









在人工智能(AI)领域,我们正站在一个前所未有的转折点上,多家大型AI实验室,包括但不限于OpenAI/Microsoft、xAI、Meta等,正竞相构建拥有超过10万个GPU的超级集群,旨在推动AI能力进入下一个发展阶段。这一壮举不仅标志着计算能力的空前提升,同时也提出了对基础设施、能源、网络架构、可靠性及故障恢复机制等方面的深刻挑战。本文将深入分析这些超级集群背后的复杂性,以及它们如何塑造AI的未来。
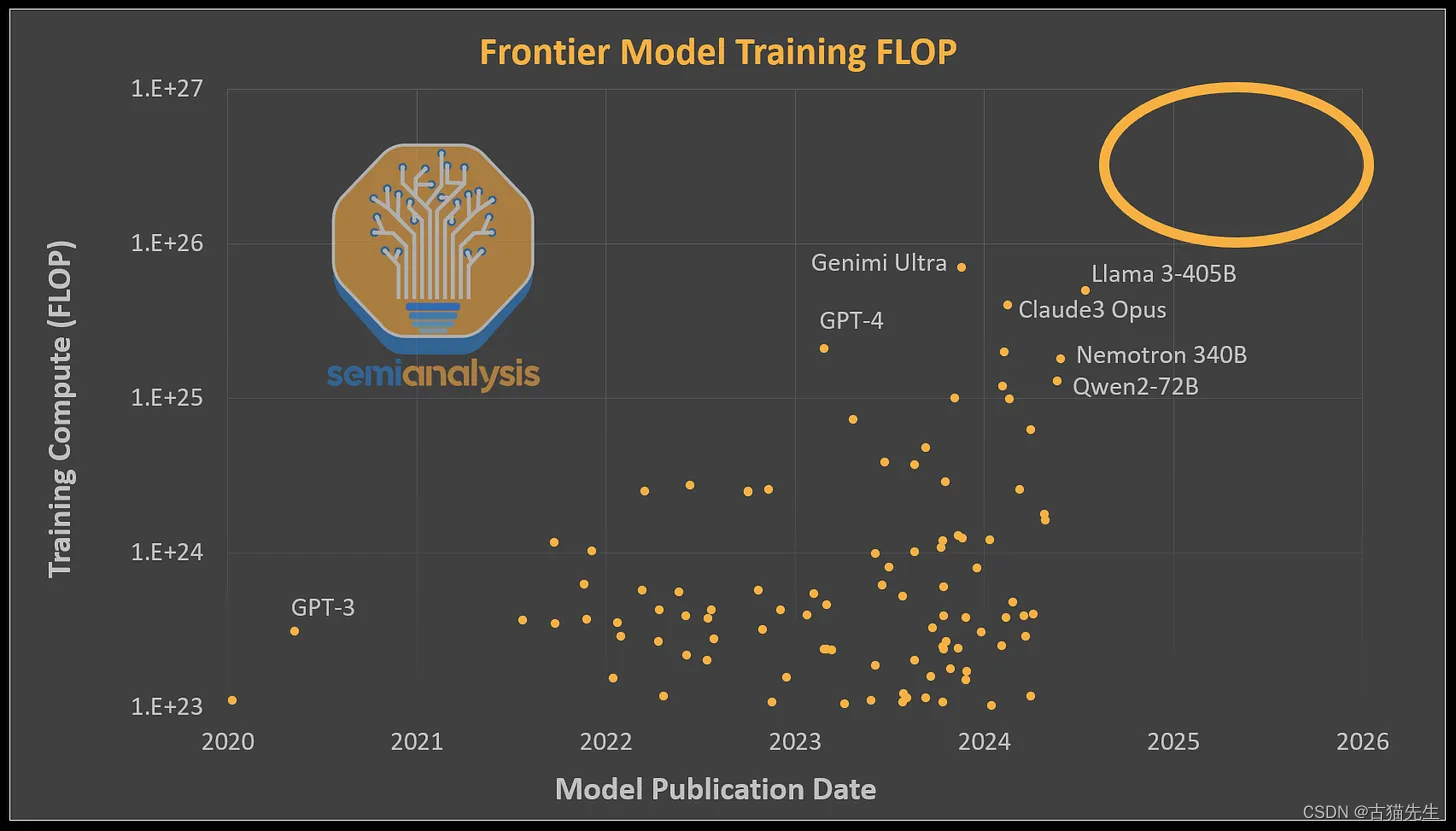
#### 电力与能源需求的极限挑战
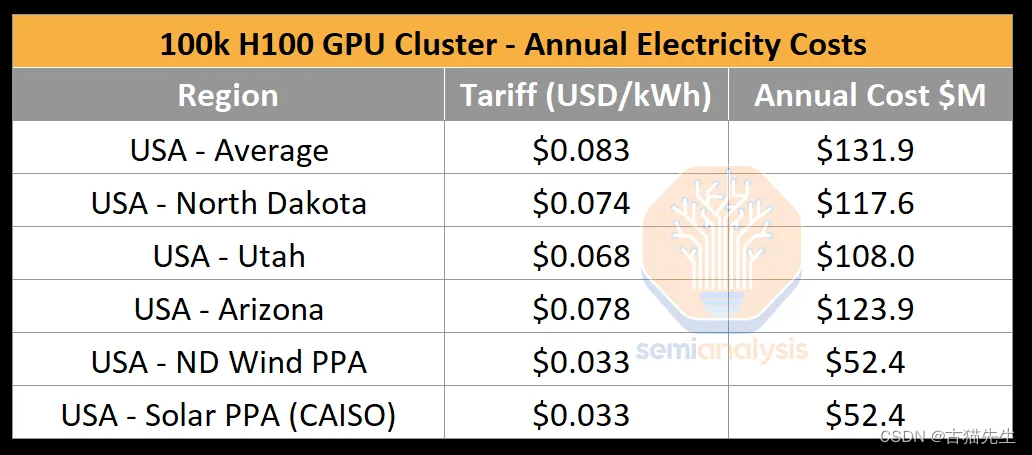
构建一个10万GPU规模的集群,其电力需求达到了惊人的150兆瓦以上,每年消耗的电量高达1.59太瓦时,相当于一个小国一年的用电量,成本约为1.24亿美元(按每千瓦时0.078美元的标准费率计算)。这一需求远远超过了当前单一数据中心的供电能力,迫使企业不得不在不同地点分散部署这些GPU“岛屿”,甚至将老旧工厂改造成数据中心,以满足供电和空间需求。
