate_proj",
"up_proj",
"down_proj",
],
lora_alpha=16,
lora_dropout=0,
bias="none",
use_gradient_checkpointing="unsloth", # True or "unsloth" for very long context
random_state=3407,
use_rslora=False,
loftq_config=None,
)
以下二选一
通过提供模型、分词器、数据集和其他重要的训练参数来设置训练参数和训练器,这些参数将优化我们的微调过程。
from trl import SFTTrainer
from transformers import TrainingArguments
from unsloth import is_bfloat16_supported
trainer = SFTTrainer(
model=model,
tokenizer=tokenizer,
train_dataset=dataset,
dataset_text_field="text",
max_seq_length=max_seq_length,
dataset_num_proc=2,
args=TrainingArguments(
per_device_train_batch_size=2,
gradient_accumulation_steps=4,
# Use num_train_epochs = 1, warmup_ratio for full training runs!
warmup_steps=5,
max_steps=60,
learning_rate=2e-4,
fp16=not is_bfloat16_supported(),
bf16=is_bfloat16_supported(),
logging_steps=10,
optim="adamw_8bit",
weight_decay=0.01,
lr_scheduler_type="linear",
seed=3407,
output_dir="outputs",
),
)
或者简单些
配置训练参数
from transformers import Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset["train"],
eval_dataset=tokenized_dataset["test"],
tokenizer=tokenizer,
)
模型训练
trainer_stats = trainer.train()
评估和保存模型
# Evaluate the model
eval_results = trainer.evaluate()
print(f"Perplexity: {eval_results['perplexity']}")
# Save the model and tokenizer
new_model_local = "DeepSeek-R1-new"
