




 本文深入解析图卷积网络(GCN)的工作原理,探讨其在半监督分类任务中的应用,特别是在文本分类数据集上的表现。通过复现经典论文,并在Citeseer、Cora和Pubmed数据集上进行实验,展示GCN的强大分类能力。
本文深入解析图卷积网络(GCN)的工作原理,探讨其在半监督分类任务中的应用,特别是在文本分类数据集上的表现。通过复现经典论文,并在Citeseer、Cora和Pubmed数据集上进行实验,展示GCN的强大分类能力。
一、GCN的理解
关于GCN的学习主要是基于 Semi-Supervised Classification with Graph Convolutional Networks 这篇论文和网上的一些博客。
-
GCN的提出
图结构每个节点的相邻节点的数量是不确定的,因此用来处理欧几里得空间数据的常规CNN无法对其进行特征的提取,因此有了图卷积网络(Graph Convolutional Network, GCN)来对图中的节点进行特征提取。
-
GCN简介
GCN的输入包括 N ∗ N N * N N∗N( N N N是节点的数量)的邻接矩阵 A A A和 N ∗ C N * C N∗C( C C C是每个节点特征的数量)的特征矩阵 X X X,输出每个节点的特征F(它的维度是 N ∗ C o u t p u t N * C_{output} N∗Coutput).
-
GCN的设计理念
我理解的GCN的设计理念和CNN有很大相似之处: 局部特征和权值共享。
图像里的局部特征是指邻域的特征,图结构的局部特征是指相连节点的特征,这里是通过 A X AX AX 获得。
F = A X = { a 11 a 12 ⋯ a 1 n a 21 a 22 ⋯ a 2 n ⋮ ⋮ ⋱ ⋮ a n 1 a n 2 ⋯ a n n } ∗ { x 11 x 12 ⋯ x 1 c x 21 x 22 ⋯ x c ⋮ ⋮ ⋱ ⋮ x n 1 x n 2 ⋯ x n c } F = AX = \left\{ \begin{matrix} a_{11} & a_{12} & \cdots & a_{1n} \\ a_{21} & a_{22} & \cdots & a_{2n} \\ \vdots & \vdots & \ddots & \vdots \\ a_{n1} & a_{n2} & \cdots & a_{nn} \end{matrix} \right\} * \left\{ \begin{matrix} x_{11} & x_{12} & \cdots & x_{1c} \\ x_{21} & x_{22} & \cdots & x_{c} \\ \vdots & \vdots & \ddots & \vdots \\ x_{n1} & x_{n2} & \cdots & x_{nc} \end{matrix} \right\} F=AX=⎩⎪⎪⎪⎨⎪⎪⎪⎧a11a21⋮an1a12a22⋮an2⋯⋯⋱⋯a1na2n⋮ann⎭⎪⎪⎪⎬⎪⎪⎪⎫∗⎩⎪⎪⎪⎨⎪⎪⎪⎧x11x21⋮xn1x12x22⋮xn2⋯⋯⋱⋯x1cxc⋮xnc⎭⎪⎪⎪⎬⎪⎪⎪⎫
F i j = a i 1 x 1 j + a i 2 x 2 j + ⋯ + a i n x n j F_{ij} = a_{i1}x_{1j} + a_{i2}x_{2j} + \cdots + a_{in}x_{nj} Fij=ai1x1j+ai2x2j+⋯+ainxnj
可以看到第 i i i个节点的第 j j j个特征是由第 i i i个节点的相邻节点的第 j j j个特征相加得到,这与CNN的局部特征类似。
但是这种操作会带来两个问题,一是它并没有考虑自身节点的特征,因此需要对邻接矩阵做如下处理:
A ~ = A + I \tilde A = A + I A~=A+I
二是,可能会导致节点的特征的量级不一样,比如假如节点1有10,000个相邻节点,而节点10有1个相邻节点,那么会导致节点1的特征是10,000个相邻节点特征的和,而节点10的特征是1个相邻节点的特征的和,这会导致不同节点的特征量级不一样。这个可以通过对特征除以节点的度进行处理,矩阵的形式就是:
D ~ A ~ X \tilde D \tilde A X D~A~X
D ~ \tilde D D~是 A ~ \tilde A A~的节点的度构成的对角矩阵。
论文中的GCN layer的结构是:
F = G C N ( A , X ) = σ ( D ~ − 1 2 A ~ D ~ − 1 2 X W ) F = GCN(A, X) = \sigma(\tilde D^{-\frac{1}{2}} \tilde A \tilde D^{-\frac{1}{2}}XW) F=GCN(A,X)=σ(D~−21A~D~−21XW)
其中 W W W是待学习的参数, σ \sigma σ是激活函数.
