







多元时间序列(MTS)分类在许多领域和实际应用中都是一项具有挑战性和重要性的任务。之前关于MTS的大部分工作大致可以分为基于神经网络(NN)和基于模式的方法。前者可以带来鲁棒的分类性能,但许多生成的模式具有挑战性;而后者通常产生可解释的模式,可能对分类任务没有帮助。本文提出一种基于强化学习(RL)的模式挖掘框架(RLPAM),以识别MTS分类中可解释但重要的模式。该框架已被30个基准数据集以及真实世界的大规模电子健康记录(EHRs)验证,以完成一项极具挑战性的任务:败血症休克早期预测。RLPAM在30个数据集中的14个以及ehr上的表现优于最先进的基于nn的方法。最后,展示了强化学习的模式如何可以被解释,并可以提高我们对脓毒性休克进展的理解。
阅读者总结:这篇论文很有新颖点,时间序列分类可解释性+强化学习。值得学习
方法:
我们提出一个强化学习(RL)通知模式挖掘(RLPAM)框架来识别MTS分类中可解释但重要的模式。RLPAM结合了深度RL (DRL)和Toeplitz逆协方差聚类(TICC),以解决现有基于模式的方法的局限性和缺点,同时保留其原始的可解释性
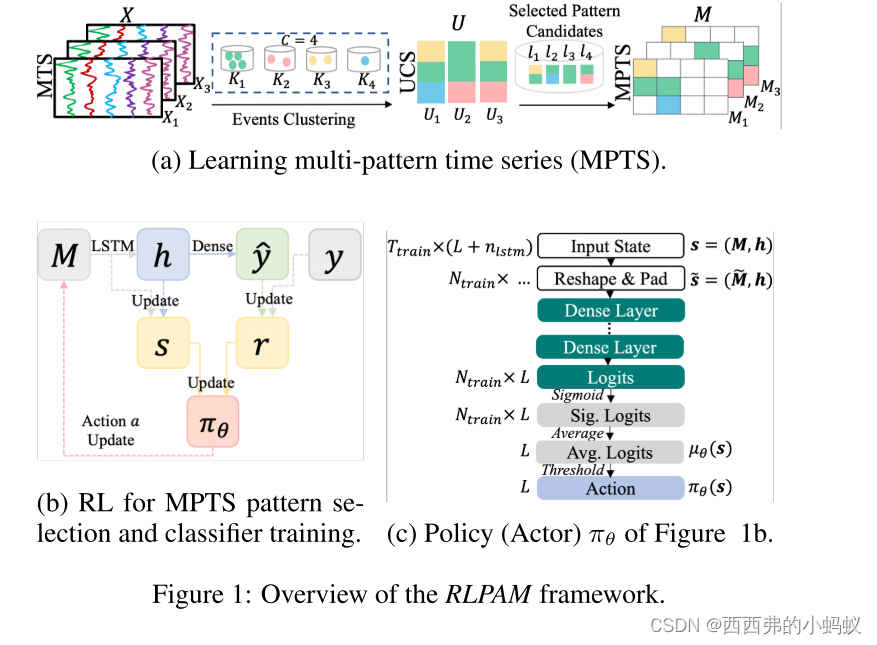
我们的RLPAM框架的概述如图1所示。首先将MTS编码为单变量聚类序列(univariate cluster sequences, UCS),然后利用从UCS中提取的候选模式学习多模式时间序列(multi-pattern time series, MPTS),并通过强化学习模块从中识别出有鉴别能力的模式,同时训练分类模型。


Modeling with RL

















 14万+
14万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









