










MARS: A Video Benchmark for Large-Scale Person Re-identification
下面是旷世的算法介绍:http://www.sohu.com/a/207091906_418390
(视频震撼)
一些博客对MARS的总结:https://blog.csdn.net/baidu_39622935/article/details/82867177
reid开源代码;https://blog.csdn.net/qq_21997625/article/details/80937939
不论是基于图片还是视频的reid,都是先提取特征,然后再进行度量学习(metric learning)
视频行人重识别:
1)提取特征:传统方法:LOMO特征、HOG3D特征、GEI特征等等
深度学习方法:IDE (ID-discriminative embedding):就是训练一个分类的网络(基于ImageNet进行fine tune),前5层卷积层,6、7是1024个神经元的全连接层,第8层是ID数目的分类层。然后当作分类任务训练网络。训练完成后,用第7层的输出作为提取的特征
实例解析:
对于视频行人重识别,大多是把视频序列按帧来处理,MARS这篇文章提出了先把视频序列图片分成若干小块8*8*6,分块提取HOG3D特征(96维),对于一个视频序列因长度不同,势必结果是ni * 96。然后作者通过词袋模型将其变成了2000维的特征,对不同长度的视频均可。
在MARS这篇文章提出的第二种IDE特征方法中,作者把一个视频序列的每一帧都送入CNN提取一个特征,然后将所有帧的特征进行pooling获得一个代表视频序列的特征(MARS和PRID用max pool, iLIDS用avg pool)。
2)度量学习:KISSME、XQDA等,效率和准确率都很高
摘要
This paper considers person re-identification (re-id) in videos.
We introduce a new video re-id dataset, named Motion Analysis and Re-identification Set (MARS), a video extension of the Market-1501 dataset.
To our knowledge, MARS is the largest video re-id dataset to date.
Containing 1,261 IDs and around 20,000 tracklets, it provides rich visual information compared to image-based datasets.
Meanwhile, MARS reaches a step closer to practice.
The tracklets are automatically generated by the Deformable Part Model (DPM) as pedestrian detector and the GMMCP tracker.
A number of false detection/tracking results are also included as distractors which would exist predominantly in practical video databases.
Extensive evaluation of the state-of-the-art methods including the space-time descriptors and CNN is presented.
We show that CNN in classification mode can be trained from scratch using the consecutive bounding boxes of each identity.
The learned CNN embedding outperforms other competing methods significantly and has good generalization ability on other video re-id datasets upon fine-tuning.
本文考虑了视频中的人员再识别(reid)问题。
我们介绍了一个新的视频reid数据集,名为运动分析和重新识别集(MARS),是Market-1501 datase数据集的视频扩展。
据我们所知,MARS是迄今为止最大的视频reid数据集。
它包含1,261个id和大约20,000个tracklet,与基于图像的数据集相比,它提供了丰富的视觉信息。
与此同时,火星离实践又近了一步。
轨迹由变形部件模型(DPM)作为行人检测器和GMMCP跟踪器自动生成。
一些错误的检测/跟踪结果也包括作为干扰,这将主要存在于实际的视频数据库。
广泛评价了包括时空描述符和CNN在内的最先进的方法。
我们证明,在分类模式下,CNN可以使用每个标识的连续包围框从零开始进行训练。
学习到的CNN嵌入方法在性能上明显优于其他竞争方法,并且经过微调后对其他视频reid数据集具有较好的泛化能力。
INTRODUCTION
With respect to the “probe-to-gallery” pattern, there are four re-id strategies:
image-to-image, image-to-video, video-to-image, and video-to-video.
Among them,the first mode is mostly studied in literature, and previous methods in image-
based re-id [5,24,35] are developed in adaptation to the poor amount of training data.
对于“probe-to-gallery”模式,有四种reid策略:
图像到图像,图像到视频,视频到图像,视频到视频。
其中,第一种模式在文献中研究较多,以往的方法多用于图像-
基于reid[5,24,35]的开发是为了适应少量的训练数据。
The second mode can be viewed as a special case of “multi-shot”,
and the third one involves multiple queries.
Intuitively, the video-to-video pattern, which is our focus in this paper, is more favorable because both probe and gallery units contain much richer visual information than single images.
Empirical evidences confirm that the video-to-video strategy is superior to the others (Fig. 3).
