







 博客围绕动物育种展开,介绍了育种框架,包括确定目标、采集信息等一系列活动。还阐述了育种值估计方法,如大众做法、动物模型和基因组选择。其中,基因组选择可在无自身表现或大量后代表现时准确估计繁殖价值,具有早期选择和经济效益等优势。
博客围绕动物育种展开,介绍了育种框架,包括确定目标、采集信息等一系列活动。还阐述了育种值估计方法,如大众做法、动物模型和基因组选择。其中,基因组选择可在无自身表现或大量后代表现时准确估计繁殖价值,具有早期选择和经济效益等优势。
动物育种:
1)育种框架
动物育种的基础是父母的特征或多或少地反映在他们的后代身上。这是由于性状或多或少是可遗传的,其中50%的性状是遗传的DNA,包含了动物特征的遗传能力,从父母传给后代。在动物育种中,潜在的亲本是为某些性状而选择的,而最好的亲本确实是作为亲本使用的。通过这种方式,下一代将在基因上得到改进,获得所需的性状。从长期来看,后续的育种活动是在育种计划中进行的。动物育种旨在通过改变其重要性状的遗传能力来改善动物
整个过程:
育种计划的特点是一系列后续活动:确定育种目标,表型登记,基因型和谱系,用遗传模型估计选择性状的育种值,根据估计的育种值选择下一代的亲本,父母的交配和对生产动物的遗传优势的传播以及关于遗传多样性保持和实现选择反应的计划评估。
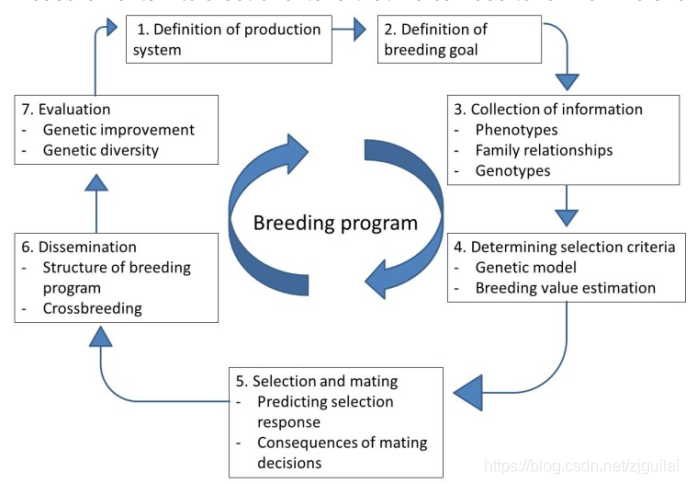
1:Definition of production system(生产系统定义)
首先,设置开始于对生产系统的描述(1)。这方面有什么关系?对于一只只作为伙伴的小狗来说,在舒适的房子里行为和健康是很重要的。对于常年处于恶劣条件下的健康绵羊来说,健康性状和放牧行为是相关的。对于在生产成本高的集约化养殖系统中养殖肉鸡,日生长是决定性的。
2.Definition of breeding goal(定义育种目标)
第二,在下一代中应该改善哪些特征的问题。 育种的目标是什么(2)? 这个问题与我们饲养动物的原因密切相关。 这个过程值得进行彻底的研究和长期的结论,因为动物育种只有在育种目标因此保持了很多代时才有效。 育种目标的例子包括生产特性,产品质量,健康和福利特征,构造特征,运动表现,生育等方面的改进。
3.Collection of informaion(采集信息)
第三,了解育种目标,应收集相关信息(3)。 在这方面相关的是动物的特征(称为表型),其可以帮助确定动物相对于育种目标的价值。 当跳跃表现是马的繁殖目标特征时,收集跳跃数据。 当猪的繁殖力达到繁殖目标时,就会记录出仔猪的性状。 其他相关信息是动物的血统。 动物繁殖就是将遗传能力从一代传递到下一代。 当你想要追踪或影响这种传递遗传性状的过程时,父母 - 后代关系(动物的血统)的登记至关重要。 如今,DNA分析在动物中是可行和实践的,也可用于追踪或影响遗传能力的特征传递过程。
4.Breeding value estimation and selection criteria(育种价值估算和选择标准)
第四,了解育种目标并在记录潜在父母的相关特征后,必须选择哪些动物确实被选为父母(4)以及哪些动物被排除在繁殖之外。 基于遗传模型,估计包括谱系信息的统计模型,特征的育种值。 如今,当动物的DNA信息可用时,它也可用于估计育种值(基因组选择)。 估计的育种值表示动物相对于育种目标的价值:最低的将对育种目标性状产生负面影响,最高的将改善育种目标性状。
