







1.引言
上一篇关于大容量硬盘的文章(HDD最后的冲刺:大容量硬盘的奋力一搏)中,我们针对大容量硬盘研发状态,小编最近又有了新发现。WDC希望可以通过HDD和磁带结合,把盘的容量提升到100TB+。
2.数据大爆炸的时代
首先,我们先来看一组数据:现在是一个数据指数增长的时代,根据IDC数据预测,2025年全世界将产生175ZB的数据。未来5年的产生数据,将是过去所有产生数据的2倍以上。
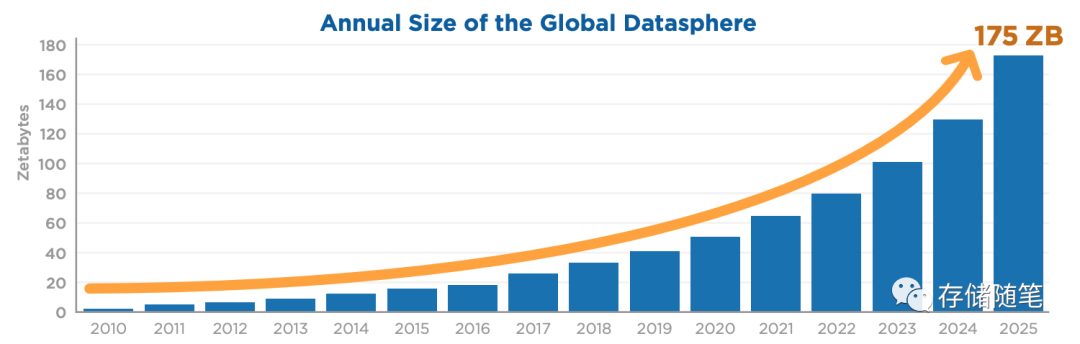
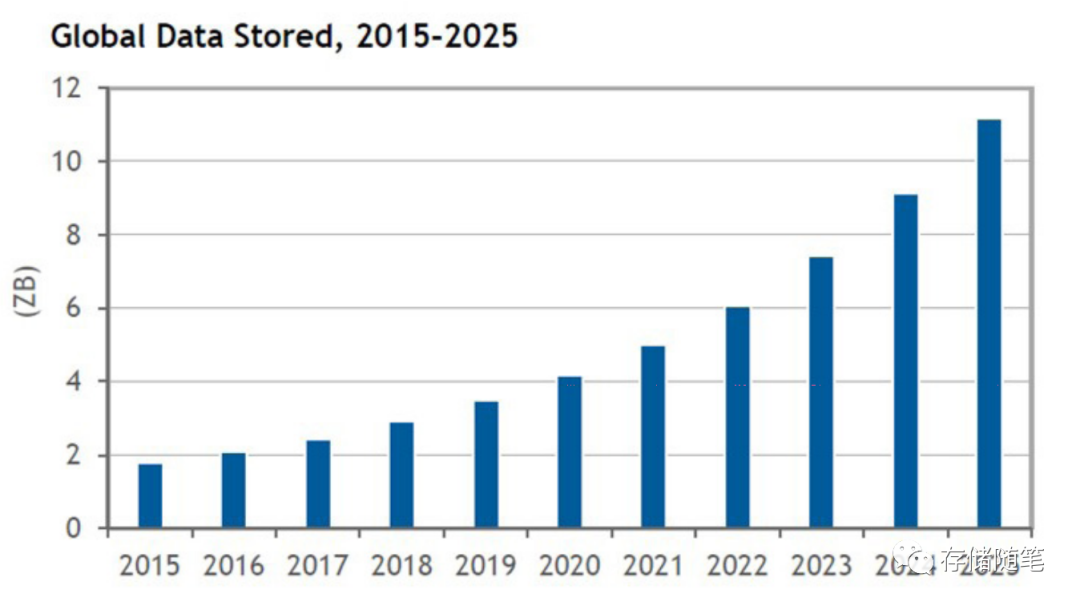
这里面大部分数据是不需要存储的,在2025预计每年需要存储11ZB的数据。换算个容易理解的说法,1ZB是10^18Bytes, 相当于要写5556万块容量18TB的硬盘。