三、实现的代码
基于PyTorch复现的代码已上传至https://github.com/zhulf0804/GCN.PyTorch
F = G C N ( A , X ) = D ~ − 1 2 A ~ D ~ − 1 2 R e L U ( D ~ − 1 2 A ~ D ~ − 1 2 X W 1 ) W 2 F = GCN(A, X) = \tilde D^{-\frac{1}{2}} \tilde A \tilde D^{-\frac{1}{2}} ReLU(\tilde D^{-\frac{1}{2}} \tilde A \tilde D^{-\frac{1}{2}}XW_1)W_2 F=GCN(A,X)=D~−21A~D~−21ReLU(D~−21A~D~−21XW1)W2
网络结构 两个GCN层,第一个GCN层的激活函数是ReLU,且第一层的参数添加L2正则化(weight_decay=5e-4),第二个GCN层没有激活函数,也不添加L2正则化。Dropout设置为0.5,中间层的dim是16。Loss函数是交叉熵损失函数,学习方法是Adam算法,学习率设置为固定的0.01。
半监督学习 在训练中使用半监督学习。半监督学习利用无标签数据来提高监督学习的性能,即同时使用有标签的数据和无标签的数据。在GCN里表现为,所有的数据(V(边), E(节点))都参与训练,但每类只包含特定个数(这里使用的是20个)有标签的数据,其它的数据也参与训练但无标签,在计算损失函数的时候只考虑带有标签的数据。详细配置请查看实验结果部分。