第二种模式可以看作是“多镜头”的特殊情况,第三种模式涉及多个查询。
直观地说,我们在本文中关注的视频对视频模式更有利,因为探针和图库单元都包含比单个图像丰富得多的视觉信息。
实证证明,视频对视频策略优于其他策略(图3)。
Currently, a few video re-id datasets exist [4, 15, 28, 36].
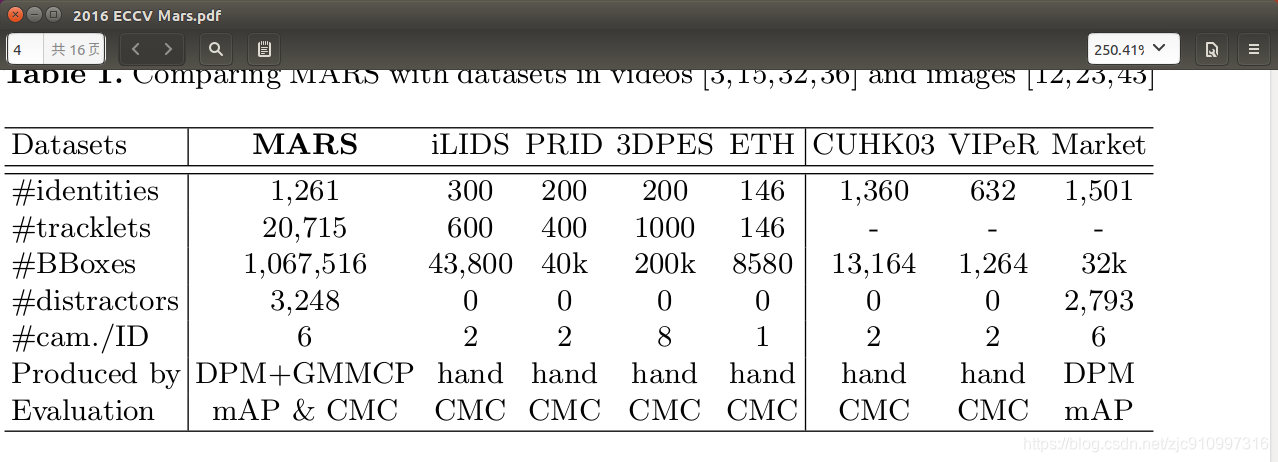
They are limited in scale: typically several hundred identities are contained, and the number of image sequences doubles (Table 1).
Without large-scale data, the scalability of algorithms is less-studied and methods that fully utilize data richness are less likely to be exploited.
In fact, the evaluation in [43] indicates that re-id performance drops considerably in large-scale databases.
目前,存在一些视频reid数据集[4,15,28,36]。
它们在规模上是有限的:通常包含几百个标识,图像序列的数量是原来的两倍(表1)。
没有大规模数据,算法的可扩展性研究较少,充分利用数据丰富性的方法被利用的可能性较小。
事实上,[43]中的评估表明,在大型数据库中,reid性能会大幅下降。
Moreover, image sequences in these video re-id datasets are generated by hand-drawn bboxes. This process is extremely expensive, requiring intensive human labor.
And yet, in terms of bounding box quality, hand-drawn bboxes are biased towards ideal situation, where pedestrians are well-aligned.
But in reality, pedestrian detectors will lead to part occlusion or misalignment which may have a non-ignorable effect on re-id accuracy [43].
Another side-effect of hand-drawn box sequences is that each identity has one box sequence under a camera.
This happens because there are no natural break points inside each sequence.
But in automatically generated data, a number of tracklets are available for each identity due to miss detection or tracking.
As a result, in practice one identity will have multiple probes and multiple sequences as ground truths. It remains unsolved how to make use of these visual cues.
此外,这些视频reid数据集中的图像序列是由手绘bbox生成的。这个过程非常昂贵,需要大量的人力。
然而,就边界盒的质量而言,手工绘制的bbox偏向于理想的情况,即行人排列良好。
但在现实中,行人检测器会导致部分遮挡或不对准,这可能会对reid准确率[43]产生不可忽视的影响。
手绘框序列的另一个副作用是,每个标识在摄像机下都有一个框序列。
这是因为在每个序列中没有自然断点。
但是在自动生成的数据中,由于丢失检测或跟踪,每个标识都有许多tracklet可用。
因此,在实践中,一个身份将有多个探针和多个序列作为基本事实。如何利用这些视觉线索仍未解决。
In light of the above discussions, it is of importance to 1) introduce large-scale and real-life video re-id datasets and
2) design effective methods which fully utilizes the rich visual data.
