







论文题目(Title):Multi-Modal Sarcasm Detection via Cross-Modal Graph Convolutional Network
研究问题(Question):反讽检测

研究动机(Motivation):纯文本描述可能错误地表达真实情况。
主要贡献(Contribution):
1.作者指出自己是第一个探索使用基于辅助对象检测的图模型来建模多模态讽刺检测中关键文本和视觉信息之间的矛盾情绪。
2.利用图像对象的属性-对象对作为桥梁,提出了一种新的构建交叉模态图的方法,通过重要程度不同的边显式连接两个模态
3.在一个公开的多模态讽刺检测基准数据集上的一系列实验表明,作者提出的方法达到了最先进的性能。
研究思路(Idea):首先检测与图像模态描述配对的对象,使学习重要的视觉信息成为可能。然后,通过对对象的描述作为桥梁,确定图像情态对象与文本情态语境词之间关联的重要性,为每个多情态实例构建跨模态图。此外,作者设计了一个跨模态图卷积网络,以理解多模态讽刺检测中模态之间的不一致性关系。
研究方法(Method):
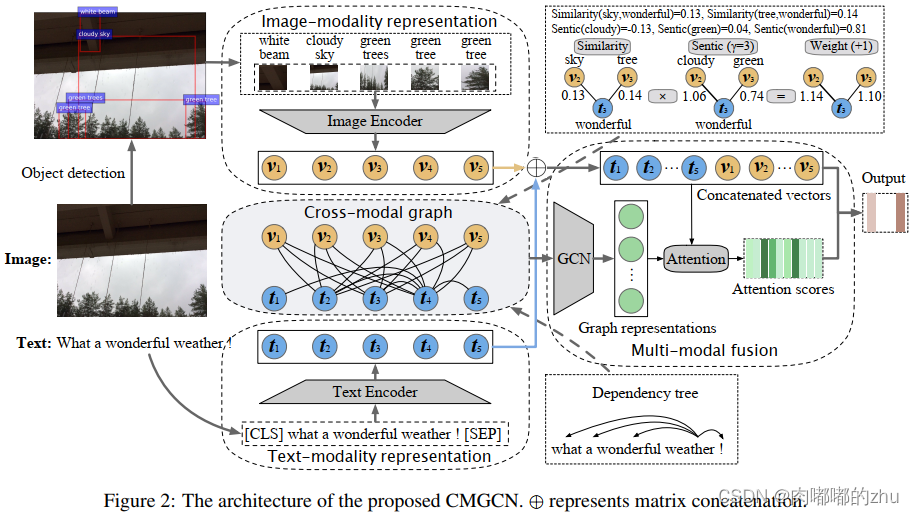
研究过程(Process):
(1)Text-modality表示
(2)Image-modality表示
(3)建立跨通道图
(4)跨模态融合
(5)学习目标
1.数据集(Dataset)

2.评估指标(Evaluation)
准确度(ACC)、F1-score、Macro-average
3.实验结果(Result)
证明了该方法是目前效果最好的方法,通过消融实验,验证了各个参数设置。
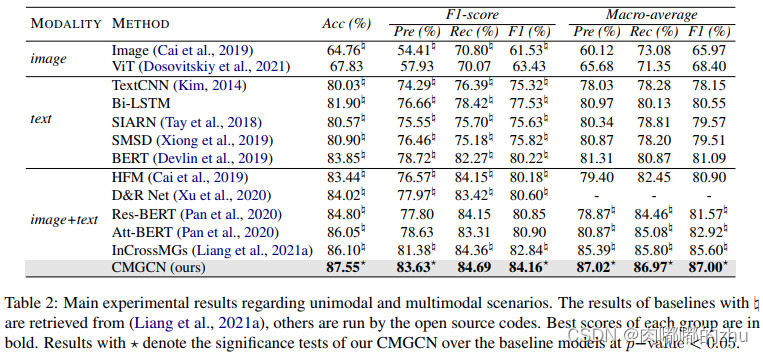
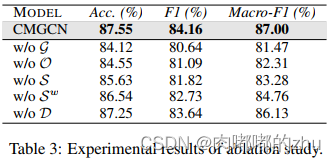
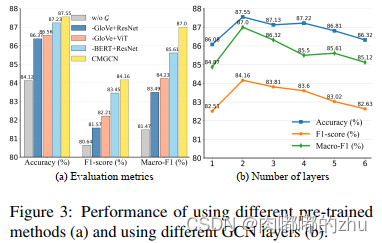

总结(Conclusion):本文提出了一种新的多模态讽刺检测的跨模态图结构,该结构将关键的视觉区域显式连接到高度相关的文本标记,用于学习讽刺表达的不一致情绪。















 3201
3201











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









