







 本文介绍了如何在NVIDIAA100GPU环境中使用命令行微调Meta的Llama38B模型,包括下载模型、安装依赖、使用TRL工具进行SFT微调,以及遇到的常见问题及解决方案,如数据下载异常、模型参数设置等。
本文介绍了如何在NVIDIAA100GPU环境中使用命令行微调Meta的Llama38B模型,包括下载模型、安装依赖、使用TRL工具进行SFT微调,以及遇到的常见问题及解决方案,如数据下载异常、模型参数设置等。
4月19日Meta终于发布了Llama3,包含8B和70B两种模型,本次我们就来试着用命令行微调下8B的模型。
参考:https://huggingface.co/blog/zh/llama3
环境:
GPU:NVIDIA A100 80G
CUDA:12.3
Python 3.11+PyTorch 2.1.2+transformers 4.40.0
一、关于Llama3
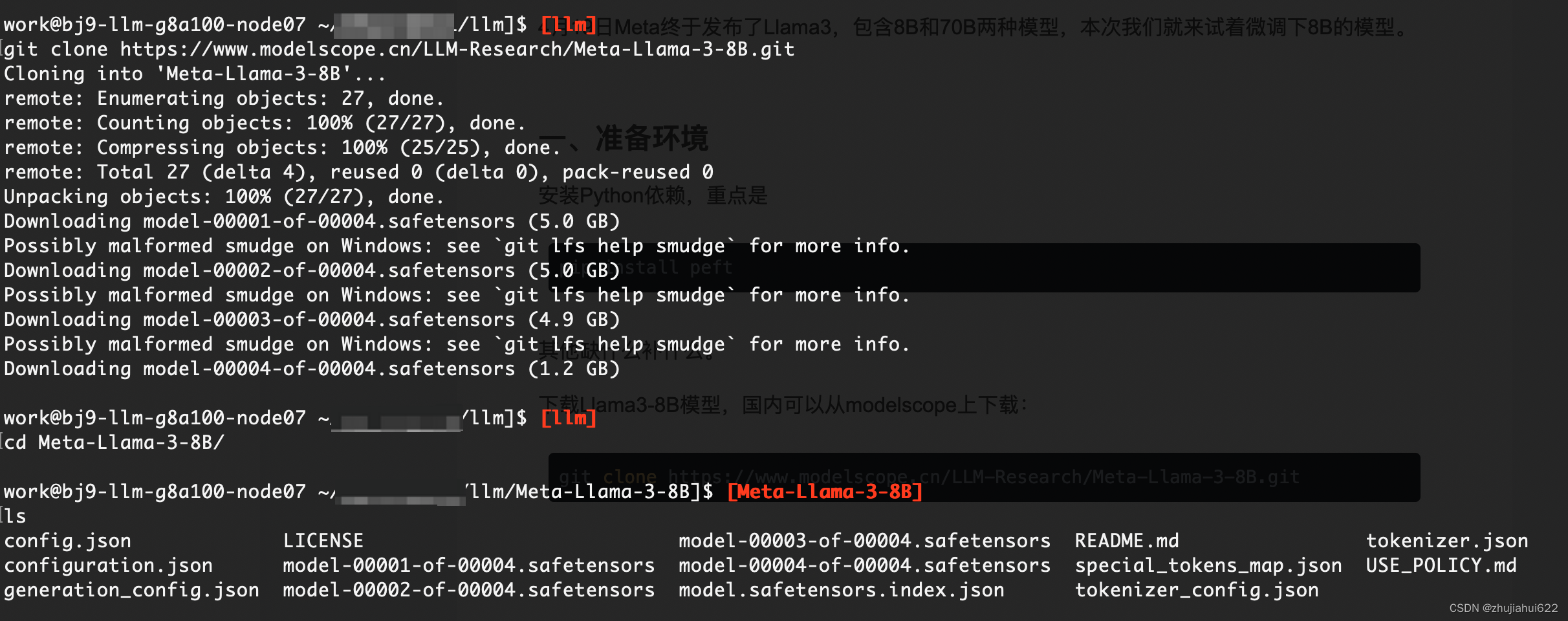
下载Llama3-8B模型,国内可以从modelscope上下载:
git clone https://www.modelscope.cn/LLM-Research/Meta-Llama-3-8B.git下载完毕后有如下文件:
二、关于trl
trl (Transformer Reinforcement Learning),Transformer强化学习,它提供了在训练和微调LLM的各个步骤中的实现,包括监督微调步骤(SFT),奖励建模步骤(RM)和近端策略优化(PPO)等。
Github:GitHub - huggingface/trl: Train transformer language models with reinforcement learning.
