







 本文介绍了Artem Babenko和Victor Lempitsky在CVPR2012发表的关于倒排多项索引(inverted multi-index)的研究,用于提升近似最近邻搜索的效率。传统倒排索引在数据无明显聚类时效果不佳,而倒排多项索引通过在每个维度上进行KMeans划分,实现了更精确的子空间细分。在查询时,使用multi-sequence算法高效输出top-k结果,解决了排序问题。该技术在行人计数等领域有重要应用。
本文介绍了Artem Babenko和Victor Lempitsky在CVPR2012发表的关于倒排多项索引(inverted multi-index)的研究,用于提升近似最近邻搜索的效率。传统倒排索引在数据无明显聚类时效果不佳,而倒排多项索引通过在每个维度上进行KMeans划分,实现了更精确的子空间细分。在查询时,使用multi-sequence算法高效输出top-k结果,解决了排序问题。该技术在行人计数等领域有重要应用。
Artem Babenko and Victor Lempitsky,CVPR2012,被引用次数:43。发现V. Lempitsky是“Learning to Count Objects in Images”的作者,传说这是一篇行人计数必读文章。行人计数的文章是V. Lempitsky在Oxford VGG组做的,本文是在Yandex(俄罗斯的Google)。
阅读时间:2015-04-23
ANN,文章follow了PQ方法(见我另一篇博文),大致意思是对原始数据进行维度划分,在各子空间上分别做k-means,将database中的每个数据映射到各子空间的centroid上,query时通过计算数据与database的centroid距离进行排序,子空间距离度量用欧式公式,总维度上的距离采用子空间距离的第二范式。文章介绍了一种新的数据结构,称之为inverted multi-index,能产生更加精细的子空间划分,且与inverted index相比并不增加检索和预处理的耗时。本文的区别主要体现在两个方面:
- 维度划分时仅划分为2个子空间,计算总维度的距离采用第一范式;
- rank时并不排序,而是用基于优先队列multi-sequence算法,高效输出top-k检索结果。
inverted index VS inverted multi-index

文章上手讨论了普通倒查表与多项倒查表的区别。普通ANN,用KMeans在全维度上聚类,query时计算向量与centroids距离,然后再计算centroids内database与query的距离,从而避免O(N)的搜索规模。但对散列database,没有明显簇的数据,强行KMeans将导致样本划分很糟糕(簇内数据方差很大),从而在query时丢失实际很近的数据点,如上图。这里可能会想到用Multiple Assignment减少误差,但该方法也有自身的缺点(超出论文)。然后文章提出可以分别对各维度做KMeans,图中交错的网格是分对横向、纵向进行低维KMeans划分。query时,各维度计算centroids,检索multiple inverted,能获得准确的邻近点。
Inverted Multi-Index
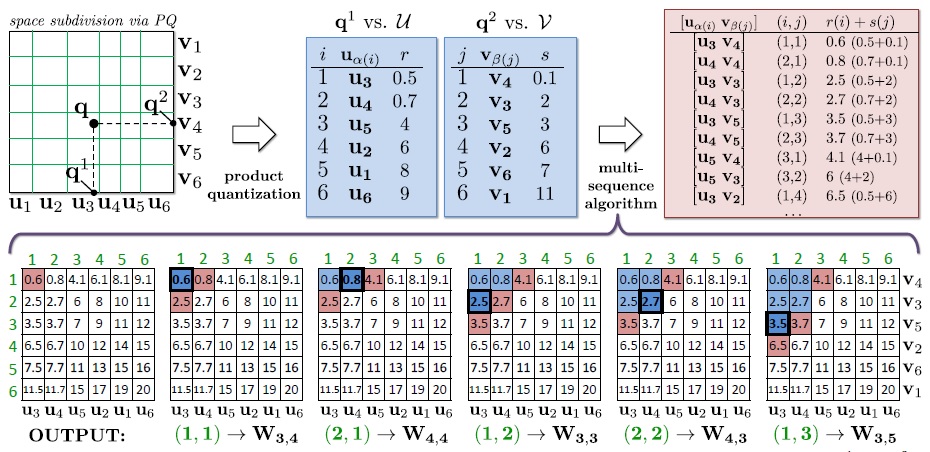
上图展示了文章算法的整个过程:query时,将数据的维度均分成两个子空间,分别进行量化,形成向量 [p1
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3638
3638

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









