







1 什么是SVM
在样本空间中,划分超平面可通过如下线性方程来描述:
WTx+b=0
其中 w=(w1;wd;...;wd) 为法向量,决定了超平面的方向;b为位移项(一个数,不是向量),决定了超平面与原点之间的距离。
离超平面最近的几个正、负样本点,就称为超平面的支持向量(support vector)。
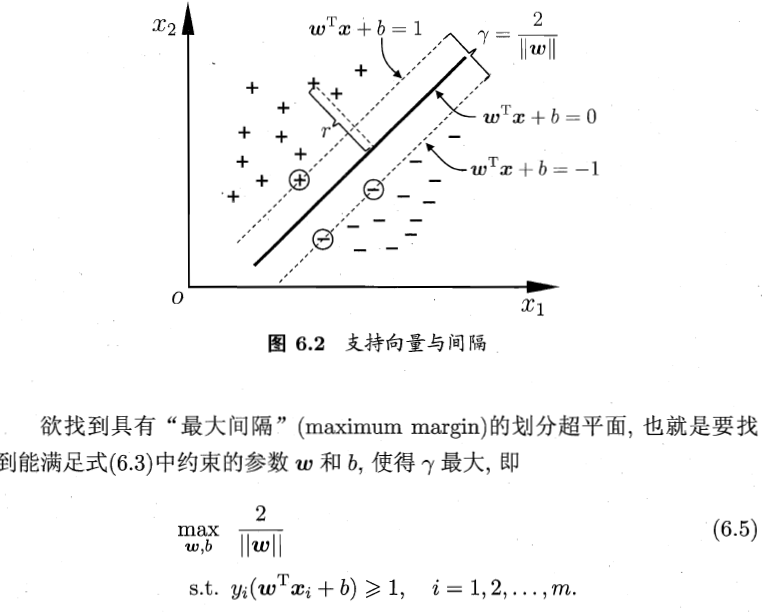
其中m为训练样本数。
2 对偶问题

注:
有不等式约束的优化问题,可以写为:
min f(x),
s.t. g_i(x) <= 0; i =1, ..., n
h_j(x) = 0; j =1, ..., m
对于这类的优化问题,常常使用的方法就是KKT条件。同样地,我们把所有的等式、不等式约束与f(x)写为一个式子,也叫拉格朗日函数,系数也称拉格朗日乘子,通过一些条件,可以求出最优值的必要条件,这个条件称为KKT条件。
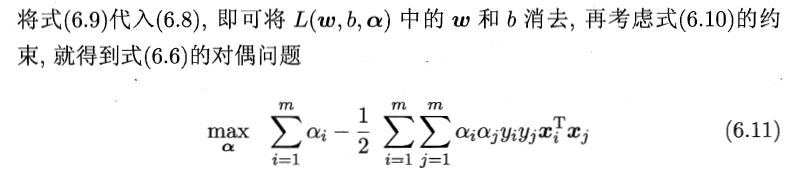






3 核函数
主要是用于解决,低维到高维空间映射后,计算难度大问题。通过核函数,计算两向量的内积,即可得到所对应的高维空间的两向量乘积。具体数学证明略。


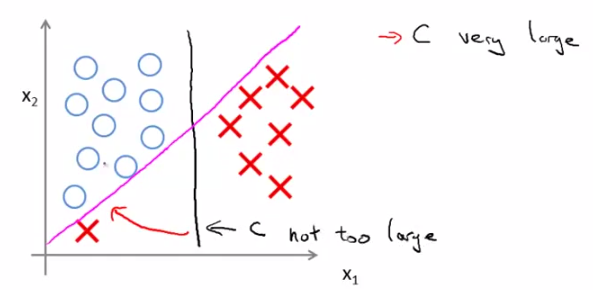
线性核划分场景
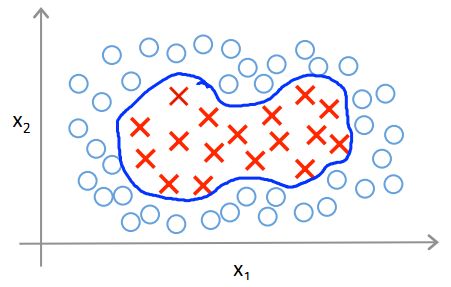
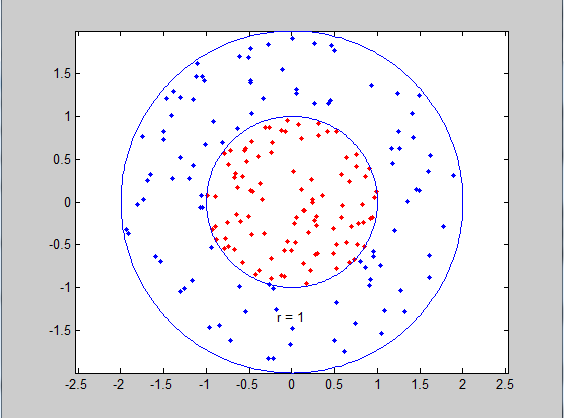
高斯核划分场景
高斯核又称为RBF核(radial basis function高斯函数是径向基函数中的一种)
3.1 小知识
3.1.1 径向基函数
A radial basis function (RBF) is a real-valued function whose value depends only on the distance from the origin, so that
ϕ(x)=ϕ(∥x∥)
or alternatively on the distance from some other point c, called a center, so that
ϕ(x,c)=ϕ(∥x−c∥)
. Any function
ϕ
that satisfies the property
Commonly used types of radial basis functions include (writing
r=∥x−xi∥
):

