







由于维数灾难的影响,高维空间中的最近邻(NN)搜索本质上是计算开销巨大的。局部敏感哈希(locality-sensitive hashing, LSH)是一种著名的近似神经网络搜索算法,能够以恒定概率在亚线性时间内回答c-近似神经网络(c-ANN)查询。现有的LSH方法主要基于哈希桶建立索引,以便快速地检索候选点。然而,现有的粗粒度结构无法为候选点提供准确的距离估计,这意味着在检查不必要的点时需要额外的计算开销。这反过来又会降低查询处理的性能。相比之下,本文提出了一种快速准确的LSH框架PM-LSH,旨在在大规模、高维数据集上计算cANN查询。首先,采用一种简单有效的pm树对数据点进行索引;其次,我们开发了一个可调的置信区间,以实现准确的距离估计,并保证高结果质量。第三,提出了一种基于pm树的高效算法来提高计算c-ANN查询的性能。真实数据上的大量实验表明,PM-LSH在效率和精度方面都优于现有的方法。
阅读者总结:这篇论文是2020 VLDB的最佳论文之一。这篇论文在理论证明方面很严谨,提出的算法在解决高维数据点近似查询方面具有启发性。1)利用投影方法,将高维空间中的点投影到低维空间中,同时保留在高维空间的相近性 2)实现了一个置信区间可调方法,提高估计精度 3)创建了一个PM树,实现近似性查询。
这篇论文值得学习,在理论证明和相关算法的分析方面,做了很详细的对比,提出采用PM-LSH算法的合理性。
问题:
方法:本文提出一种快速准确的LSH框架PM-LSH,用于在大规模高维数据集上计算c-ANN查询。该框架由数据划分、距离估计和点探测3个部分组成。首先,采用简单有效的pm树[30]对投影空间中的点进行索引;其次,利用任意两点间投影距离与原始点到投影距离之间的强相关性,在给定的原始点到投影距离的基础上建立一个可调的置信区间,以提高距离估计精度;第三,提出了一种高效的搜索pm树的算法,该算法通过一系列半径越来越大的范围查询来实现。与现有的LSH方法相比,PM-LSH能够同时实现高效率和高精度



AWay of Probing
接着介绍了现有LSH方法的统一框架,如图2所示,由数据划分、距离估计和点探测三个部分组成。


1 )Data Partitioning
现有的LSH方法通过哈希函数将数据点映射到投影空间后,采用"分治"的方式将投影空间划分为子空间。当发出查询时,会探测可能包含结果的区域,最后合并并返回这些区域的结果。在现有的LSH方法中,通常有两种数据划分方法:
(1) Interval based Partitioning. 基本的LSH基于G(o)构造哈希桶,每个桶可以看作是一个边长w相等的m维超立方体。
(2) Metric Space Partitioning. SRS使用r -树来索引投影空间中的所有点,这样就支持增量kNN搜索。 对于内存处理,它也可以使用覆盖树(Cover Tree)。在PM-LSH中,我们使用PM-tree对投影空间进行划分,从而支持高效的范围查询。
2)Distance Estimation 为了准确估计距离,从距离估计器和估计粒度两个方面考虑。
(1) Distance Estimator.


(2) Estimation Granularity. Distance estimation methods may use different granularities:(i) Bucket to Bucket.(ii) Point to Bucket. (iii) Point to Point.
3)Point Probing.
假设我们探查T点。在基于哈希桶的索引方法中,如Multi-Probe、LSBtree和C2LSH,我们直接探测桶中的点,时间开销为O(T)。第二种方法是QALSH,它搜索B+-树中的点。时间开销为O(log n + T)。与前两种方法不同的是,SRS用r -树来索引点,并在投影空间中迭代寻找下一个NN。
我们的PM-LSH可以看作是第二种和第三种方法的组合,因为我们在投影空间中构建pm -树,并执行范围查询来检索点。
4. THE PM-LSH FRAMEWORK
我们继续介绍PM-LSH框架的细节。如前所述,RE方法通过扩大搜索半径来快速探测存储在哈希桶中的点,但由于索引结构粗粒度,存在距离估计不准确的问题,这将导致在检查不必要的点时产生计算开销。相反,MI方法用r树索引点,并迭代地返回投影空间中与q最近的点。然而,在r树中找到下一个精确神经网络的计算成本也很高,而且下一个神经网络不一定是原始空间中的最佳下一个候选神经网络。为了兼顾二者的优点,PM-LSH方法结合了RE和MI方法的思想,采用PM-tree代替R-tree来索引投影空间中的点,并执行一系列半径越来越大的范围查询,从而实现了效率和精度的兼顾。接下来,我们简要介绍如何构建pm树。
然后,分析了pm树和r树的代价模型,以了解在相应的范围查询负载下,pm树的性能如何优于r树。最后,给出了算法的具体实现。
4.1 Building a PM-tree in the Projected Space


