







时间:
C++引入的时间标准库:std::chrono
时间点类型:chrono::steady_clock::time_point 等
时间段类型:chrono::milliseconds,chrono::seconds,chrono::minutes 等
方便的运算符重载:时间点+时间段=时间点,时间点-时间点=时间段
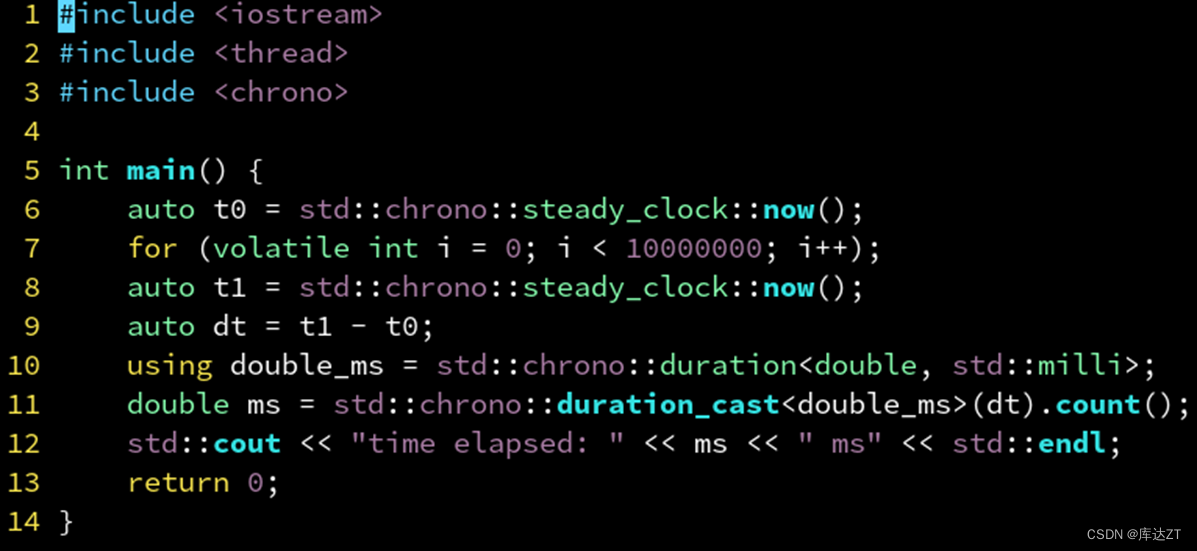
auto t0 = chrono::steady_clock::now(); // 获取当前时间点
auto t1 = t0 + chrono::seconds(30); // 当前时间点的30秒后
auto dt = t1 - t0; // 获取两个时间点的差(时间段)
int64_t sec = chrono::duration_cast<chrono::seconds>(dt).count(); // 时间差的秒数时间段也可以以double为返回类型:
duration_cast 可以在任意的 duration 类型之间转换
duration<T, R> 表示用 T 类型表示,且时间单位是 R
R 省略不写就是秒,std::milli 就是毫秒,std::micro 就是微秒
seconds 是 duration<int64_t> 的类型别名
milliseconds 是 duration<int64_t, std::milli> 的类型别名
这里我们创建了 double_ms 作为 duration<double, std::milli> 的别名
sleep_for :睡一个时间段
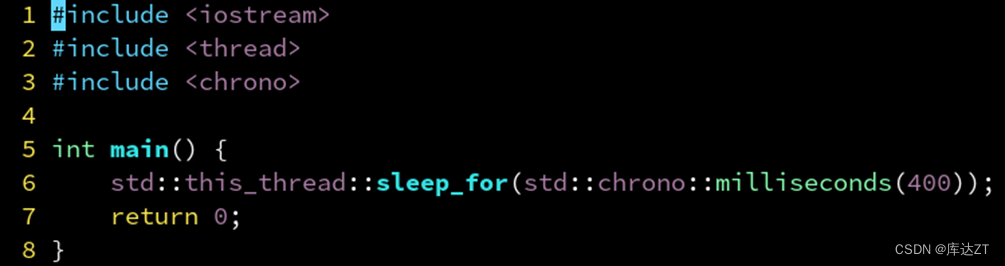
milliseconds 表示毫秒,也可以换成 microseconds 表示微秒,seconds 表示秒
sleep_until:睡到时间点

