







 本文介绍了牛顿方法在机器学习中的应用,作为优化模型参数的高效工具,其收敛速度快。此外,阐述了广义线性模型的概念,包括伯努利分布、高斯分布和泊松分布,以及如何从广义线性模型导出线性回归和逻辑回归等模型。最后提到了SoftMax回归,作为逻辑回归的多分类推广。
本文介绍了牛顿方法在机器学习中的应用,作为优化模型参数的高效工具,其收敛速度快。此外,阐述了广义线性模型的概念,包括伯努利分布、高斯分布和泊松分布,以及如何从广义线性模型导出线性回归和逻辑回归等模型。最后提到了SoftMax回归,作为逻辑回归的多分类推广。
不知道为什么分享不了了,就算是这样,我也要常常把自己的思考写下来,就算没什么用,等到七老八十的时候,我还能回忆回忆,很好很好~
一、牛顿方法
要注意,牛顿方法并不是机器学习方法,而是机器学习模型寻找最优参数的方法,它只是一种工具,用来求取代价函数最优解的工具。基本上所有常见的优化方法都与牛顿方法有着或多或少的联系,都是牛顿法的亲戚,也正是因为这样,它们才具有令人满意的表现。而各种优化方法的本质差异在于每迭代一步的方向和步长选取,即下式中的α和p

中前面我们说过的梯度下降法,收敛速度慢,对于特征数目上千万的问题,表现不尽人意。但是牛顿法的收敛速度是二阶的,这意味着 如果第k次的误差是0.01,则第k+1次迭代误差将会变为0.0001,这样的收敛速度,还是很棒的吧~下面就简单介绍一下牛顿法的原理。
如果我们要求某一个高次函数与x轴的交点,在一次二次的时候我们还有求根公式可以解决,但高次就无法直接求交点了。如下图为某一函数f(x):
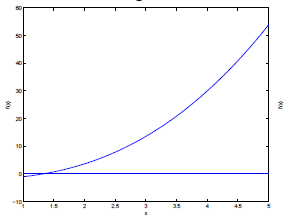
于是牛顿法就提出了一个关键性的思想:近似。尽管我们无法求得f(x)与x轴真实的交点,但我们能给出近似的解。如下图:
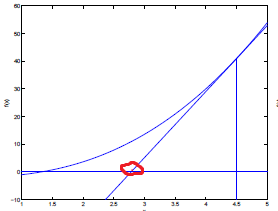
我们从点(4.5,0)开始,求这点的切线与x轴的交点如红色圈,将其作为函数与x轴交点更好的一个近似,再求这个点处切线与x轴交点作为一个更好的近似,如下图:
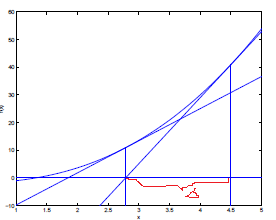
根据导数定义,△=f(x)/f'(x),所以参数的迭代公式为:
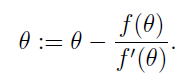
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2870
2870

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