例3。如图4所示,我们选择o1和o11作为枢轴,采用球分区的方式对空间进行分区,如图4(a)所示。内部节点e1、e2、···、e6包含超球区域内的点,它们的中心和半径被保存为入口的一部分。当执行范围查询range(q, 2)时,我们在访问内部节点时检查剪枝条件。这里只检查了e4和e6。最后,我们返回{o14}作为结果。
4.3 Tunable Confidence Interval

根据引理3,我们建立了原始距离和投影距离置信区间之间的强关系,可用于回答(r, c)-BC和c- ann查询

6. EXPERIMENTS




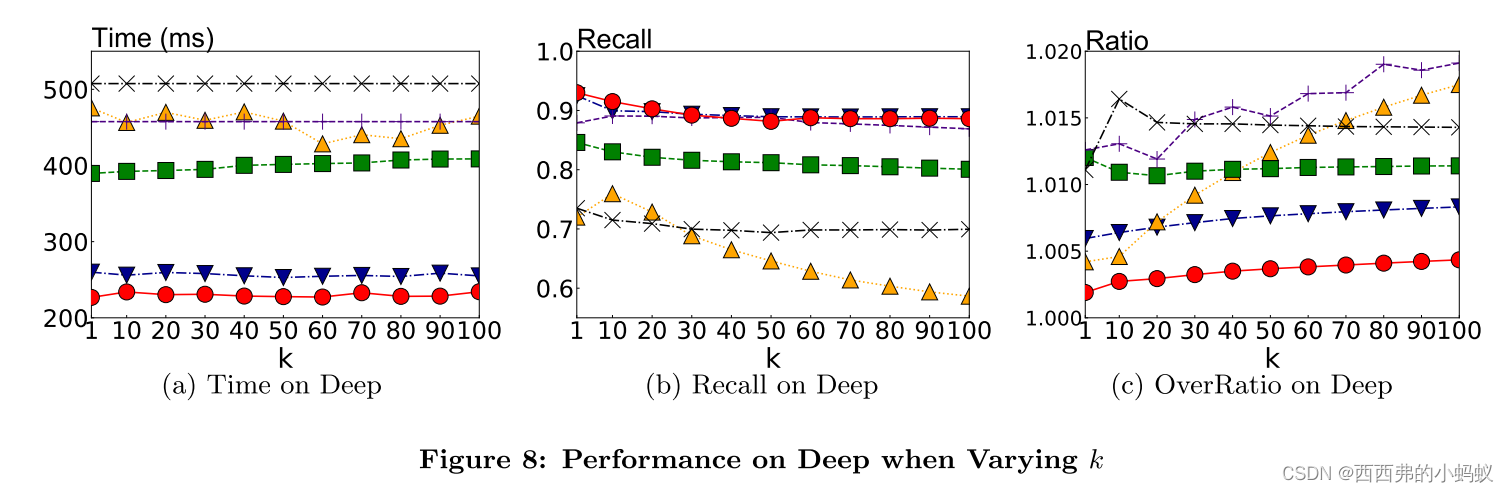



结论:
本文提出一种快速准确的框架PMLSH,用于计算(c, k)-ANN查询,并在理论上保证结果质量。首先,采用pm树在投影空间中索引待查询的数据点;其次,为了提高投影空间中距离估计的精度,根据给定的原始距离建立一个可调的投影距离置信区间。最后,提出了一种有效的PMtree范围查询算法。在7个广泛使用的数据集上的实验结果表明,PM-LSH在查询效率和结果准确性方面均优于5个同类算法。与最接近的竞争对手(SRS)相比,PM-LSH将查询时间平均提高了30%。当所有竞争对手的查询时间大致相同时,PM-LSH比最近竞争对手(SRS)的查全率提高了约10%。















 4879
4879











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