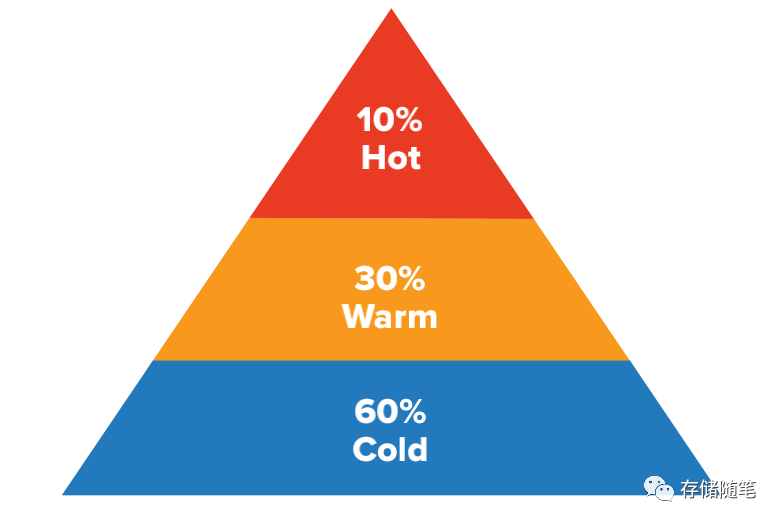
这些存储的数据中,仅10%认为是Hot频繁访问的数据,90%的数据都将是Warm/Cold温冷数据, 也就是不经常访问的数据。举个简单的例子,我们目前每人至少1部智能手机,里面存储大量的照片、视频、聊天记录等个人隐私数据,这些数据自产生后,我们开始可能会经常访问,在3个月以后,你还会对着数据有访问的诉求吗?这个概率基本会下降到1%以下。
从概率统计学来讲,超过3个月(90天)不再访问的数据,我们都可以称为冷数据,归档数据。每年全世界有25-35%的新增归档冷数据需要存储。这个市场的需求是非常的庞大。
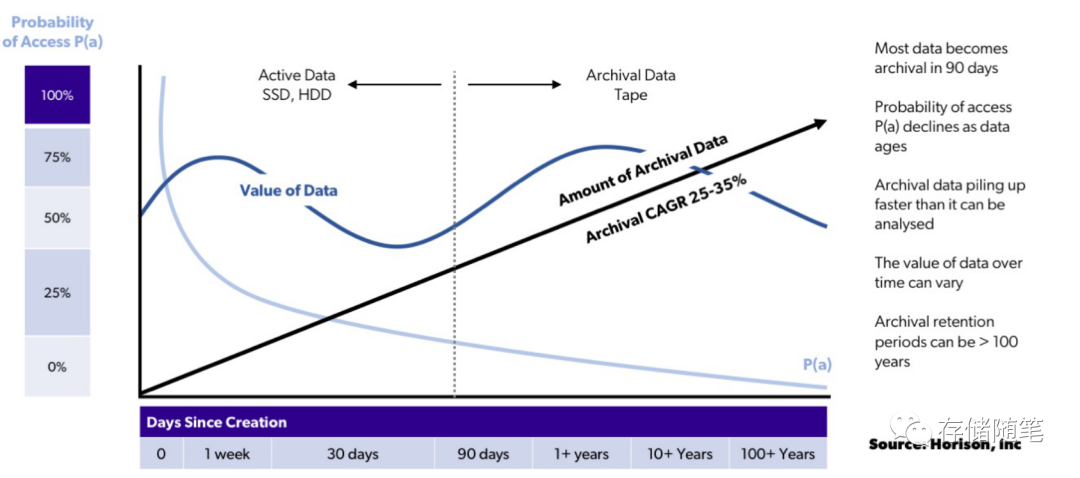