以上这二者是等价的。
进程和线程:
在C++中,设立了std::thread
#include <iostream>
#include <thread>
#include <string>
void download(std::string file) {
for (int i = 0; i < 10; i++) {
std::cout << "Downloading " << file
<< " (" << i * 10 << "%)..." << std::endl;
std::this_thread::sleep_for(std::chrono::milliseconds(400));
}
std::cout << "Download complete: " << file << std::endl;
}
void interact() {
std::string name;
std::cin >> name;
std::cout << "Hi, " << name << std::endl;
}
int main() {
std::thread t1([&] {
download("hello.zip");
});
interact();
std::cout << "Waiting for child thread..." << std::endl;
t1.join();//设立同步点
std::cout << "Child thread exited!" << std::endl;
return 0;
} 
在这里就可以看到,我输入whs是一起输入的,当他识别到了我再输入之后跟我打了个招呼,之后就告诉我要等待子线程的执行。
而我们知道,thread是满足RAII思想和三五法则的,所以他自定义了解构函数,删除了拷贝构造/赋值函数,但是提供了移动构造/赋值函数。
因此,当 t1 所在的函数退出时,就会调用 std::thread 的解构函数,这会销毁 t1 线程。所以,download 函数才会出师未捷身先死——还没开始执行他的线程就被销毁了
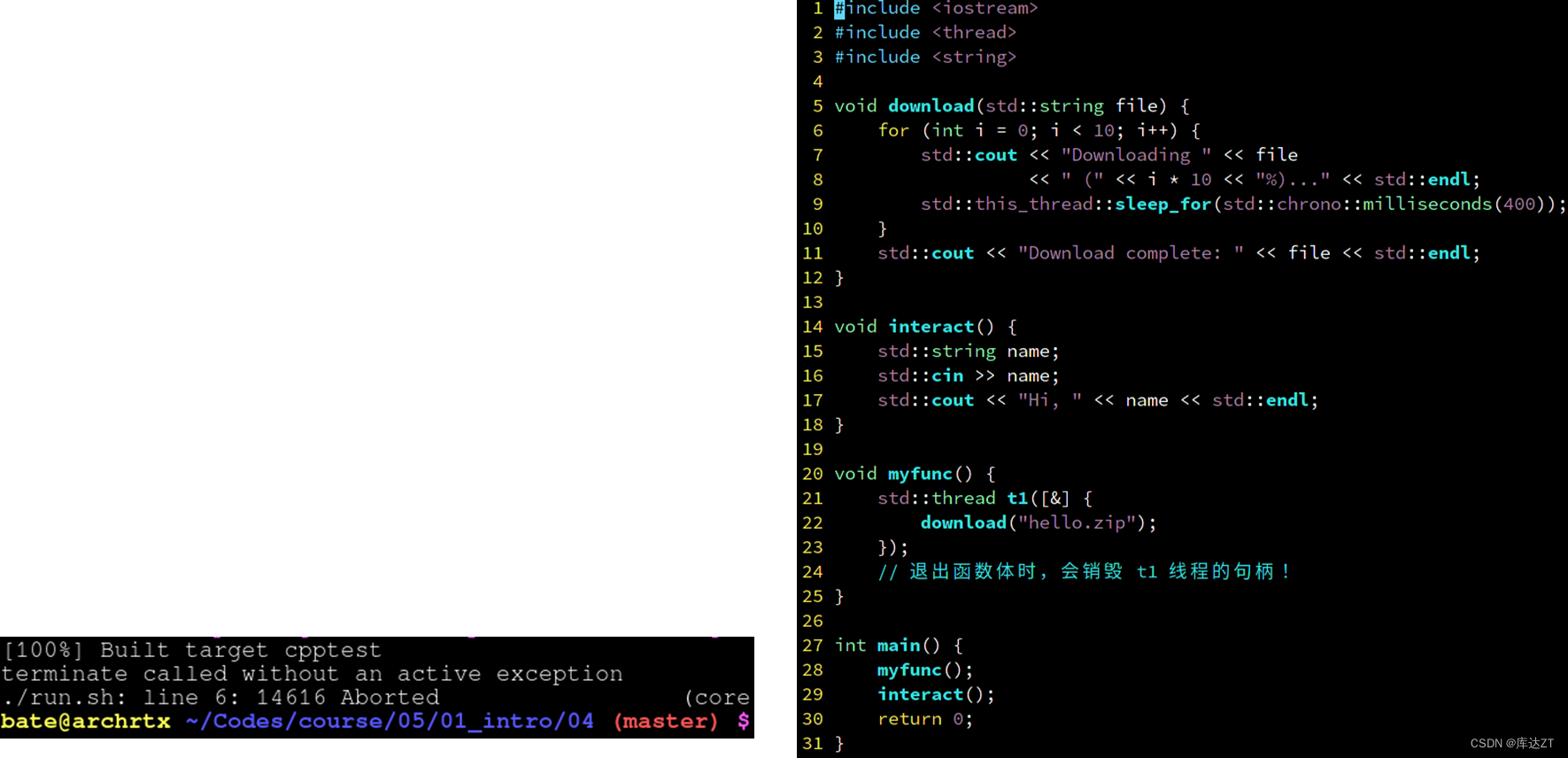
为了解决这种事情,可以用t1.detach()分离该对象与线程,这意味着当前现成的生命周期不由thread对象管理。