四、实验结果
在数据集citeseer, cora,pubmed上进行了训练和测试。
1. 数据集简介
这是三个文本分类数据集,官网链接。每个数据集都包含文档的bag-of-words表示和文档的引用链接(citation links)。Bag-of-words表示为一个由0, 1组成的高维特征向量,0表示不包含这个word,1表示包含这个word。基于引用链接构建了来构建图:如果文档 i i i引用了 j j j,则 a i j = a j i = 1 a_{ij} = a_{ji} = 1 aij=aji=1。Citeseer, cora和pubmed数据集分别包含6,7和3类数据,类别名称如下所示。
- citeseer: Agents, AI, DB, IR, ML, HCI
- cora: Case_Based, Genetic_Algorithms, Neural_Networks, Probabilistc_Methods, Reinforcement_Learning, Rule_Learning, Theory
- pubmed: Diabetes_Mellitus_Experimental, Diabetes_Mellitus_Type_1, Diabetes_Mellitus_Type_2
更详细的数据信息如下
训练集、验证集和测试集的划分和https://github.com/tkipf/gcn一样,详细信息如下表所示。
| Dataset | Nodes | Edges | Features | Classes | #train | #val | #test |
|---|---|---|---|---|---|---|---|
| Citeseer | 3,327 | 4,732 | 3,703 | 6 | 120(20 each class) | 500(29, 86, 116, 106, 94, 69) | 1000(77, 182, 181, 231, 169, 160) |
| Cora | 2,708 | 5,429 | 1,433 | 7 | 140(20 each class) | 500(61, 36, 78, 158, 81, 57, 29) | 1000(130, 91, 144, 319, 149, 103, 64) |
| Pubmed | 19,717 | 44,338 | 500 | 3 | 60(20 each class) | 500(98, 194, 208) | 1000(180, 413, 407) |
注:
- 括号内的数字表示每一类的数量
- 刚开始一直好奇citeseer数据集的Nodes的数量,论文中给的是3,327,官网数据集上的是3,312。后来弄明白图中的节点数量是3,327,但是有15个没有特征向量,所以是3,312。
实验结果
-
Accuracy
Citeseer(%) Cora(%) Pubmed(%) this repo 70.8 82.5 79.2 paper 70.3 81.5 79.0 -
T-SNE可视化
-
citeseer