目前归档冷数据的最终归属大多数是基于HDD,SMR,磁带Tape等介质的冷存储系统。冷存储系统的最大的优点就是成本低和数据保留时间长,但是也带来相应的缺点就是冷归档数据读取过程需要“解冻”,数据访问响应时间拉长。
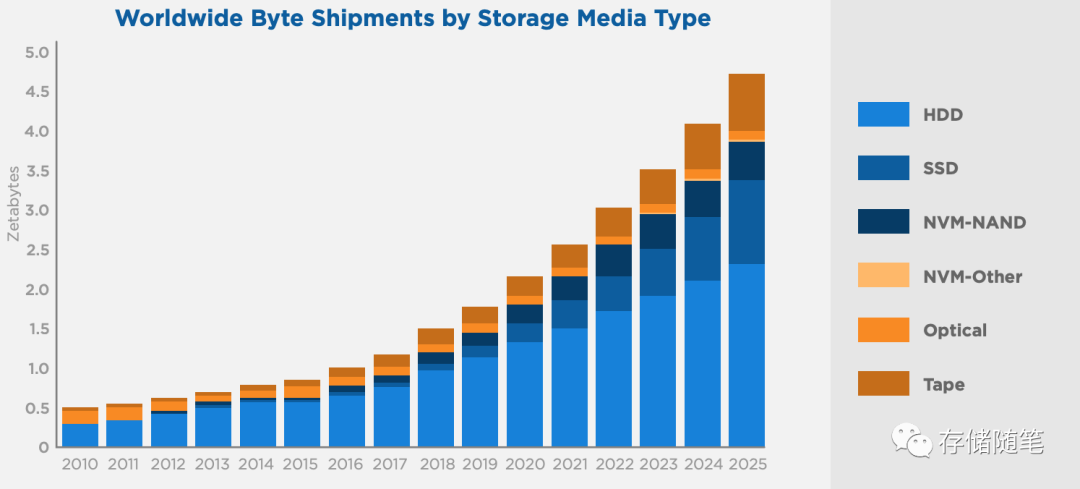
从上图存储介质的出货量和类型数据,我们也可以看到,在2025年,机械硬盘包括SMR新型机械盘存储介质的占比仍然有50%。这么多的数据需要存储,这部分对硬盘的容量要求越来越高。对于大容量盘,除了上一篇文章(HDD最后的冲刺:大容量硬盘的奋力一搏)中提到的,硬盘厂商希捷/西数WDC/东芝在发力搞HAMR/MAMR。
3.磁带与HDD的融合
这几天,小编又无意间发现,西数WDC还在研究磁带,甚至已经取得了多项专利,涵盖硬盘和磁带驱动器的设计和机制的组合。