5.Selection and mating(选择和交配)
第五,鉴于公顷和水坝的估计育种值,必须实际选择父母(5)。 表型性状具有高于平均估计育种值的亲本将改善下一代的育种目标特征。 例如,当选择具有最高产奶量的奶牛的一组奶牛作为下一代的公牛时,他们的女儿将产生比当前一代奶牛更多的奶。 适当选择父母将在下一代中给出积极的选择反应。 选择在育种目标特征方面创造了进步。 选择父母后,必须另外做出选择:哪个父亲应该与哪个大坝交配? 可以选择例如 根据可用的谱系信息或公牛和水坝的特征。
6.Dissemination of genetic gain(遗传进展的传递)
第六,在许多育种方案中,记录性状的动物数量相对于用于人类目的的动物种群而言相当小。选择反应的传播取决于育种计划的结构。在商业猪和家禽计划中,选择在育种计划的顶部进行,并且通过几个“繁殖代”,将在顶部获得的选择反应传播给产生肉或卵的动物。在养牛繁殖技术中,特别是人工授精技术,有机会产生大量的后代,广泛传播优良动物的基因。选择少数动物可能对人口的特征产生很大影响。在商业育种计划中,例如对于家禽和猪,专业线交叉。选择这些品系的特定性状并在倍增阶段交叉以通过组合每个品系的性状获得具有育种目标性状的杂交后代。
7.Evaluation of results(效果评价)
- 育种知识:
The expression of genes, of their alleles, in the phenotype(基因及其等位基因在表型中的表达)
Key issues in basics of animal breeding(动物育种基础的关键问题)
Collecting phenotypes, monogenic and polygenic traits(收集表型,单基因和多基因性状)
一些动物的特征不需要很多知识或经验来记录。 动物的颜色就是一个很好的例子:例如 在一种兔子中,动物是黑色或棕色的。 您可以将其记录在计算机中,0表示黑色,1表示棕色,1表示黑色,2表示棕色。 在遗传学术语中,这些性状是单基因的:表达由单个基因的等位基因决定。 与颜色一样,一些特征基于非常有限数量的基因,这是导致只能记录有限数量的类别的原因。 动物的许多隐性缺陷是单基因的:一个基因的等位基因决定了表型:健康或受影响。 在统计学上,这些是离散变量,记录在有限数量的类中。 描述兔子品种的特征,你可以计算出x%的动物是黑色的,y%的动物是棕色的。
许多动物的性状是多基因的,由许多基因的作用引起。 许多多基因性状是定量的和连续的,并且可以以公制单位(例如kg,l,mm等)测量。一些性状是连续的,但是在近似线性标度的类别中测量,例如, 动物构象的特征或法官或检查员评估的表现。 他们按比例评分动物的特征,例如 从1-5或1-10。 一些多基因性状如疾病的发生是二元规模的:生病(例如1)或不生病(例如0)
【1】gonetic model
1)Phenotype in a model
表型=基因型+环境 要么P = G + E.这些符号P和G和E是重要的记忆,因为它们非常常用于描述表型,基因型或“环境”。
我们的模型P = G + E中的G非常复杂,因为它具有许多基础组件。这可以建模为:基因型=加性效应+显性效应+上位效应或者G = A + D + I.
