






A Transformer-based Framework for Multivariate Time Series Representation Learning(KDD2022)
提出了一种基于transformer编码器结构的多元时间序列表示学习新框架。该框架包括一个无监督的训练前计划,它可以在下游任务上提供比完全监督学习更大的性能优势,即使不利用额外的无标记数据,也就是说,通过重用现有的数据样本。在多个不同领域和具有不同特征的公共多元时间序列数据集上评估我们的框架,我们证明它的性能明显优于目前可用的最佳回归和分类方法,即使是对仅包含几百个训练样本的数据集。考虑到无监督学习在科学和工业的几乎所有领域的显著兴趣,这些发现代表了一个重要的里程碑,提出了第一个无监督方法,被证明是推动多元时间序列回归和分类的最先进性能的极限
背景:在这项工作中,我们首次研究了将transformer编码器用于多元时间序列的无监督表示学习,以及用于时间序列回归和分类的任务。据我们所知,这也是无监督学习第一次被证明在多元时间序列的分类和回归方面优于有监督学习,即使不使用额外的未标记数据样本
总结:对文中提出的模型 不是很清楚,transformer encoder内部结构 ;其次存在大量学习时间序列无监督表征模型,这个模型在结构上到底和这类模型设计有什么区别。
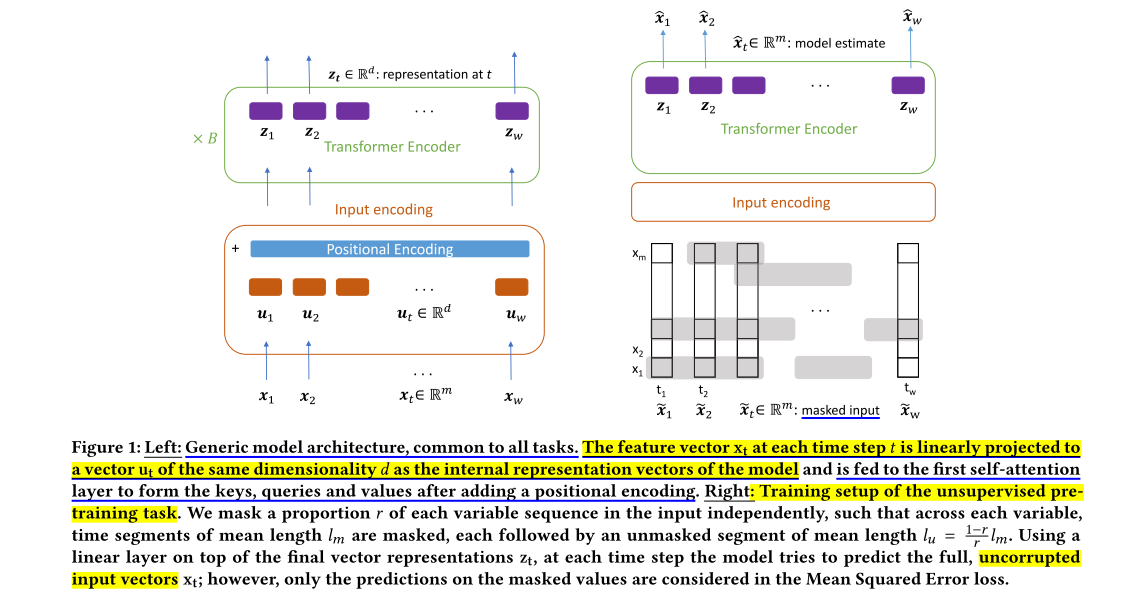
框架:















 1110
1110











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









