







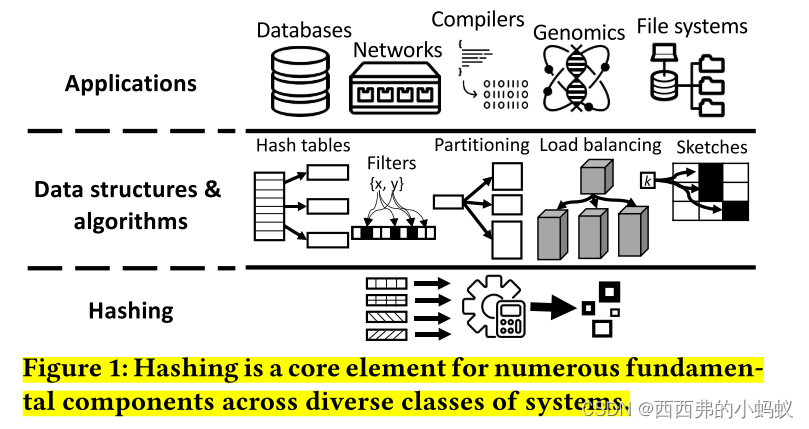
哈希是一种广泛使用的从任意数据中创建均匀随机数的技术。这在很多核心数据驱动的操作中都是必需的,包括索引、分区、过滤器和草图。因此,散列是许多系统的核心组件,包括关系数据系统、键值存储、编译器和网络。由于散列算法的计算量和数据量都很大,它是一个核心系统瓶颈。例如,在标准TPC-H基准测试中,一个典型的数据库查询可能会在散列表上花费总开销的50%。类似地,谷歌在c++散列表上至少花费了其总计算成本的2%,这导致仅一次散列操作每年就会产生巨大的计算成本。
本文提出一种新的哈希方法,称为熵学习哈希,它将哈希的计算成本降低了一个数量级。我们从伪随机的角度来看哈希,我们要问的关键问题是“需要多大的随机性?”最先进的哈希函数做了太多的工作,以至于无法执行其核心任务:从数据源中提取随机性,以创建随机输出。熵学习哈希1)建模并估计输入数据的随机性(熵),然后2)创建特定于数据的哈希函数,该函数只使用需要区分输出的数据部分。由此产生的哈希函数极大地减少了所需的计算量,同时证明了其输出与传统哈希函数的输出相似。测试了不同的核心哈希操作(如哈希表、布隆过滤器和分区)的熵学习哈希,与谷歌和Meta大规模使用的类内最好的哈希函数和实现相比,吞吐量分别提高了3.7倍、4.0倍和14倍。
2 OVERVIEW & MODELING

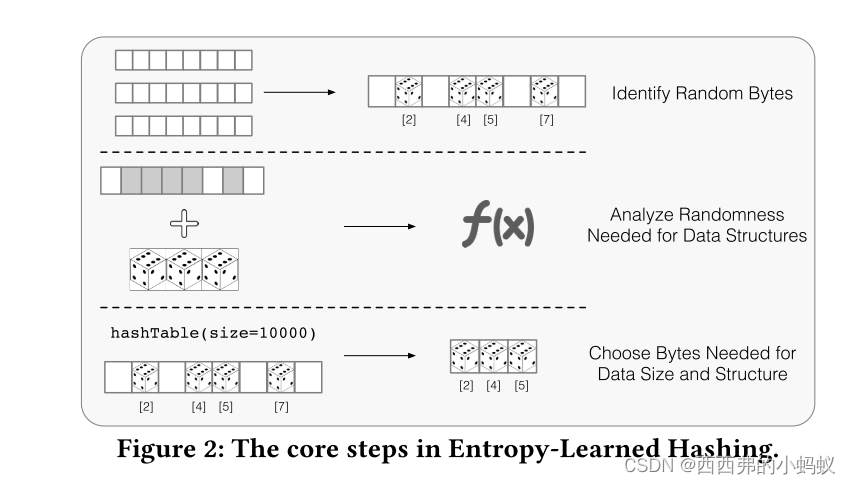
为了创建部分键函数𝐿,Entropy-Learned
哈希使用三个步骤,如图2所示。首先,它分析数据源𝑥并确定哪些字节是高度随机的,以及从𝐿的选择中可以得到多少熵(章节3)。其次,它推理𝐿如何影响数据结构度量(章节4)。最后,它使用运行时信息,如所需的Bloom过滤器或哈希表的大小或分区中的分区数量,以选择在𝐿中使用哪些字节(章节5)。















 3237
3237











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