专利1(20200258544):嵌入式磁带驱动器

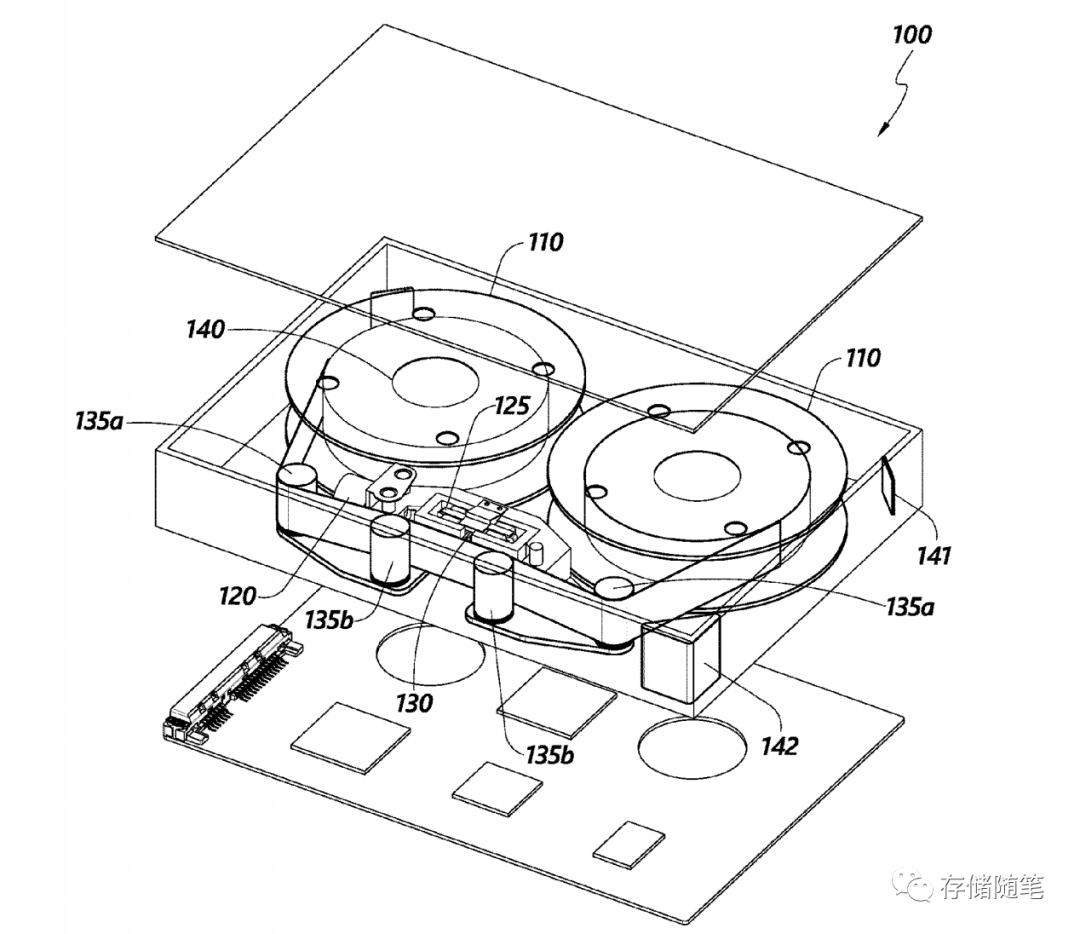
专利2(11081132): 带有HDD组件的嵌入式磁带驱动器
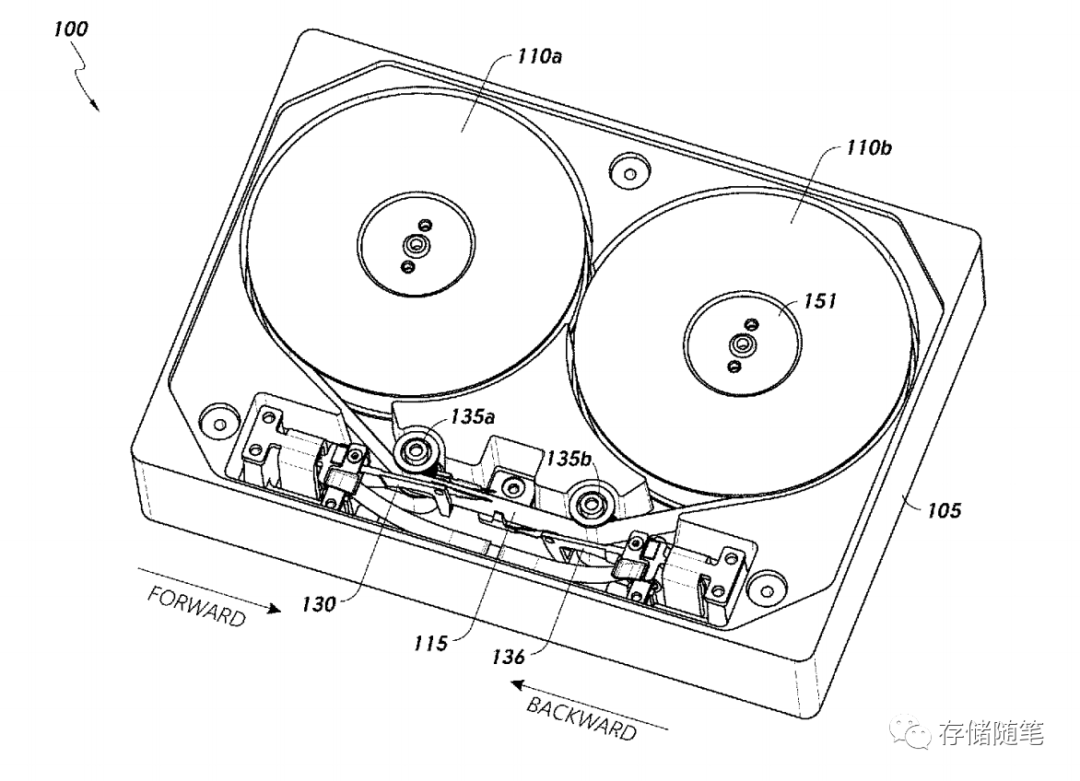
专利3(11393498):嵌入式磁带驱动器的磁头组装

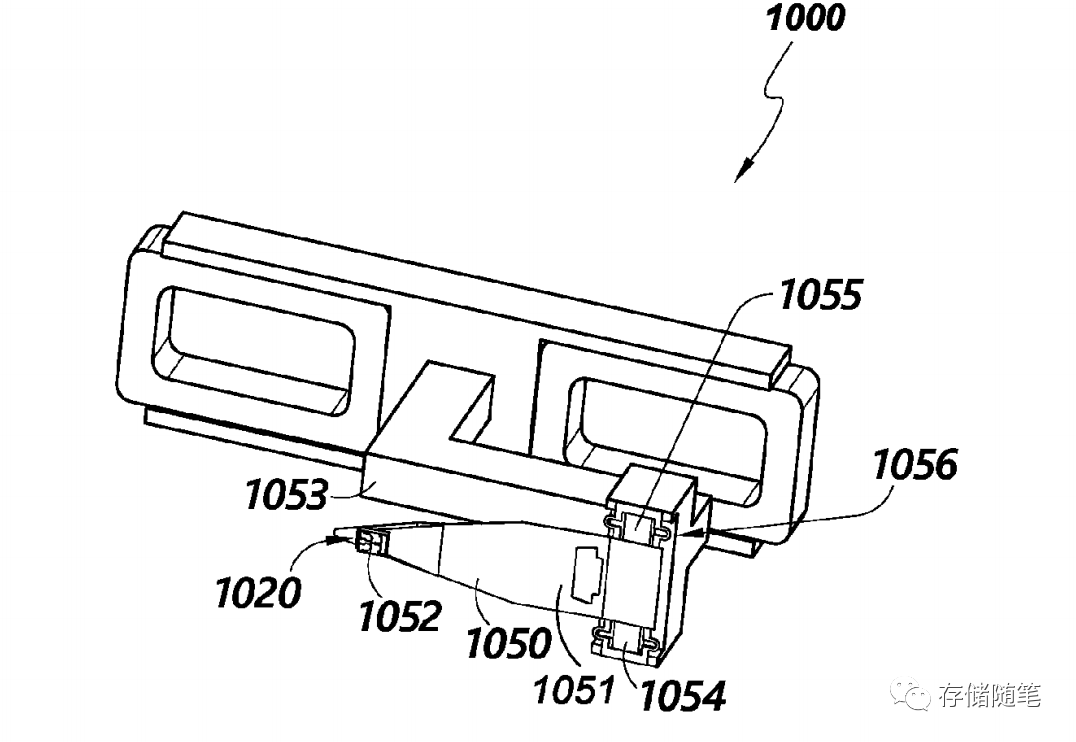
WDC 希望摆脱磁带驱动器和磁带库,并将任何磁带变成磁盘外形规格的驱动器。这暗示了一种有趣的可能性,即将磁带驱动器的基本组件与实际的磁带介质合并,以降低磁带库固有的环境和技术复杂性,并将访问时间至少缩短一个数量级。