直接安装
pip install trl其他依赖
pip install bitsandbytes
pip install accelerate
pip install peft三、下载数据集
采用imdb数据集,已经帮忙分好了train和test
HuggingFace下载地址:https://huggingface.co/datasets/stanfordnlp/imdb
如果HuggingFace无法下载,可以从这里下载:Sentiment Analysis
下载后文件名重命名为imdb
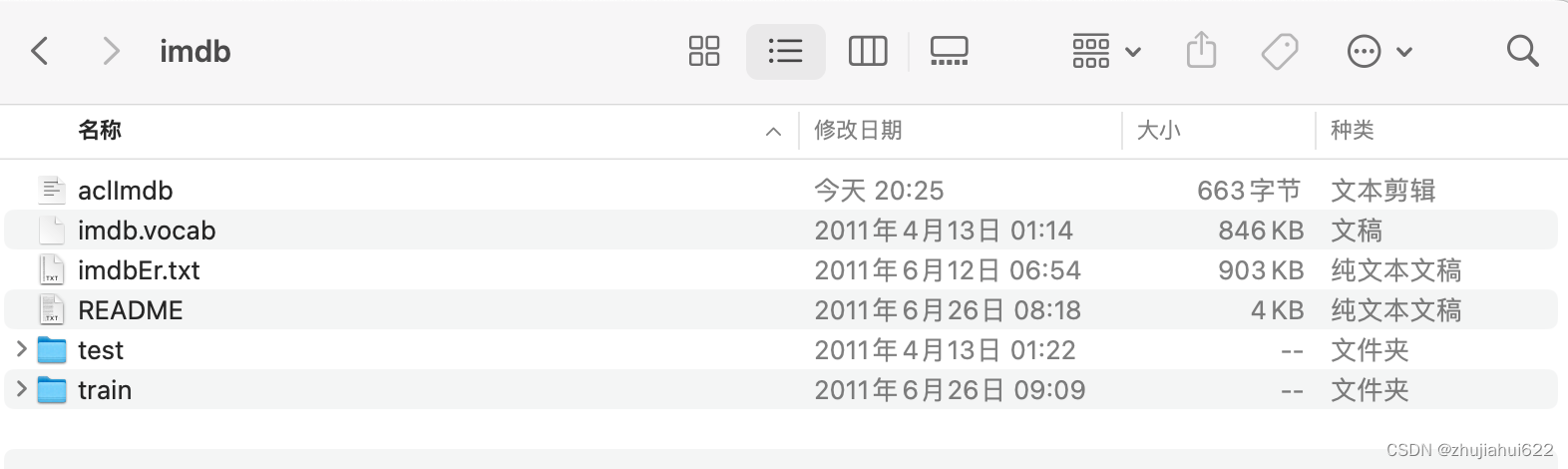
下载后将数据集上传至服务器指定位置。
四、开始SFT微调
注意:在开始之前要先运行以下命令进行配置:
accelerate config依次设置以下信息
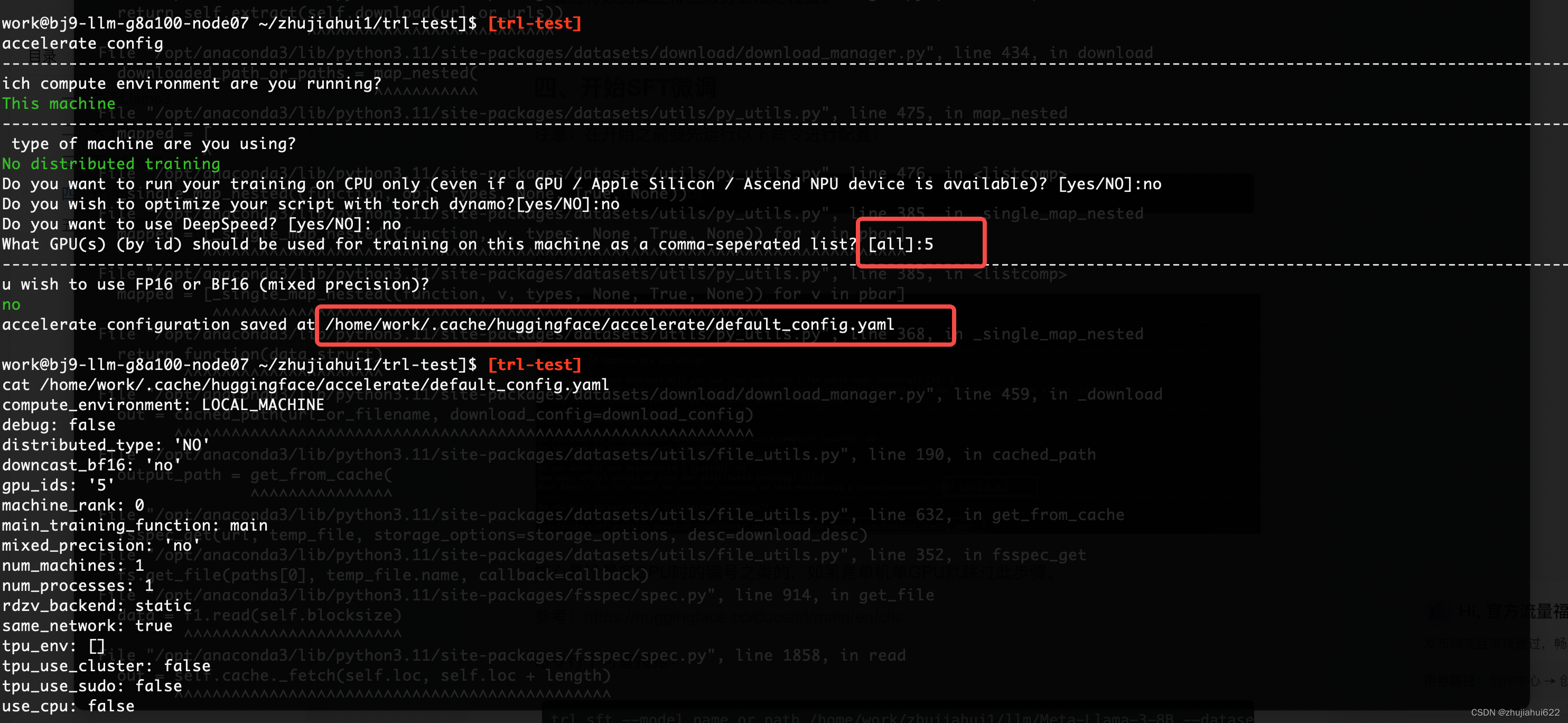
核心是设置多GPU时的编号之类的,如果是单机单GPU就跳过此步骤。
参考:https://huggingface.co/docs/trl/main/en/clis
命令行下可直接跑:
trl sft --model_name_or_path /home/work/zhujiahui1/llm/Meta-Llama-3-8B --dataset_name /home/work/zhujiahui1/dataset/imdb --dataset_text_field text --load_in_4bit --use_peft --max_seq_length 512 --learning_rate 0.001 --per_device_train_batch_size 2 --output_dir ./sft-imdb-llama3-8b --logging_steps 10逐行模式:
