






 本文详细介绍了论文的写作规范,包括吸引人的标题(40-60个字母)、精炼的摘要(8-10句,问题、重要性、已有工作、本文贡献和实验结果)、关键词的选取与引言的撰写(扩展摘要内容,可能包含“开局一张图”和贡献概述)。此外,还讨论了证明的清晰表述(定义、案例和符号系统)和算法的伪代码表示,以及实验部分的数据集描述、结果展示和结论的撰写,强调了论文写作中的常见要点和技巧。
本文详细介绍了论文的写作规范,包括吸引人的标题(40-60个字母)、精炼的摘要(8-10句,问题、重要性、已有工作、本文贡献和实验结果)、关键词的选取与引言的撰写(扩展摘要内容,可能包含“开局一张图”和贡献概述)。此外,还讨论了证明的清晰表述(定义、案例和符号系统)和算法的伪代码表示,以及实验部分的数据集描述、结果展示和结论的撰写,强调了论文写作中的常见要点和技巧。
摘要
学习论文的写作规则对我们写论文是很重要的,从题目,摘要,关键词,引言,定理,证明,算法,实验、结论以及参考文献都有相应的表述规则,本文按照论文的格式,结合概念和示例,详细描述了每个部分的写作规范以及应该牢记的要点。通过这次的总结,能加强自己在写作方面的规范。
一、题目
论文题目对论文是非常重要的 ,他应该具备以下几个特点:
- 具有吸引力:能够激起读者的兴趣,有想要看下去的欲望
- 易于理解,不存在歧义
- 易于检索,提高被引用的频次
- 长度的控制,控制在40-60个字母之间,简短的标题对读者来说是十分友好的
- 尽量不要使用based on,没有深度
- 技术用through,with等来表示,若论文偏重算法,那题目的缩写就写算法的名称
举个例子:“基于主动学习的天然气集输异常工况分类方法研究”与改进后的“天然气集输异常工况处理的主动学习方法”明显第二个精简又有深度
二、摘要
文章的摘要很重要,是全文提炼的精华。要让别人,一看就知道你本文做了什么。看摘要看似很难,但也是有”套路“的。当你读了几篇论文过后,你会发现,他们的摘要的句子数量基本是一定的,一般未8-10句。第1-2句一般是说明问题和其重要性,以及已有工作。如Feature reduction is an important aspect of Big Data analytics on today’s ever-larger datasets. Rough sets are a classical method widely applied to attribute reduction. Most rough sets algorithms process continuous attributes by using a membership function, which is set using a priori knowledge of the dataset.第1,2句阐述了属性约简的重要性和其已有的应用。第3句阐述了已有工作的局限性,如 However, the neighborhood radius of each object in NRS is fixed, and optimization of the radius depends on grid searching. This diminishes both the efficiency and effectiveness, leading to a time complexity of not lower than O(N2).指出已有工作NRS的局限。第4,5,6,7句开始从不同角度介绍本文的工作,如we propose granular ball neighborhood rough sets (GBNRS), a novel NRS method with time complexity O(N). GBNRS adaptively generates a different neighborhood for each object, resulting in greater generality and flexibility in comparison to standard NRS methods.提出了本文介绍的GBNRS算法。第8,9,10句就是给出实验的设置,实验结果以及提升部分。如We compare GBNRS with the current state-of-the-art NRS method, FARNeMF, and find that GBNRS obtains both higher performance and higher classification accuracy on public benchmark datasets.这里给出了对比实验算法的设置和最后效果。
三、关键词和引言
关键词
- 关键词常被看作摘要的一种补充
- 一般需要 3-5 个关键词
- 将关键词按照字母表排序
- 有些期刊支持两类关键词
- index term: 由期刊提供, 只能从投稿网站给定的列表选择
- keywords: 作者自己按需写
如:Index Terms— Data reduction, granular computing, imbalanced classification, label noise, sampling, undersampling.
引言
引言应该对整个故事进行详细的描述. 如果说摘要是电影 5 分钟宣传片的话, 引言就应该是整个的剧本.
- 八股:摘要的每一句, 都扩展成引言中的一段
- 每段应有 5–10 句
- 计算机领域 (特别是顶会) 流行在引言里面放 “开局一张图”. 如果采用这种风格, In this paper 之后就应该围绕该图进行解释.该图可以展现核心技术、算法框架、小的运行实例、效果对比等等.