磁带/磁带库的运行还是比较复杂的,更多细节可以参考之前发布的关于磁带的相关文章:
针对嵌入式磁带,Western Digital 的专利建议采用标准化的外形尺寸,即 2.5 英寸或 3.5 英寸,以便数据中心和超大规模提供商更容易采用。嵌入式磁带驱动器的价格,肯定比普通的磁带要贵,但也低于企业级的硬盘。
也许最大的挑战是将这种新颖的磁带方法引入 LTO 联盟,该组织负责监督 LTO 的开发,由 IBM、HPE 和 Quantum 组成,所有这些公司可能都有不同的商业策略,需要昂贵的驱动器和廉价的磁带。
磁带的格式和技术标准,在之前有很多种类,也导致各种不兼容。为了解决这个问题,上世纪90年代,三个厂商联合研发线性磁带开放 技术,LTO,Linear Tape Open。LTO标准最初有两个格式,一个Ultrium,主要负责支持大容量技术,一个Accelis,主要负责高性能。磁带被采用的原因,目前跟性能也不相关,要性能的话,早就切换固态硬盘SSD了。所以目前一说LTO,基本上大家就等同于LTO Ultrium。

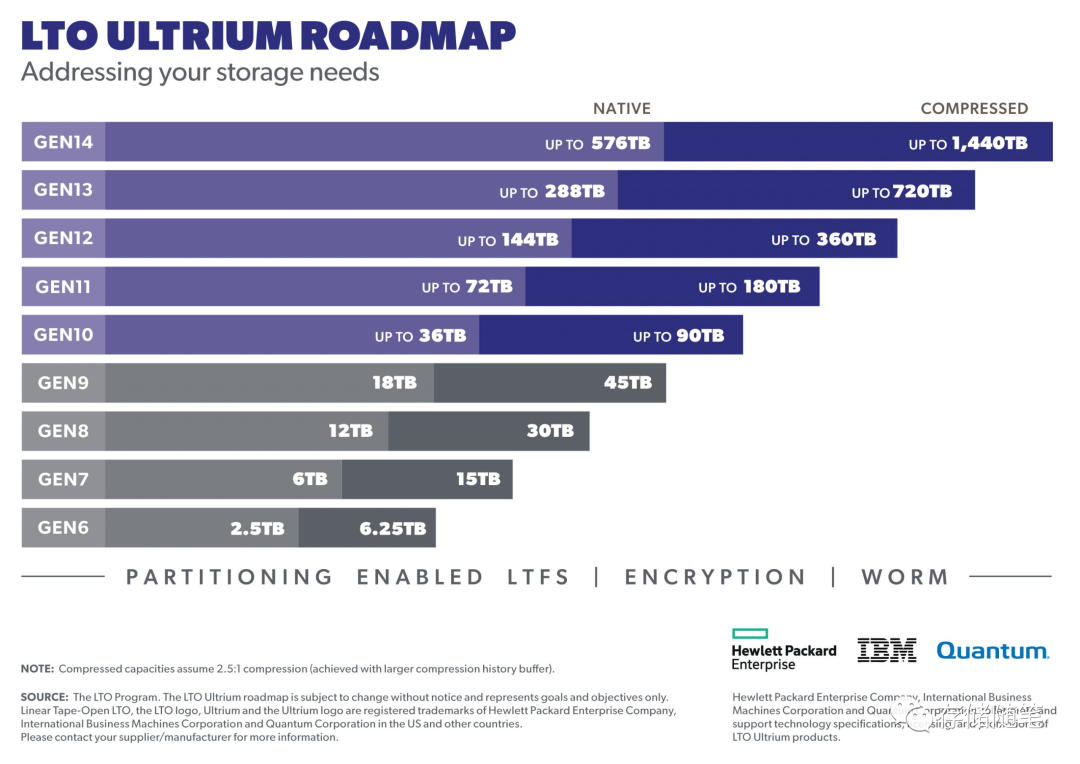
据了解,WDC希望可以通过这个技术,把盘的容量提升到100TB+。这个想法非常大胆!现在最新的磁带LTO9,压缩容量也只是45TB。小编认为实现100TB还是有很大难度的。
梦想还是要有的,万一实现了呢?祝福WDC好运,可以早日把专利变成商品!


















 1347
1347

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