Genotype = additive effect + dominance effect + epistatic effect
假设正态分布的由来:
无穷小模型假设所有特征都由无数个基因决定,每个基因都具有无限小的影响。 该假设导致平滑的钟形分布,可由正态分布描述。 这种分布伴随着动物育种理论建立的许多规则
从后面开始:上位效应表明存在相互作用的基因。 例如,如果一个基因需要另一个基因的产物来表达,则会产生所谓的基因途径。 因此,一个基因的表达取决于另一个基因中的等位基因组合。 优势效应表明基因本身的表达取决于该基因中的等位基因组合。 两个隐性基因将导致与一个隐性和一个显性等位基因的不同表达。 加性效应表明基因的作用没有优势和上位效应。 因此,无论基因本身或其他基因的等位基因组合如何。 剩下的是你可以加起来的效果
遗传成分包括三个潜在影响:
上位效应:基因之间的相互作用
优势效应:同一基因的等位基因之间的相互作用
加性效应:纠正后的剩余所有内容相互作用
【2】Next generation: transmission model
.。。。。
【3】 Ranking the animals: an overview of methods
选择性育种的挑战是找到最好的动物作为下一代的父母。 不可能阅读动物的真实遗传潜力,但我们可以估计它。 这种估计的遗传潜力也称为估计育种值(EBV)。 显然,如果有更多或更好的遗传潜力可用指标,估计将更准确。 EBV相对于群体中的平均动物表示。 因此,它表示估计动物比动物平均好多少
1)Mass selection(大众做法)
大规模的选择是基于对动物的表现进行排名。
群体选择的成功与否取决于被选择性状的遗传力。
最基本的方法是根据动物的表型对动物进行排名,并选择最适合繁殖的动物。此方法也称为“质量选择”或“自己选择性能”。例如,你想要繁殖大型兔子,然后根据大小对动物进行排名,并且只使用最大的动物作为下一代的父母。这是一个成功的方法吗?答案将取决于许多事情。您想知道这些最大的动物是否确实是具有最佳遗传潜力的动物。为什么其他人变小了?他们年轻时没有得到适当的喂养吗?或者他们有错误的基因?这些问题的答案在于遗传性。毕竟,这表明您观察到的表型变异有多少是由动物间的遗传变异引起的。高遗传力表明小兔子最有可能是小的,因为它们具有比较大的兔子更低的遗传生长潜力。表型越好表示基因型,您就能越好地识别遗传上最好的动物,因此质量选择的结果就越好。此外,一个重要的先决条件是可以获得自己的表演。
2) Animal Model
然而,如果遗传力低,则质量选择不一定导致选择遗传上最好的动物。此外,如果某些原因的表型不适用于所有动物,例如雄性产奶,那么大规模选择是不够的,因为并非所有动物都具有表型。在这些情况下,我们可以使用相关动物的表型来估计没有表型的动物的育种价值。这是可能的,因为正如我们在关于遗传关系的章节中所看到的,相关动物共享等位基因。关系越密切,共享的等位基因就越多。这种用于在利用相关动物信息的同时估计育种值的模型称为动物模型。重要的先决条件是动物的谱系记录是准确的,因此知道家庭关系没有错误。该方法需要相当多的动物才能准确地估计育种值。动物需要相关和/或保持在相同的环境中以能够解开表型的遗传和环境成分。
在遗传表型缺失的情况下,用动物模型估计育种值是非常有用的,因为与具有表型的动物的遗传关系允许估计没有表型的动物的育种值。但即使有自己的表型,它仍然可以为质量选择增加价值,因为它可以利用有关动物表现的额外信息。这给出了更准确的估计育种值。
动物模型是一个遗传统计模型,它结合了有关的信息
实现对相关动物表型的较好估计,具有一定的育种价值
的动物。
重要的优势是:
- 你并不一定需要每种动物的表现型来估计它
育种值。 - 即使你有表现型,关于相关动物的额外信息也会增加
估计育种值的准确性。
3)Genomic selection(基因型选择)
最后,如果您只在选定数量的动物上收集表型,并且您还对这些动物有详细的基因型,例如60,000个SNP标记,那么您可以将这些信息结合起来估计基因组与表型之间的联系。基本思想是有两组动物:具有详细表型的选择组,也称为参考群体,以及没有那些表型的大群,也称为群体。对参照群体和群体的所有动物进行基因分型。在参考群体中,估计标志物和表型之间的关联。然后,将这些关联与群体中动物的基因型组合以预测其育种值。该方法称为基因组选择。
当表型非常难以测量或昂贵时,基因组选择非常有用。考虑某些与健康相关的特征,在这些特征中,您不希望使动物生病,从而能够测量表型。或者不需要生病的动物的特性,但它们确实需要昂贵的设备,例如CT扫描。基因组选择还使得可以在它们达到年龄之前基于估计的育种值选择动物以自己产生表型。这允许(非常)早期选择,因此可以具有经济效益,以及更快的遗传增益,因为动物可以更早地用作父母。基因组选择的缺点是参考群体需要具有足够的大小以能够估计基因型和表型之间的准确关联。还需要定期更新(=需要添加新动物),因为SNP和确定表型的基因之间的估计关联可能由于重组和/或突变而丢失。
基因组选择涉及利用非常多的估计关联
SNP和表型估计没有表型的动物的繁殖价值,
但输入SNP的。
这在以下情况下特别有用:
1.测量非常困难或昂贵的表型
2.你想在他们可以之前估计非常年幼的动物的繁殖价值
产生表型
3.性别有限的特征
在概述中,您已经看到有几种方法可以对动物进行排名。 一般目标
动物繁殖是为了尽可能地对动物进行排名。 用于对动物进行排名的工具是
估计育种值。 育种值的估计越精确越好
可以预期随后育种的结果。 我们现在将研究三种方法
估计概述中更详细描述的育种值。




http://www.doc88.com/p-7939538682321.html
图1:一组表型优势与遗传优势之间的关系
动物。 回归线表示P和G之间的估计关系。结果
在EBV中。 对于一些动物来说,这种EBV反映了它们真正的繁殖价值(G)
其他,由动物的数据点和回归线之间的距离表示。
动物的真实育种值(TBV)代表了该动物的遗传潜力:动物繁殖的真正价值是什么,The perfect EBV would be equal the TBV.