- 有些期刊和会议还喜欢让作者把自己的贡献单独列出来, 放在实验陈述段落之后. 这个与论文的 Highlights 是同一个意思.
- 期刊论文要求写论文的组织结构. 引言的最后一段以 The rest of the paper is organized as follows. 开头即可. 也不需要玩什么花样, 按部就班陈述即可.
四、证明和算法
证明
这个部分主要是对文章的定义、公式以及符号系统进行描述。在写定义的时候,最后要有相关案例解释,才能让读者更加的能理解。论文必须要有符号系统,才能让读者更好的阅读文章,而不是去全篇找符号解释。且全文符号要高度统一,不能前后不一致。下面是一个定义描写例子。
-
D
e
f
i
n
i
t
i
o
n
1.
Definition\ 1.
Definition 1.
<
U
,
A
,
V
,
f
>
<U,A,V,f>
<U,A,V,f>为一个信息系统,
∀
x
i
∈
U
,
a
∈
A
,
s
.
t
.
f
(
x
i
,
a
)
∈
V
a
,
\forall{x_i}\in{U},a\in{A,s.t. \ f(x_i,a)}\in{V_a},
∀xi∈U,a∈A,s.t. f(xi,a)∈Va,所有样本集的粒球
G
B
j
.
GB_j.
GBj.
P
⊆
A
,
X
⊆
U
,
X
P\subseteq{A},X\subseteq{U},X
P⊆A,X⊆U,X相对于属性集P的上近似集、下近似集和生成下近似集定义为:
P X ‾ = { x i ∈ U , x i ∈ G B j ( P ) ∣ σ ( x i ) ⋂ X ≠ ϕ } , \overline{PX}=\{x_i\in{U},x_i\in{GB_j(P)|\sigma(x_i)}\bigcap{X\not={\phi}}\}, PX={xi∈U,xi∈GBj(P)∣σ(xi)⋂X=ϕ},
P X ‾ = { x i ∈ U , x i ∈ G B j ( P ) ∣ σ ( x i ) ⊆ X } , \underline{PX}=\{x_i\in{U},x_i\in{GB_j(P)|\sigma(x_i)}\subseteq{X}\}, PX={xi∈U,xi∈GBj(P)∣σ(xi)⊆X},
P X ′ ‾ = { x = 1 l j ∑ i = 1 l j x i ∣ x i ∈ G B j ( P ) , σ ⊆ X } . \underline{PX'}=\Bigg\{x=\frac{1}{l_j}\sum^{l_j}_{i=1}x_i|x_i\in{GB_j(P),\sigma\subseteq{X}}\Bigg\} . PX′={x=lj1i=1∑ljxi∣xi∈GBj(P),σ⊆X}.-
D
e
f
i
n
i
t
i
o
n
2.
Definition\ 2.
Definition 2.给定决策表
(
U
,
C
,
D
)
(U,C,D)
(U,C,D),决策属性
D
D
D 将
U
U
U 划分为
L
L
L 个等价类:
X
1
,
X
2
.
.
.
,
X
L
.
∀
B
⊆
C
,
X_1,X_2...,X_L.\forall{B}\subseteq{C},
X1,X2...,XL.∀B⊆C,,所有样本集的粒球
G
B
j
.
GB_j.
GBj.关于条件属性子集
B
,
B,
B,决策属性集
D
D
D,给出上近似集,下近似集定义和生成下近似集为:
B ‾ D = ⋃ i = 1 L B ‾ X i , \overline{B}D=\bigcup^{L}_{i=1}\overline{B}X_i, BD=i=1⋃LBXi,
B ‾ D = ⋃ i = 1 L B ‾ X i \underline{B}D=\bigcup^{L}_{i=1}\underline{B}X_i BD=i=1⋃LBXi
B ‾ D ′ = ⋃ i = 1 L B ‾ X i ′ , \underline{B}D'=\bigcup^{L}_{i=1}\underline{B}X'_i, BD′=i=1⋃LBXi′,
w h e r e B ‾ X i = { x k ∈ U , x k ∈ G B j ( P ) ∣ σ ( x k ) ⋂ X i ≠ ϕ } , B ‾ X i = { x k ∈ U , x k ∈ G B j ( P ) ∣ σ ( x k ) ⊆ X i } , B ‾ X i ′ = { x = 1 l j ∑ i = 1 l j x k ∣ x k ∈ G B j ( P ) , σ ( x k ) ⊆ X i } . where\ \overline{B}X_i=\{x_k\in{U},x_k\in{GB_j(P)|\sigma(x_k)}\bigcap{X_i\not={\phi}}\},\underline{B}X_i=\{x_k\in{U},x_k\in{GB_j(P)|\sigma(x_k)}\subseteq{X_i}\}, \underline{B}X'_i=\Bigg\{x=\frac{1}{l_j}\sum^{l_j}_{i=1}x_k|x_k\in{GB_j(P),\sigma(x_k)\subseteq{X_i}}\Bigg\} . where BXi={xk∈U,xk∈GBj(P)∣σ(xk)⋂Xi=ϕ},BXi={xk∈U,xk∈GBj(P)∣σ(xk)⊆Xi},BXi′={x=lj1∑i=1ljxk∣xk∈GBj(P),σ(xk)⊆Xi}.
