







 Inverted Multi-Index简介Inverted Multi-index是Artem Babenko 和 Victor Lempitsky发表的一篇论文,论文起初发表在CVPR2012上,后来又增加了内容,又发表在2014的PAMI上,被引用的次数很高。 论文地址如下所示: CVPR2012 PAMI 2014引言分析整篇文章,总结下来想法还是很直观。首先分析传统的倒排索引,在传统
Inverted Multi-Index简介Inverted Multi-index是Artem Babenko 和 Victor Lempitsky发表的一篇论文,论文起初发表在CVPR2012上,后来又增加了内容,又发表在2014的PAMI上,被引用的次数很高。 论文地址如下所示: CVPR2012 PAMI 2014引言分析整篇文章,总结下来想法还是很直观。首先分析传统的倒排索引,在传统
Inverted Multi-Index
简介
Inverted Multi-index是Artem Babenko 和 Victor Lempitsky发表的一篇论文,论文起初发表在CVPR2012上,后来又增加了内容,又发表在2014的PAMI上,被引用的次数很高。
论文地址如下所示:
CVPR2012
PAMI 2014
引言
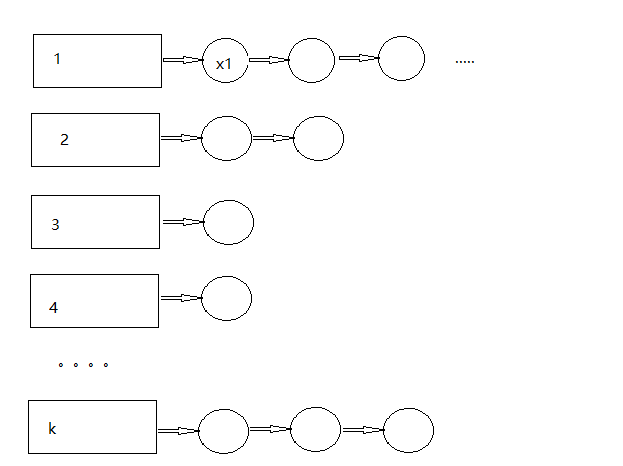
分析整篇文章,总结下来想法还是很直观。首先分析传统的倒排索引,在传统的倒排索引中,我们这样做:
- 首先N个M维的数据,首先进行K-means聚类,会生成K个聚类
- 将原始的每个M维的数据分别和K个聚类中心进行比较,然后找出距离最小的聚类。
- 会生成如下所示的索引结构,方框代表聚类中心,圆代表聚类中同一类的数据。
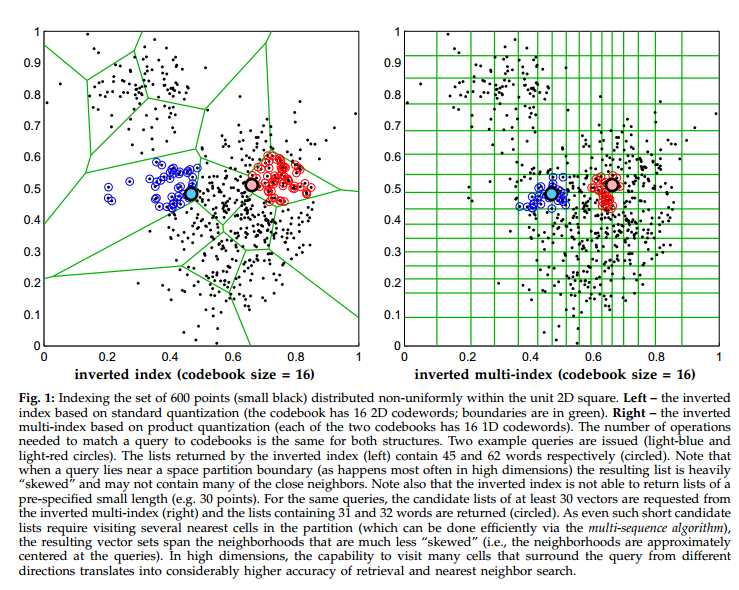
但是原始的倒排索引是在全维度上进行聚类,qurey时候先计算与聚类中心centroids的距离,然后计算centroids内的database与query的距离,避免了O(n)的搜索规模。然而,如果数据比较分散,没有出现明显的数据簇,直接进行聚类,数据将会非常稀疏。导致在查询的过程中,会只关注centroids内的点,然而忽视了实际很近的数据点。如下图所示:
所以,在论文中作者提出了一种新型的索引结构,将原始的数据进行维度划分,然后在各个维度中进行K-means聚类,将database中的数据映射到各个空间的centroids上,query时通过计算数据与database的centroids距离进行排序,返回K个紧邻。进行这种划分,一个最大的优势就是,采用了更精细的子空间划分,提高了检索的召回率。
Iverted Multi-Index
受到product quantization的思想启发,作者将原始的数据N×M维数据 D={ p1,p2,p3,.......pn} ,分别划分为两个N×M/2维的数据。假设 pi=[p1i,p1j] ,其中 pi∈RM 。我们现在讲数据集进行划分为两部分, p1i∈RM
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3684
3684











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