To this end, this paper contributes in collecting and annotating a new person re-identification dataset, named “Motion Analysis and Re-identification Set” (MARS) (Fig. 1).
Overall, MARS is featured in several aspects.
First, MARS has 1,261 identities and around 20,000 video sequences, making it the largest video re-id dataset to date.
Second, instead of hand-drawn bboxes, we use the DPM detector [11] and GMMCP tracker [7] for pedestrian detection and tracking, respectively.
Third, MARS includes a number of distractor tracklets produced by false detection or tracking result. Finally, the multiple-query and multiple-ground truth mode will enable future research in fields such as query re-formulation and search re-ranking [45].
综上所述,1)引入大规模的真实视频reid数据集,
2)设计充分利用丰富的视觉数据的有效方法是非常重要的。
为此,本文致力于收集并标注一个新的人再识别数据集,名为“运动分析与再识别集”(MARS)(图1)。
总的来说,火星有几个特点。
首先,MARS拥有1,261个身份和大约20,000个视频序列,是迄今为止最大的视频reid数据集。
其次,我们使用DPM检测器[11]和GMMCP tracker[7]分别进行行人检测和跟踪,而不是手绘bbox。
第三,MARS包含了一些由错误检测或跟踪结果产生的干扰轨迹。最后,多查询、多地面真值模式将使查询重构、搜索重排名[45]等领域的研究成为可能。
Apart from the extensive tests of the state-of-the-art re-id methods, this paper evaluates two important features:
1) motion features including HOG3D [18] and the gait [13] feature, and
2) the ID-disciminative Embeddings (IDE) [46], which learns a CNN descriptor in classification mode.
Our results show that although motion features achieve impressive results on small datasets, they are less effective on MARS due to intensive changes in pedestrian activity.
In contrast, the IDE descriptor learned on the MARS training set significantly outperforms the other competing features, and demonstrates good generalization ability on the other two video datasets after fine-tuning.
除了对最先进的reid方法进行了广泛的测试外,本文还评估了两个重要特征:
1)运动特征包括HOG3D[18]和步态[13]特征,和
2) id - minative embedded (IDE)[46],在分类模式下学习CNN描述符。
我们的结果显示,尽管运动特征在小数据集上取得了令人印象深刻的结果,但由于行人活动的剧烈变化,它们在火星上的效果不太好。
相比之下,MARS训练集学习到的IDE描述符在性能上明显优于其他竞争特征,并且经过微调后,在另外两个视频数据集上表现出了良好的泛化能力。
3 MARS dataset
3.1 Dataset Description
In this paper, we introduce the MARS (Motion Analysis and Re-identification Set) dataset for video-based person re-identification.
It is an extension of the Market-1501 dataset [43].
During collection, we placed six near-synchronized cameras in the campus of Tsinghua university. There were five 1,080 × 1920 HD cameras and one 640 × 480 SD camera.
MARS consists of 1,261 different pedestrians whom are captured by at least 2 cameras.
本文介绍了基于视频的人再识别的MARS(运动分析与再识别集)数据集。
它是Market-1501数据集[43]的扩展。
在采集过程中,我们在清华大学校园内放置了6台近乎同步的相机。有五个1080×1920高清摄像机和一个640×480 SD相机。
火星由1261个不同的行人组成,他们被至少两个摄像头捕捉到。
For tracklet generation, we first use the DPM detector [11] to detect pedestrians.
Then, the GMMCP tracker [7] is employed to group overlapping detection results in consecutive frames and fill in missing detection results.
As output, a total of 20,715 image sequences are generated.
Among them, 3,248 are distractor tracklets produced due to false detection or tracking results, which is close to practical usage.
Overall, the following features are associated with MARS.
对于tracklet的生成,我们首先使用DPM检测器[11]来检测行人。
然后,利用GMMCP tracker[7]将重叠检测结果分组到连续帧中,填充缺失检测结果。
作为输出,总共生成20,715个图像序列。
其中有3248条是由于错误检测或跟踪结果而产生的干扰轨迹,接近实际应用。
总的来说,以下特征与 MARS有关。
First, as shown in Table 1, compared with iLIDS-VID and PRID-2011, MARS has a much larger scale: 4 times and 30 times larger in the number of identities and total tracklets, respectively.