-
D
e
f
i
n
i
t
i
o
n
2.
Definition\ 2.
Definition 2.给定决策表
(
U
,
C
,
D
)
(U,C,D)
(U,C,D),决策属性
D
D
D 将
U
U
U 划分为
L
L
L 个等价类:
X
1
,
X
2
.
.
.
,
X
L
.
∀
B
⊆
C
,
X_1,X_2...,X_L.\forall{B}\subseteq{C},
X1,X2...,XL.∀B⊆C,,所有样本集的粒球
G
B
j
.
GB_j.
GBj.关于条件属性子集
B
,
B,
B,决策属性集
D
D
D,给出上近似集,下近似集定义和生成下近似集为:
算法
文章一般为了更加直观的描述算法,就会使用图和伪代码表,这比枯燥的公式和文字更加有易读性。伪代码具有以下特点:
- 需要说明输入、输出;
- 方法 (函数) 名可写可不写, 如果被别的方法调用就必须写;
- 需要写出主要步骤的注释;
- 长度控制在 15-30 行;
- 可使用数学式子或对已有数学式子的引用;
- 不重要的步骤可以省略;
- 一般需要进行时间、空间复杂度分析, 并写出配套的 property 以及相应的表格, 以使其更标准.
伪代码部分如下图为例。

五、实验
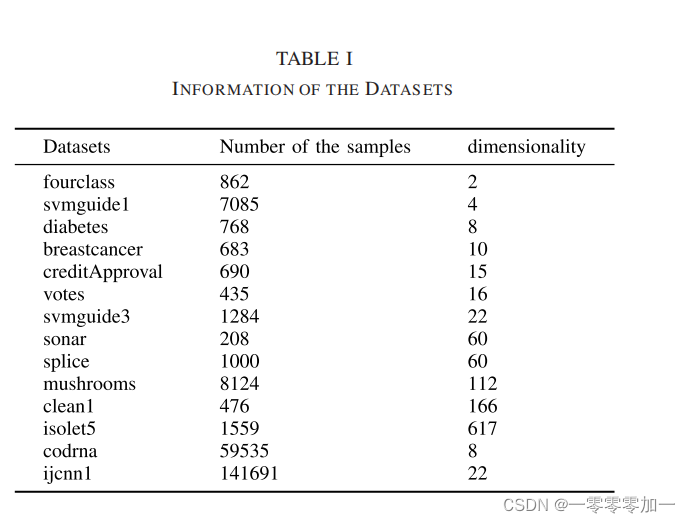
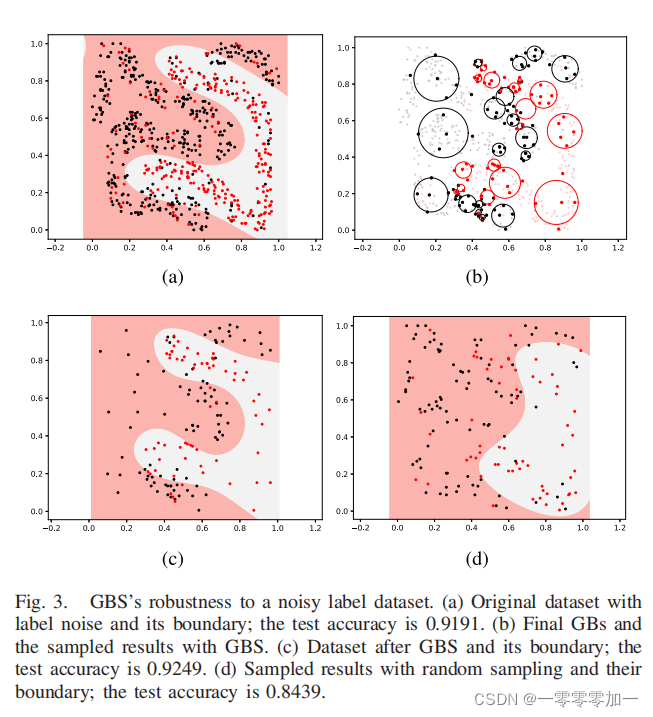
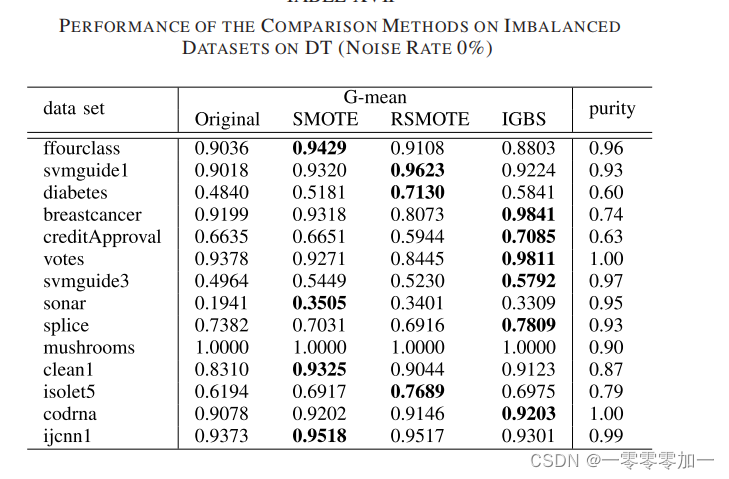
实验部分需要详细的说明数据集,实验环境等。描述数据集可以用一个表格,这样更加直观,也可以进行图形化展示,然后用文字对表格和图片进行解释说明。有对比实验的,也要用表格表示实验结果。这部分可以多放一些实验结果图和对比图。如:
数据集:
实验效果对比图
实验数据结果
六、结论
结论是对文章的总结,要和前面相呼应。除了总结外,还应该加上文章中的一些不足,也要写在未来将做的进一步研究。注意以下几点:
- 结论一般不要太长, 5 句就够了;
- 避免使用与摘要内相同的句子. 摘要里面说我们做了哪些事情, 而这里应该说我们获得哪些观察与结论. 也就是说, 结论比摘要更加具体;
- 如果要讨论说进一步工作, 可以列出 3 至 5 条;
如:This article presents a novel sampling method called GBS.It can alleviate the impact of label noise on noisy label classification and the imbalance on imbalanced classification.In addition, as a general sampling method not designed for any specific dataset or classifier, GBS performs better than the random sampling method. The experimental results demonstrate the effectiveness and efficiency of GBS. Instead of inputting a granular ball in [18], the GBS can be seen as another way