mllib上的SVM核心算法
//训练
def train(data: RDD[(Double, Vector)], stepSize: Double, numIterations: Int,
regParam: Double, miniBatchFraction: Double, initialWeights: Vector,convergenceTol: Double):
(Vector, Array[Double]) = {
var previousWeights: Option[Vector] = None
var currentWeights: Option[Vector] = None
var weights: Vector = initialWeights
var regVal = updater.compute(weights, Vectors.zeros(weights.size), 0, 1, regParam)._2
var converged = false // indicates whether converged based on convergenceTol
var i = 1
while (!converged && i <= numIterations) {
val bcWeights = data.context.broadcast(weights)
// Sample a subset (fraction miniBatchFraction) of the total data
// compute and sum up the subgradients on this subset (this is one map-reduce)
val (gradientSum, lossSum, miniBatchSize) = data.sample(false, miniBatchFraction, 42 + i)
.treeAggregate((BDV.zeros[Double](n), 0.0, 0L))(
seqOp = (c, v) => {
// c: (grad, loss, count), v: (label, features)
val l = gradient.compute(v._2, v._1, bcWeights.value, Vectors.fromBreeze(c._1))
(c._1, c._2 + l, c._3 + 1) //svm的gradient.compute
},
combOp = (c1, c2) => {
// c: (grad, loss, count)
(c1._1 += c2._1, c1._2 + c2._2, c1._3 + c2._3)
})
val update = updater.compute(//svm的更新器
weights, Vectors.fromBreeze(gradientSum / miniBatchSize.toDouble),
stepSize, i, regParam)
weights = update._1
regVal = update._2 //regVal is the regularization value
previousWeights = currentWeights
currentWeights = Some(weights)
converged = isConverged(previousWeights.get, currentWeights.get, convergenceTol)
i += 1
}
weights
}
//svm的hinge loss计算梯度
override def gradient_compute(data: Vector, label: Double, weights: Vector): (Vector, Double) = {
val dotProduct = dot(data, weights)
// Our loss function with {0, 1} labels is max(0, 1 - (2y - 1) (f_w(x)))
// Therefore the gradient is -(2y - 1)*x
val labelScaled = 2 * label - 1.0
if (1.0 > labelScaled * dotProduct) {
val gradient = data.copy
scal(-labelScaled, gradient)
(gradient, 1.0 - labelScaled * dotProduct)
} else {
(Vectors.sparse(weights.size, Array.empty, Array.empty), 0.0)
}
}
//svm的SquaredL2Updater更新器
override def updater_compute(
weightsOld: Vector,
gradient: Vector,
stepSize: Double,
iter: Int,
regParam: Double): (Vector, Double) = {
// add up both updates from the gradient of the loss (= step) as well as
// the gradient of the regularizer (= regParam * weightsOld)
// w' = w - thisIterStepSize * (gradient + regParam * w)
// 即w' = (1 - thisIterStepSize * regParam) * w - thisIterStepSize * gradient
val thisIterStepSize = stepSize / math.sqrt(iter)
val brzWeights: BV[Double] = weightsOld.toBreeze.toDenseVector
brzWeights :*= (1.0 - thisIterStepSize * regParam)
brzAxpy(-thisIterStepSize, gradient.toBreeze, brzWeights)
val norm = brzNorm(brzWeights, 2.0)
(Vectors.fromBreeze(brzWeights), 0.5 * regParam * norm * norm)
}
//预测
//intercept:截距
def predictPoint(
dataMatrix: Vector,
weightMatrix: Vector,
intercept: Double) = {
val margin = weightMatrix.asBreeze.dot(dataMatrix.asBreeze) + intercept
threshold match {//threshold默认为0.0
case Some(t) => if (margin > t) 1.0 else 0.0
case None => margin
}
}














 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