但首先我们需要知道估计的育种值究竟是什么。我们如何从关于动物表型和它们的遗传关系(谱系)的信息中获得对动物繁殖价值的估计?在动物育种中,我们使用回归原理来实现这一目标。在图1中,您可以看到这个原理可视化。如果我们将y轴上的真实育种值与x轴上的表型优势相对应,那么我们可以通过数据点计算回归线。在现实生活中,遗憾的是,我们不能创造这样的情节,因为我们不知道真正的繁殖价值。相反,我们试图找到回归系数,结合表型优势,将最好地预测遗传优势或真正的育种值(TBV)。**估计育种值的艺术是基于找到获得最佳回归系数的方法。**这也立即突出了育种价值估计的一个关键点:它是一个线性回归系数,但具有相同表型优势的动物并不总是具有相同的遗传优势。对于一些动物,如图中用圆圈表示的动物,TBV与EBV非常不同,而对于其他动物,EBV将是真实育种值的完美估计。 EBV与TBV相似程度的部分差异是由于表型受环境影响很大的事实。因此,在找到最佳回归系数的同时,尝试使表型优势尽可能符合回归线也很重要。在本章的其余部分,我们将讨论处理这两个问题的一些选项:预测最佳回归系数,并使表型优势尽可能符合回归线
为了估计动物的育种值,我们试图找到最佳回归系数和最具信息性的表型信息,以便我们的EBV尽可能接近TBV。
EBV相对于普通动物表达,以简化遗传优良动物的鉴定。
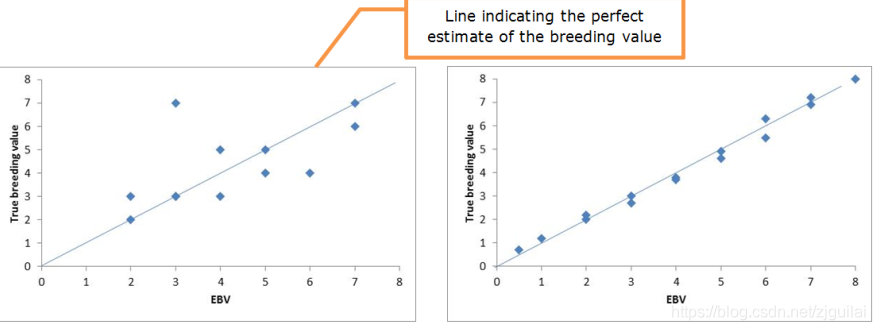
同样在高回归系数的情况下,仍有一些动物的EBV高于或低于TBV。如果我们能够以100%的准确度估计育种值,EBV和TBV将是相同的值。如果我们将TBV与EBV进行对比,那么所有数据点都将完全一致。数据点越少,EBV确实代表真正的育种值就越不确定:估计不准确。数据点在线的度量,以及育种值估计的准确性,是相关性。如果估计和真实育种值之间的相关性为1,那么您已设法创建完美的估计值。距离1越远(即它们形成云的越多),估计的育种值越不准确。如图3所示。在左侧,您可以看到一堆数据点:一些EBV类似于真正的育种值,但是一些估计值也偏离了真正的育种值。该图中EBV和TBV之间的相关性为0.76,EBV与所有动物的TBV不相似。例如,有两只动物的EBV为4,而它们的真实育种值是不同的:3和5.在现实生活中,我们不能产生如图所示的图,因为我们不知道真正的育种值。但我们能做的是估计估计育种值的准确性:表型信息与真实育种值之间的相关性。那么EBV与真正的育种价值一致多少。
Best Linear Unbiased Prediction
Genomic selection
从年轻公牛的EBV的例子可以清楚地看出,他的EBV的准确性将保持低水平,直到对年轻公牛的女儿进行表型观察。 这需要很多时间。 如果有一种方法可以在较年轻的时候提高EBV的准确性,而不必等待女儿出生,那将是非常有趣的。 如果有一种方法可以估算难以测量或昂贵的性状的育种值,例如一些与健康有关的性状或肉质,而不必感染动物,或进行详细的X射线或屠宰,这也将是非常有趣的。 他们。 几年以来,有一种方法可以做到这一点:基因组选择。