to realize granular-ball computing. The GBS uses the real data points to describe granular balls, which can decrease the loss of distribution information in comparison to that directly using granular balls. Despite these advantages, GBS could lose the original data distribution to some extent. Therefore, in the future, we will further improve the generation method for both the GBs and sampled points. In addition, the GBS method can be developed into stream data mining methods, such as kernel density estimation .
以上的总结,第一句总结性概括本文的主要贡献,提出了一个抽样算法。接下来的2,3,4句描述了该算法的详细工作内容,包括应用场景,优势,实验对比等方面。最后一句是对未来工作的展望,之后工作的开展。
七、致谢
本文所记录的写作规范,大部分由闵帆老师讲授。感谢闵老师的细心教导,无私奉献,让我们受益匪浅,在论文写作中少踩坑,少走弯路。
参考文献
[1] S. Xia, S. Zheng, G. Wang, X. Gao and B. Wang, “Granular Ball Sampling for Noisy Label Classification or Imbalanced Classification,” in IEEE Transactions on Neural Networks and Learning Systems, doi: 10.1109/TNNLS.2021.3105984.
[2] Xia S , Zhang Z , Li W , et al. GBNRS: A Novel Rough Set Algorithm for Fast Adaptive Attribute Reduction in Classification[J]. IEEE Transactions on Knowledge and Data Engineering, PP(99):1-1.

















 1288
1288

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









