







Logistic回归
1 Logistic回归模型公式推导

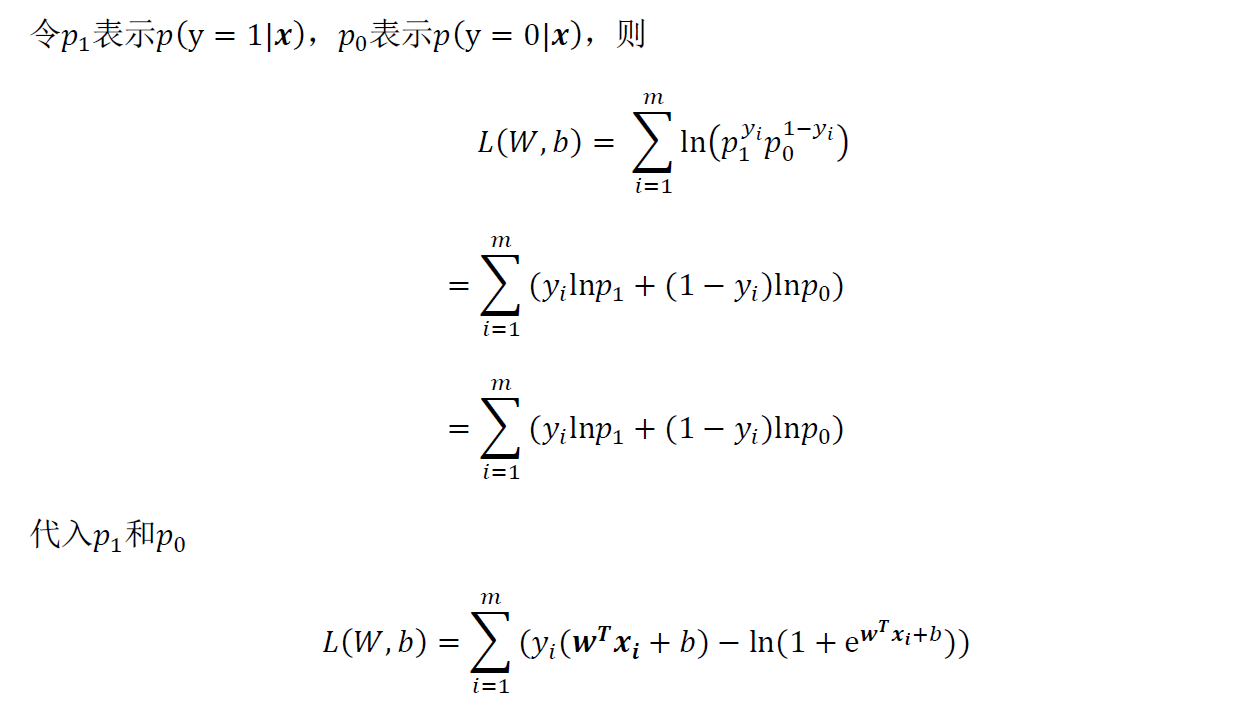




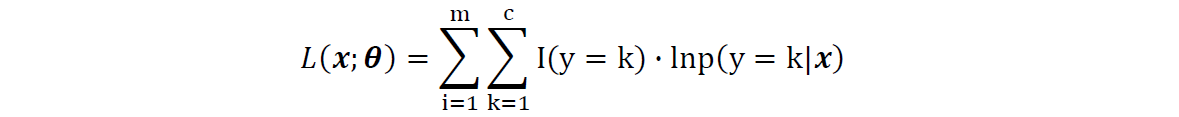
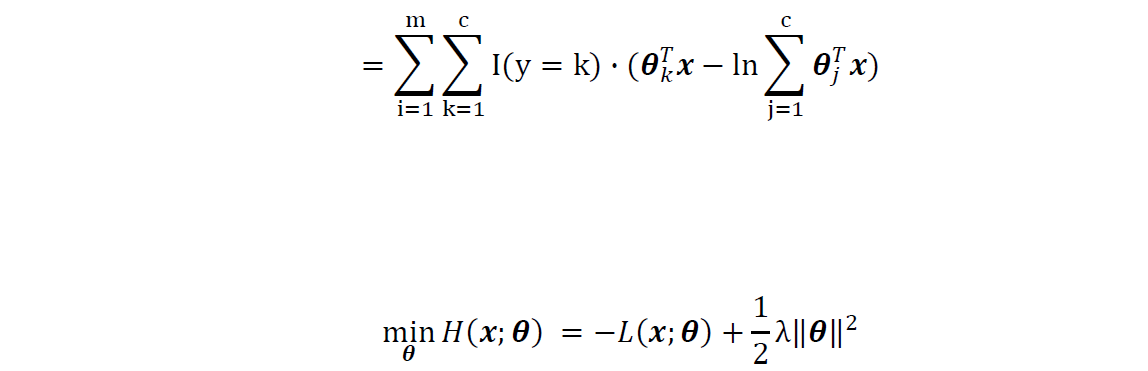
2 Spark logistic pseudo
//训练
def train(data: RDD[(Double, Vector)], stepSize: Double, numIterations: Int,
regParam: Double, miniBatchFraction: Double, initialWeights: Vector,convergenceTol: Double):
(Vector, Array[Double]) = {
var previousWeights: Option[Vector] = None
var currentWeights: Option[Vector] = None
var weights: Vector = initialWeights
var regVal = updater.compute(weights, Vectors.zeros(weights.size), 0, 1, regParam)._2
var converged = false // indicates whether converged based on convergenceTol
var i = 1
while (!converged && i <= numIterations) {
val bcWeights = data.context.broadcast(weights)
// Sample a subset (fraction miniBatchFraction) of the total data
// compute and sum up the subgradients on this subset (this is one map-reduce)
val (gradientSum, lossSum, miniBatchSize) = data.sample(false, miniBatchFraction, 42 + i)
.treeAggregate((BDV.zeros[Double](n), 0.0, 0L))(
seqOp = (c, v) => {
// c: (grad, loss, count), v: (label, features)
val l = gradient.compute(v._2, v._1, bcWeights.value, Vectors.fromBreeze(c._1))
(c._1, c._2 + l, c._3 + 1)
},
combOp = (c1, c2) => {
// c: (grad, loss, count)
(c1._1 += c2._1, c1._2 + c2._2, c1._3 + c2._3)
})
val update = updater.compute(
weights, Vectors.fromBreeze(gradientSum / miniBatchSize.toDouble),