trl sft \
--model_name_or_path /home/work/zhujiahui1/llm/Meta-Llama-3-8B \
--dataset_name /home/work/zhujiahui1/dataset/imdb \
--dataset_text_field text \
--load_in_4bit \
--use_peft \
--max_seq_length 512 \
--learning_rate 0.001 \
--per_device_train_batch_size 2 \
--output_dir ./sft-imdb-llama3-8b \
--logging_steps 10运行效果:
加载数据和模型:

开始微调(最下方是日志信息):

运行还是比较漫长的,就不等结果了。
查看显存占用:大概26G。
| 微调前 | 微调后 |
 |  |
五、常见问题
1. urllib3.exceptions.ProtocolError: ('Connection aborted.', ConnectionResetError(54, 'Connection reset by peer'))
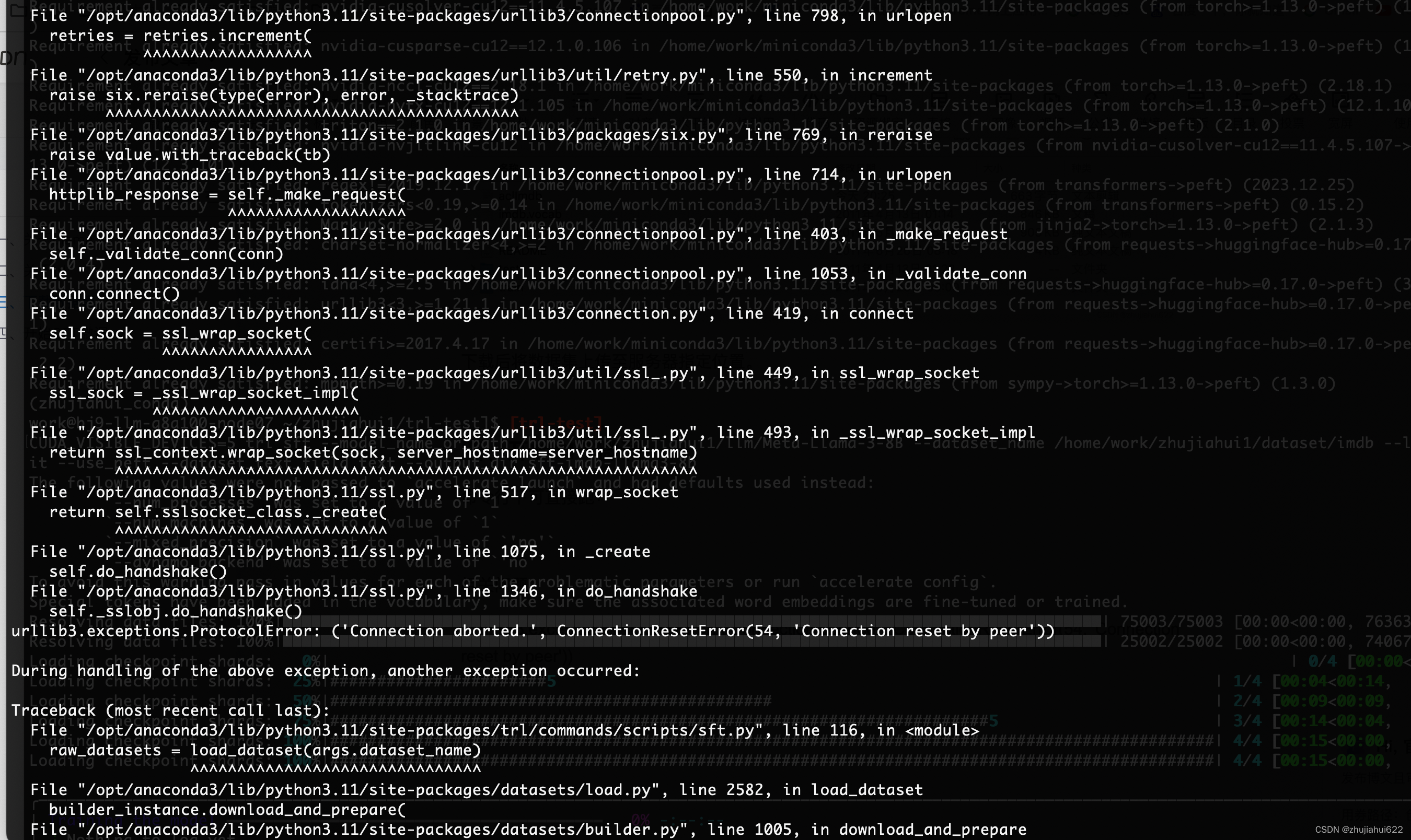
原因:由于众所周知的原因,数据集从HuggingFace下载异常。
解决方案:模型、数据集等一律离线下载好,用路径指定。
2. raw_datasets KeyError: 'test'
Traceback (most recent call last):