但这样还是有问题,可以看到在上面的ppt中,虽然线程完美的退出了,但下载也退出了没有完成。
为了解决这种问题,可以创立一个全局的线程池:
#include <iostream>
#include <thread>
#include <string>
#include <vector>
std::vector<std::thread> pool;
void download(std::string file) {
for (int i = 0; i < 10; i++) {
std::cout << "Downloading " << file
<< " (" << i * 10 << "%)..." << std::endl;
std::this_thread::sleep_for(std::chrono::milliseconds(400));
}
std::cout << "Download complete: " << file << std::endl;
}
void interact() {
std::string name;
std::cin >> name;
std::cout << "Hi, " << name << std::endl;
}
void myfunc() {
std::thread t1([&] {
download("hello.zip");
});
pool.push_back(std::move(t1));
}
int main() {
myfunc();
interact();
for (auto& t : pool) t.join();
return 0;
}通过这种创立全局线程池的方式,我们就可以在全局操纵每个线程,就是将生存周期变得和main函数一样长。在之后将pool中的每个线程都同步就可以了。
但这样的话还是要在mian函数中修改,所以很麻烦。可以构建一个类,结构函数就是自动同步。
class ThreadPool
{
std::vector<std::thread> pool;
public:
void push_back(std::thread t) {
pool.push_back(std::move(t));
};
~ThreadPool() {
for (auto& t : pool) t.join();
};
};
ThreadPool thrp;
void myfunc() {
std::thread t1([&] {
download("hello.zip");
});
thrp.push_back(std::move(t1));
}
这样在析构的时候就自动制定了同步join()。
异步:
std::aysnc
#include <iostream>
#include <thread>
#include <string>
#include <vector>
#include <future>
int download(std::string file) {
for (int i = 0; i < 10; i++) {
std::cout << "Downloading " << file
<< " (" << i * 10 << "%)..." << std::endl;
std::this_thread::sleep_for(std::chrono::milliseconds(400));
}
std::cout << "Download complete: " << file << std::endl;
return 404;
}
void interact() {
std::string name;
std::cin >> name;
std::cout << "Hi, " << name << std::endl;
}
int main() {
std::future<int> fret = std::async([&] {
return download("hello.zip");
});
interact();
int ret = fret.get();
return 0;
}最后调用 future 的 get() 方法,如果此时 download 还没完成,会等待 download 完成,并获取 download 的返回值。就相当于join()。
int main() {
std::future<int> fret = std::async([&] {
return download("hello.zip");
});
interact();
fret.wait();
return 0;
}除此之外,还有wait()方法。会等待线程执行完毕。但不会返回值。
但这个是只要线程没有结束,wait就会一直等待下去。
还有wait_for(),比如wait_for(std::chrono :: milliseconds(1000)),这个就是等待一千毫秒,如果一千毫秒还没完事,就不等了。

这个会返回一个std::future_status表示等待是否成功。
如果超过了时间放弃等待,会返回一个future_status::timeout
如果线程在指定时间内执行完毕,会返回一个future_status::ready
同理还有wait_until()。其参数和之前一样是一个时间点。















 7339
7339

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