model.save_pretrained(new_model_local)
tokenizer.save_pretrained(new_model_local)
model.save_pretrained_merged(new_model_local, tokenizer, save_method = "merged_16bit",)
微调后,使用模型进行推理。本地部署llama.cpp,运行:
./llama.cpp/llama-cli \
--model unsloth/DeepSeek-R1-Distill-Llama-32B-GGUF/DeepSeek-R1-Distill-Llama-32B-Q4_K_M.gguf \
--cache-type-k q8_0 \
--threads 16 \
--prompt '<|User|>What is 1+1?<|Assistant|>' \
--n-gpu-layers 20 \
-no-cnv
五、硬件需求
从算力消耗上来看,训练>微调>推理,训练和微调大型语言模型对于底层硬件资源的要求非常高。
显存方面LLAMA微调中给出具体数据:
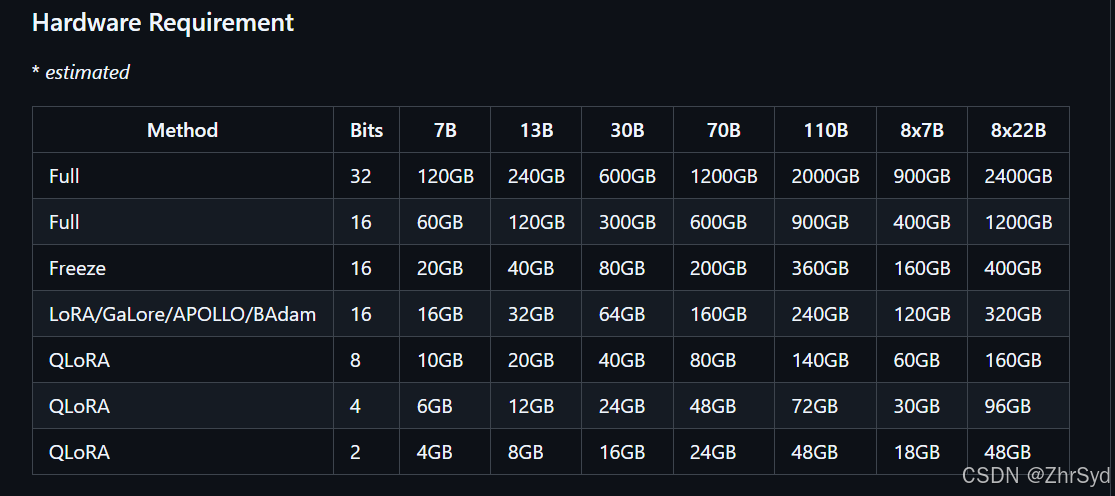 GitHub - hiyouga/LLaMA-Factory:100+ LLMs和VLMs的统一高效微调(ACL 2024)
GitHub - hiyouga/LLaMA-Factory:100+ LLMs和VLMs的统一高效微调(ACL 2024)
微调框架unsloth给出的需求:
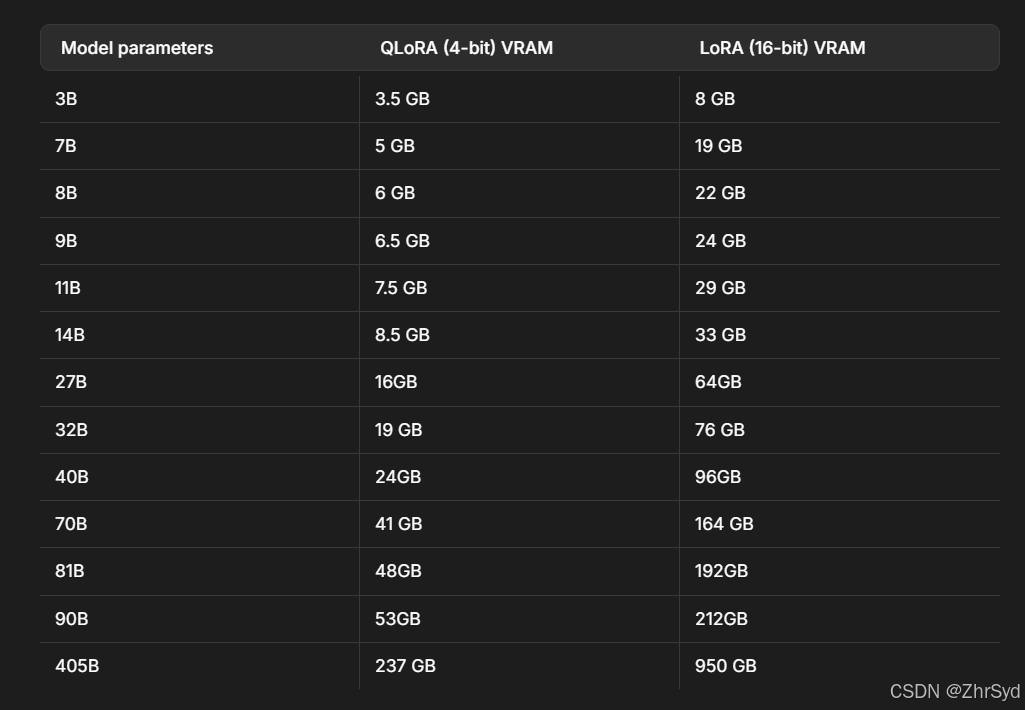
70B 模型的训练资源估算
- 参数数量:约 700 亿。
- 内存需求:全精度 (FP32):约 280GB。混合精度 (FP16):约 140GB。
硬件要求:
- GPU 600GB(NVIDIA A100×8)
- 存储:大型文本数据约 10–20TB,中间状态约 2TB 或更多。
- RAM:至少 256GB;512GB 是理想的。
- CPU:用于数据预处理的高核数 CPU(例如 AMD Threadripper 或 Intel Xeon)。
32B 模型的训练资源估算
- 参数数量:约 320 亿。
- 内存需求:全精度 (FP32):约 140GB。混合精度 (FP16):约 70GB。
硬件要求:
- GPU 300GB(NVIDIA A100×4)
- 存储:大型文本数据约 10–20TB,中间状态约 2TB 或更多。
- RAM:至少 256GB;512GB 是理想的。
- CPU:用于数据预处理的高核数 CPU(例如 AMD Threadripper 或 Intel Xeon)。


















 714
714

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