File "/opt/anaconda3/lib/python3.11/site-packages/trl/commands/scripts/sft.py", line 119, in <module>
eval_dataset = raw_datasets[args.dataset_test_name]
~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^^^^^^
File "/opt/anaconda3/lib/python3.11/site-packages/datasets/dataset_dict.py", line 74, in __getitem__
return super().__getitem__(k)
^^^^^^^^^^^^^^^^^^^^^^
KeyError: 'test'
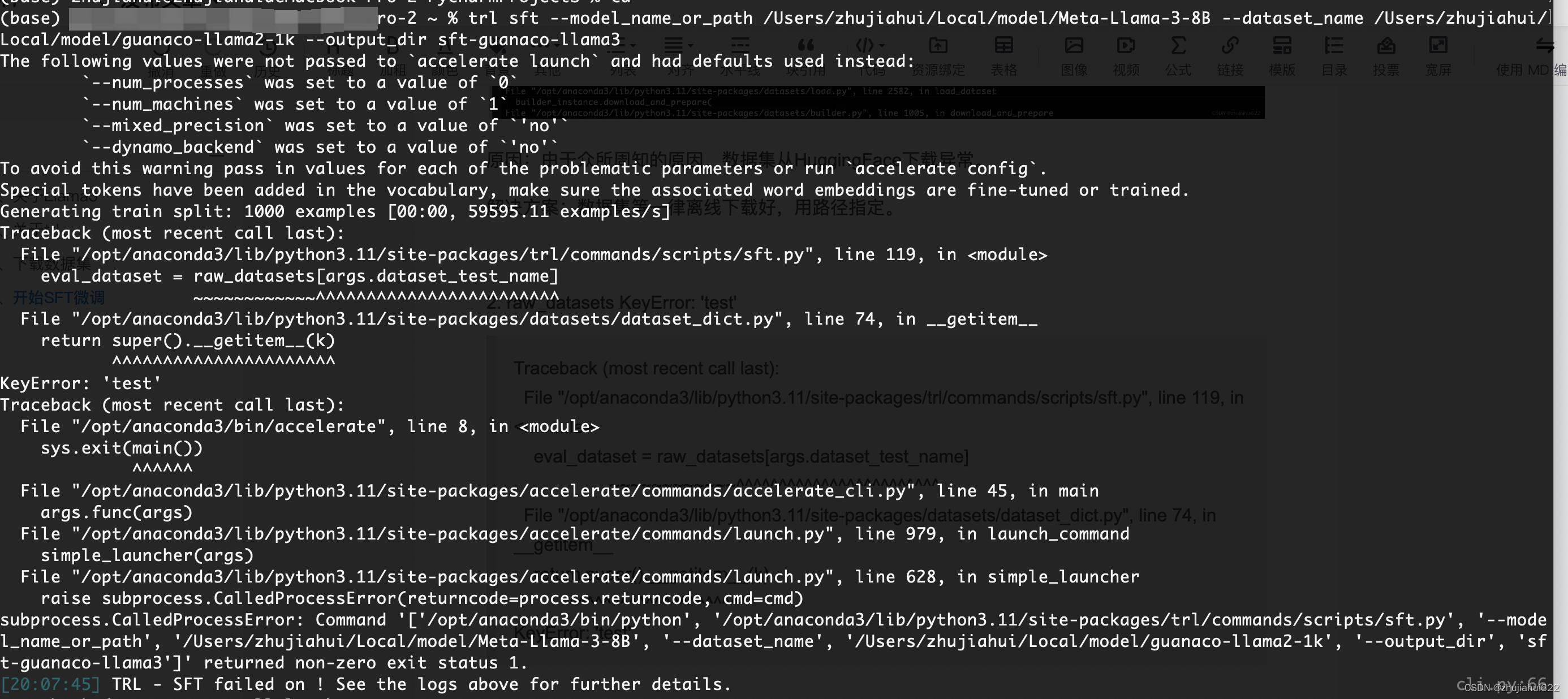
原因:imdb数据集需要指定文本列。
解决方案:在命令行中补充--dataset_text_field text。参考:python - TRL SFTTrainer - llama2 finetuning on Alpaca - datasettext field - Stack Overflow
3. TypeError: LlamaForCausalLM.__init__() got an unexpected keyword argument 'attn_implementation'
SFTTrainer中报错
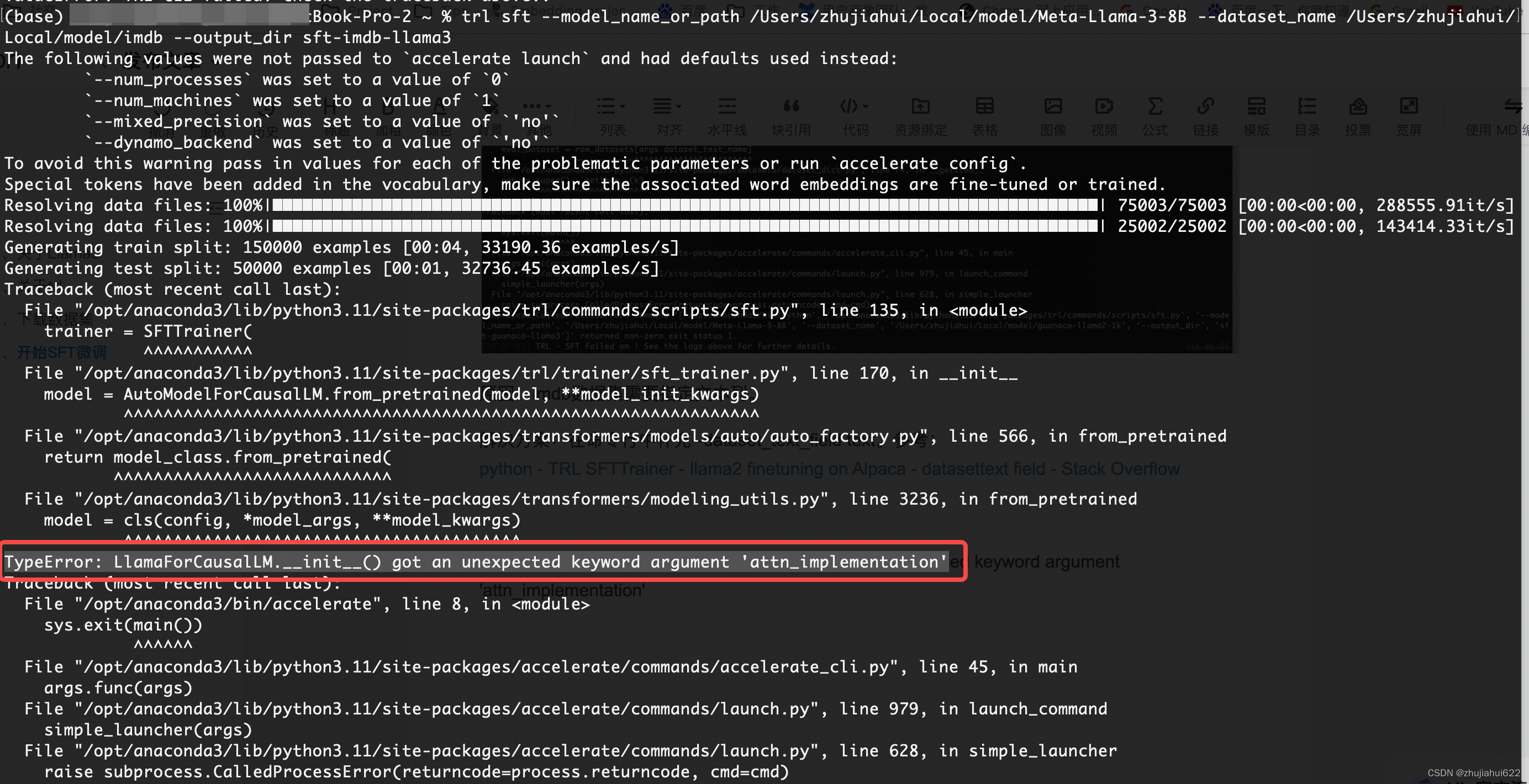