stepSize, i, regParam)
weights = update._1
regVal = update._2 //regVal is the regularization value
previousWeights = currentWeights
currentWeights = Some(weights)
converged = isConverged(previousWeights.get, currentWeights.get, convergenceTol)
i += 1
}
weights
}
def gradient.compute(
data: Vector,
label: Double,
weights: Vector,
cumGradient: Vector): Double = {
/**
* For Binary Logistic Regression.
*
* Although the loss and gradient calculation for multinomial one is more generalized,
* and multinomial one can also be used in binary case, we still implement a specialized
* binary version for performance reason.
*/
val margin = -1.0 * dot(data, weights)
val multiplier = (1.0 / (1.0 + math.exp(margin))) - label
axpy(multiplier, data, cumGradient)//y *= ax
if (label > 0) {
// The following is equivalent to log(1 + exp(margin)) but more numerically stable.
MLUtils.log1pExp(margin)
} else {
MLUtils.log1pExp(margin) - margin
}
}
//预测
//intercept:截距
def predictPoint(
dataMatrix: Vector,
weightMatrix: Vector,
intercept: Double) = {
require(dataMatrix.size == numFeatures)
val margin = dot(weightMatrix, dataMatrix) + intercept
val score = 1.0 / (1.0 + math.exp(-margin))
threshold match { //threshold: Option[Double] = Some(0.5)
case Some(t) => if (score > t) 1.0 else 0.0
case None => score
}
}















 2184
2184

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