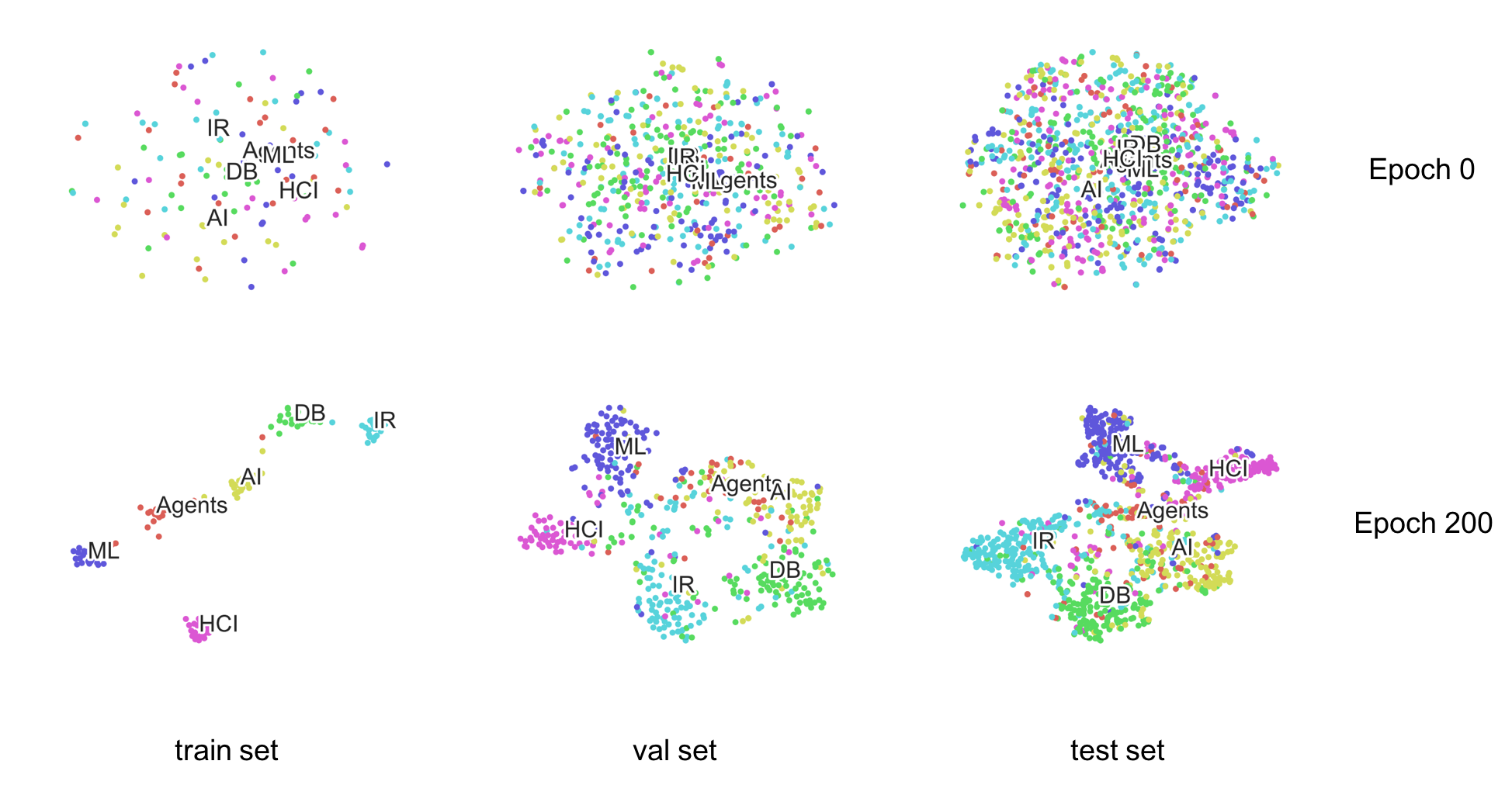
-
cora
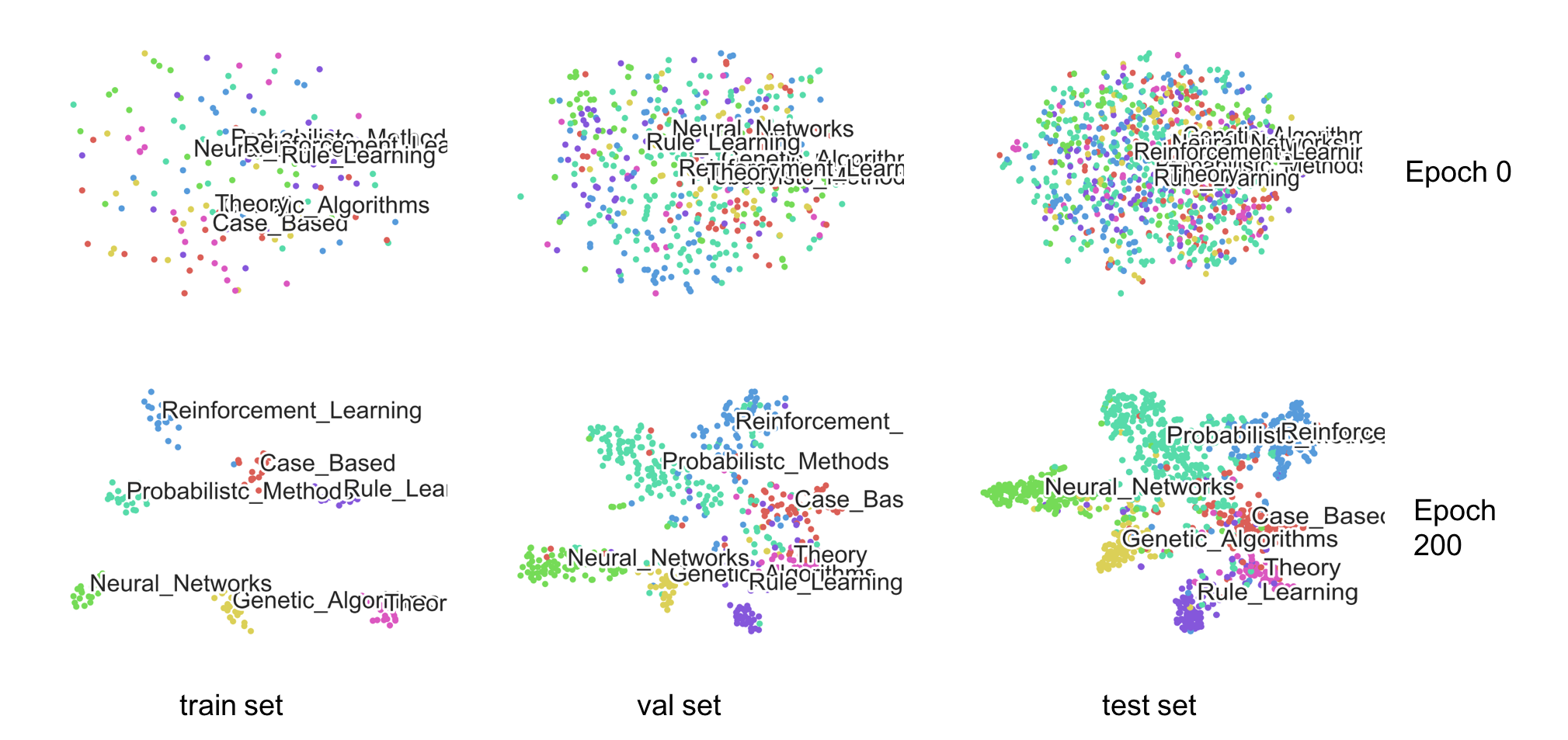
-
pubmed
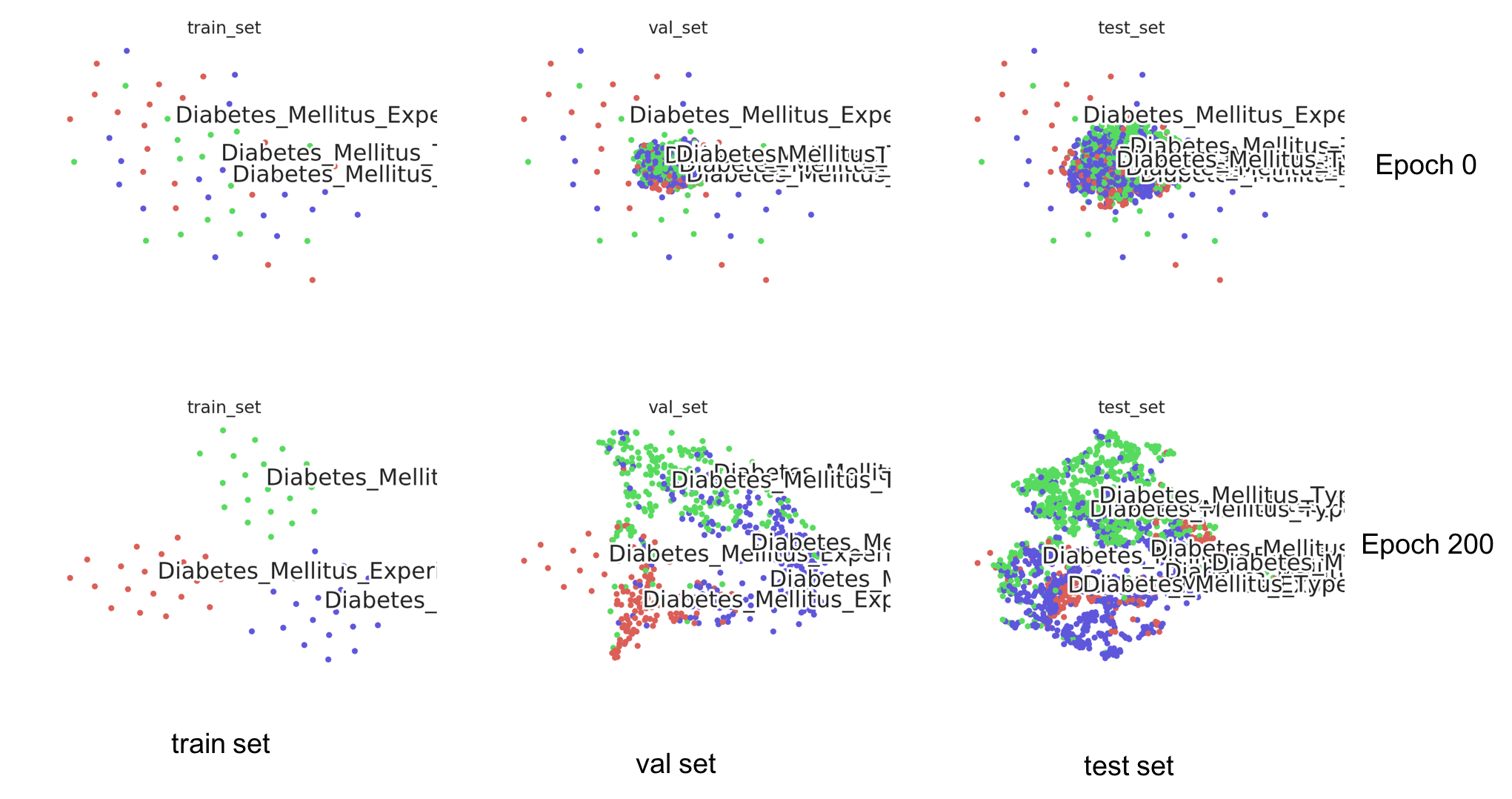
-
-
Accuracy和Loss训练曲线
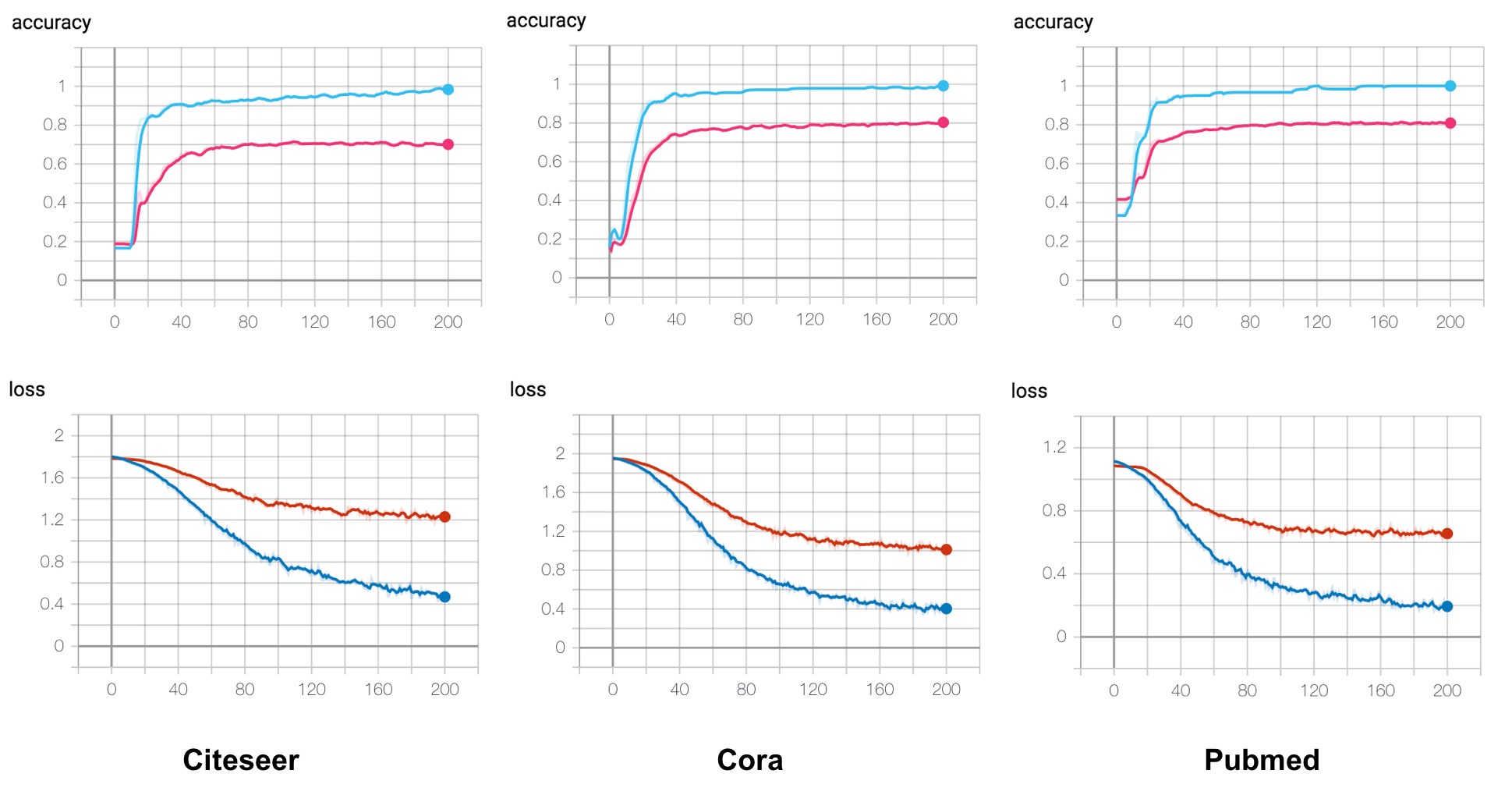
-
训练样本数量对模型的影响(citeseer, 200 epoches的效果, 论文中train samples是120)
# train samples accuracy(%) 120 70.8 240 70.6 360 71.5 -
两个GCN层都加入L2正则化对模型的影响(citeseer, 200 epoches的效果)
gcn1 gcn2 accuracy(%) experiment reg reg 71.9 paper reg no-reg 70.8 -
不同weight_decay和dropout对模型的影响
weight_decay dropout train ac(%) val ac(%) test ac(%) 5e-3 0.7 90.8 68.4 70.1 5e-3 0.5 91.7 70.4 71.5 5e-3 0.2 93.3 71.0 71.8 5e-3 0.0 94.2 68.8 69.6 5e-4 0.7 97.5 70.0 70.8 5e-4 0.5 98.3 70.2 70.8 5e-4 