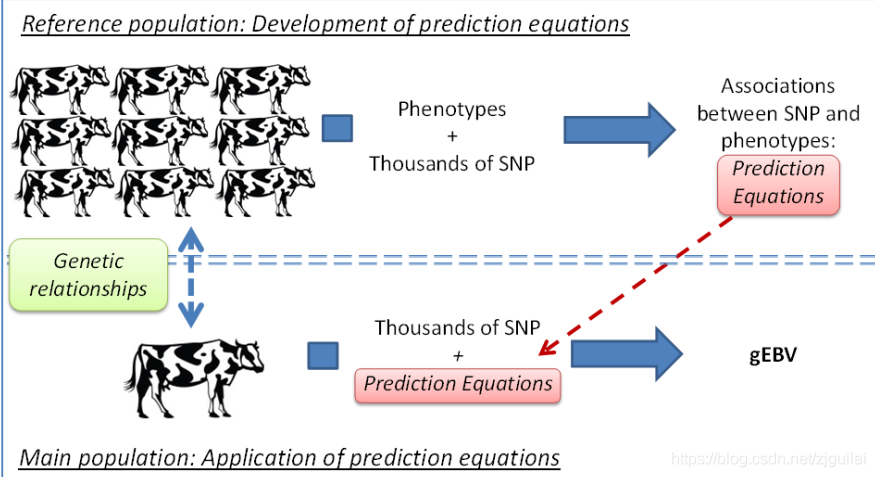
图7.基因组选择背后的物流示意图。 参考群体提供估计表型和SNP基因型之间关联的信息。 然后将这些关联翻译成预测方程,其用于估计没有表型但具有参考群体之外的SNP基因型的动物的基因组育种值。
通过基因组选择,可以非常准确地估计动物的繁殖价值,而无需自己的表现或大量后代的表现。 基因组选择基于对选择的一组动物的非常密集的遗传标记(SNP)和表型之间的详细关联的估计。 然后可以使用这些关联来预测具有的相关动物的所谓基因组育种值(gEBV)
已经对大量SNP进行了基因分型,但是没有准确的EBV的“传统”信息,如自身表现或大量具有表型的后代。 通过基因组选择,动物的DNA因此提供了用于估计育种值的信息,而无需收集动物本身或其近亲的表型。
Principle of genomic selection
在图7中,说明了基因组选择的一般原理。首先,需要在选定的一组动物上收集大量信息:参考人群。对该参考群体中的所有动物进行基因分型以获得非常大量的SNP,其在整个基因组中很好地分布。有多少,仍然存在争议,但至少有数千(例如60,000)。用于更多SNP的基因分型更昂贵,但也将导致更准确地估计SNP与表型之间的关联(即SNP效应)。关于参考人群中最佳动物数量的争论仍然存在争议。较大的种群显然更昂贵,因为这些动物的表型分析和详细的基因分型是昂贵的。但是更大的群体也允许更准确地估计SNP效应。与动物育种的许多方面一样,参考群体的大小和SNP的数量的选择将是成本 - 效益分析的问题。
鉴于参考群体的表型和基因型,将估计每种遗传标记的基因型和表型之间的关联。 随后,估计的效果被组合成所谓的预测方程。 这些只是第一个SNP的影响的总和(估计的SNP效应是加性的!)+第二个SNP的影响+ … +最后一个SNP的影响,因此最终结果是所有估计的SNP效应的总和。 因为每个SNP具有2个等位基因,对于每个SNP,存在3种可能的基因型。 建立预测方程,使得对于每个SNP,估计参考群体中存在的所有基因型的影响。 这是您需要大量参考人群的原因之一:准确估计所有这些SNP效应,每个基因型都需要由足够多的动物代表。 现在我们有一组具有估计SNP效应的方程。 现在可以通过将这些方程应用于它们的SNP基因型来估计参考群体外的动物的育种值。 基于基因组信息的这些育种值仅称为基因组育种值或gEBV。
基因组选择基于对一组非常密集的遗传标记(SNP)与选择的一组动物的表型之间的详细关联的估计:参考群体。
然后将得到的预测方程应用于其余群体的SNP基因型以估计它们的基因组育种值(gEBV),而不需要额外的表型。
详情传送门:链接:https://pan.baidu.com/s/136c1xFjFEi5Ved7AuAWSsg
提取码:ri9f

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