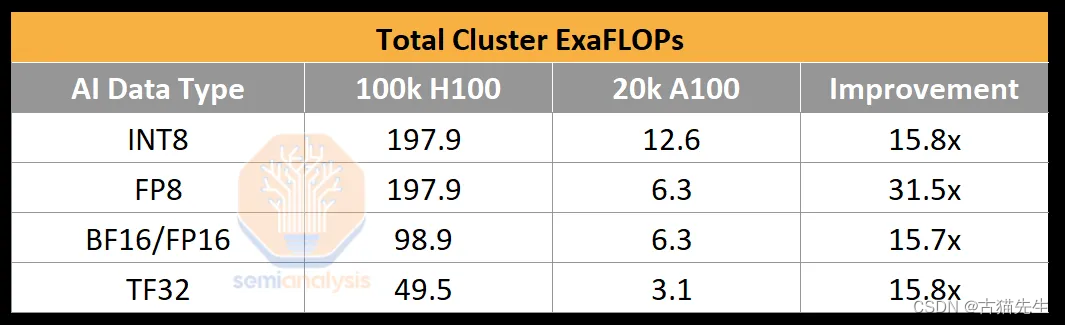
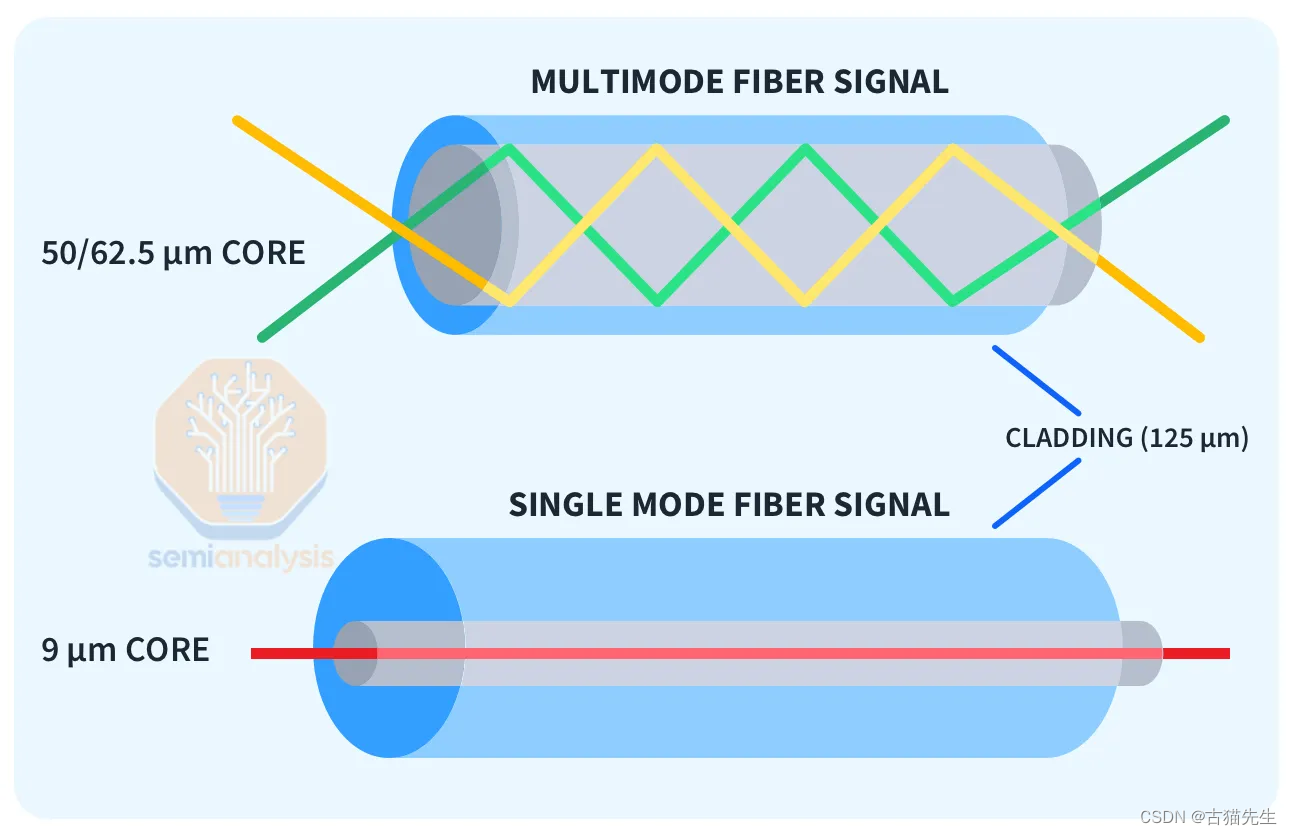
#### 网络架构的权衡:以太网与InfiniBand之争
在构建如此庞大的集群时,网络连接的效率与成本成为决定性因素。传统的以太网和高性能的InfiniBand成为两大选择。以太网虽在成本上有优势,但缺乏InfiniBand在高带宽和低延迟方面的表现,尤其是在网络减少(SHARP)技术方面,无法在交换机层面执行计算,减少了网络的理论带宽提升。相比之下,NVIDIA的Spectrum-X虽然在性能上有所突破,但初期采用Bluefield-3作为过渡方案,相比更高效的ConnectX-7,带来了额外的功耗和成本问题。因此,一些企业转向了Broadcom的Tomahawk 5,以获得更好的网络性能和灵活性。
#### 可靠性、失败与检查点策略
鉴于集群规模庞大,组件故障率的管理变得异常关键。高密度GPU的部署意味着任何单点故障都可能导致整个训练过程的中断,因此,有效的检查点机制成为必要。通过定期保存模型状态,即使遇到故障也能从最近的检查点恢复,从而减少了训练时间的损失。然而,频繁的检查点操作也会占用宝贵的计算资源和存储空间,这要求在效率与安全性之间找到平衡点。
#### 总结与展望
10万GPU集群的构建不仅是对技术的极限挑战,也是对未来AI发展方向的一次深远探索。随着对多模态学习的需求增加,如何在保持高能效比的同时,实现更大规模、更复杂模型的训练,将是未来几年AI研究的重要议题。此外,随着技术进步,如何解决电力供应、网络瓶颈、以及确保系统的高可靠性和可持续性,将决定这些超大规模集群能否真正推动AI迈向新的里程碑。对于行业而言,这场竞赛不仅仅是技术的比拼,更是对创新策略、生态协作与可持续发展观的全面考验。



















 7193
7193

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