原因:平台不对,笔者刚开始在Mac本地跑,出现上述错误,在A100 GPU服务器上跑,没出现该问题,FlashAttention等高级的Attention实现在Mac上是不支持的。
解决方案:一定要在NVIDIA GPU环境中跑。
4. ValueError: You cannot perform fine-tuning on purely quantized models. Please attach trainable adapters on top of the quantized model to correctly perform fine-tuning. Please see: https://huggingface.co/docs/transformers/peft for more details

原因:使用量化时必须同时使用peft。
解决方案:--load_in_4bit和--use_peft要同时加上。
5. if DebugOption.UNDERFLOW_OVERFLOW in self.args.debug: TypeError: argument of type 'bool' is not iterable

原因:命令行中加了不该加的参数。
解决方案:去掉参数--config /home/work/.cache/huggingface/accelerate/default_config.yaml。
注意:该配置文件默认会加载,因此不必在命令行中显式加。
6. 各种显存不足:torch.cuda.OutOfMemoryError: CUDA out of memory
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 224.00 MiB. GPU 0 has a total capacty of 79.15 GiB of which 89.50 MiB is free. Process 89227 has
2.24 GiB memory in use. Process 61266 has 1.62 GiB memory in use. Process 48365 has 8.89 GiB memory in use. Including non-PyTorch memory, this process has 66.29 GiB
memory in use. Of the allocated memory 62.53 GiB is allocated by PyTorch, and 3.26 GiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is
large try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
原因:本次微调运行的GPU编号为5,即cuda:5。该GPU空闲的显存为66G左右,按理对于1个8B的模型微调是肯定装得下的(以往经验告诉我ChatGLM3微调显存16G足矣),但是竟然报显存不足。
解决方案:量化和peft必须开启。调低--max_seq_length,设置为512,调低--per_device_train_batch_size,设置为2。















 1808
1808

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