0.2 98.3 70.8 70.7 5e-4 0.0 98.3 71.0 71.7 5e-5 0.7 100.0 67.8 68.3 5e-5 0.5 100.0 70.6 69.1 5e-5 0.2 100.0 68.2 69.5 5e-5 0.0 100.0 67.4 68.0 0.0 0.7 100.0 68.0 68.0 0.0 0.5 100.0 68.0 67.6 0.0 0.2 100.0 63.8 59.7 0.0 0.0 100.0 64.8 63.6 Note: 5e-4, 0.5是论文中的默认参数.
五、总结与不足
- GCN的功能强大,两层的GCN只需少量有label的数据,通过半监督学习方法即可实现高准确率的分类。
- GCN对模型中的一些超参数不敏感,比如是否两层都加L2正则化,weight_decay和dropout的参数,训练样本数量等。
- GCN训练时间快,甚至在CPU上即可很快训练。但有很多多维的稀疏的数据,导致对空间需求大,或者需要额外的数据结构来处理存储、处理这种稀疏数据。
- 上述实验的结果都是在CPU上训练得到。也写了GPU的训练版本,在citeseer和cora数据集上可以很快训练,但在pubmed数据上就爆了内存。所以后续考虑利用torch.sparse数据结构实现GPU版本的模型。

















 3194
3194

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