首先,如表1所示,与iLIDS-VID和pri -2011相比,MARS的规模要大得多:分别是identity和total tracklets的4倍和30倍。
Second, the tracklets in MARS are generated automatically by DPM detector and GMMCP tracker, which differs substantially from existing datasets:
the image sequences have high quality guaranteed by human labor.
The detection/tracking error enables MARS to be more realistic than previous datasets.
Moreover, in MARS, to produce “smooth” tracklets, we further apply average filtering to the bbox coordinates to reduce localization errors.
As we will show in Section 5.3, tracklet smoothing improves the performance of motion features.
其次,火星上的轨迹是由DPM检测器和GMMCP tracker自动生成的,与现有数据集有很大的区别:
图像序列具有高质量的人工保证。
检测/跟踪错误使火星比以前的数据集更真实。
此外,在火星上,为了产生“平滑”的轨迹,我们进一步对bbox坐标进行平均滤波,以减少定位误差。
正如我们将在5.3节中展示的,轨迹平滑改善了运动特性的性能。
Third, in MARS, each identity has 13.2 tracklets on average.
For each query, an average number of 3.7 cross-camera ground truths exist;
each query has 4.2 image sequences that are captured under the same camera, and can be used as auxiliary information in addition to the query itself.
As a result, MARS is an ideal test bed for algorithms exploring multiple queries or re-ranking methods [45].
Fig. 3.1 provides more detailed statistics.
For example, most IDs are captured by 2-4 cameras, and camera-2 produces the most tracklets.
A large number of tracklets contain 25-50 frames, and most IDs have 5-20 tracklets.
第三,在MARS,上,每个id平均有13.2条轨迹。
对于每个查询,平均有3.7个跨摄像机的基本事实存在;
每个查询都有4.2个图像序列,这些图像序列是在同一摄像机下捕获的,可以作为查询本身之外的辅助信息。
因此,MARS是探索多个查询或重新排序方法[45]的算法的理想测试平台。
图3.1给出了更详细的统计数据。
例如,大多数id由2-4个摄像头捕获,camera-2产生的轨迹最多。
大量的tracklets包含25-50帧,大多数id有5-20个tracklets。
3.2Evaluation Protocol
4 Important Features
4.1 Motion Features
The HOG3D [18] feature has been shown to have competitive performance in action recognition [22].
In feature extraction, given a tracklet, we first identify walking cycles using Flow Energy Profile (FEP) proposed in [36].
For bboxes aligned in a cycle, we densely extract HOG3D feature in 8 × 8 × 6 (or 16 × 16 × 6) space-time patches, with 50% overlap between adjacent patches.
The feature dimension of each space-time patch is 96.
Since videos with different time duration have different numbers of the dense space-time tubes, we encode the local features into a Bag-of-Words (BoW) model.
Specifically, a codebook of size 2,000 is trained by k-means on the training set.
Then, each 96-dim descriptor is quantized to a visual word defined in the codebook.
So we obtain a 2,000-dim
BoW vector for an arbitrary-length video.
We do not partition the image into horizontal stripes [43] because this strategy incurs larger feature dimension and in our preliminary experiment does not improve re-id accuracy.
HOG3D[18]在动作识别[22]中表现出了较好的性能。
在特征提取中,给定一个轨迹,我们首先利用[36]中提出的流能剖面(FEP)识别行走周期。
bboxes一致的周期,我们人口提取HOG3D特性在8×8×6(或16×16×6)时空的补丁,有50%的重叠相邻的补丁。
每个时空块的特征维数为96。
由于不同时间长度的视频具有不同数量的密集时空管,我们将局部特征编码为一个词袋(BoW)模型。
具体来说,在训练集上使用k-means对大小为2000的码本进行训练。
然后,将每个96-dim描述符量化为码本中定义的可视单词。
所以我们得到了2000个dim
任意长度视频的弓向量。
我们不将图像分割成水平条状的[43],因为这种策略需要更大的特征维数,而且在我们的初步实验中并没有提高reid的精度。
1


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











